







- 参考书籍: 《Design Patterns: Elements of Reusable Object-Oriented Software》
-
- 设计模式中一句出现频率非常高的话是,“ 在不改动。。。。的情况下, 实现。。。。的扩展“ 。
- 对于设计模式的学习者来说,充分思考这句话其实非常重要, 因为这句往往只对框架/ 工具包的设计才有真正的意义。因为框架和工具包存在的意义,就是为了让其他的程序员予以利用, 进行功能的扩展,而这种功能的扩展必须以不需要改动框架和工具包中代码为前提
- 对于应用程序的编写者, 从理论上来说, 所有的应用层级代码至少都是处于可编辑范围内的, 如果不细加考量, 就盲目使用较为复杂的设计模式, 反而会得不偿失, 毕竟灵活性的获得, 也是有代价的。
创建者模式(Builder)
设计意图
- 将一个复杂对象的构建与展现分离, 使得同样的构建过程可以创造出不同的展现形式。
- 解析一个复杂的对象, 将其创建为多个目标中的一个。
- 举例: 考虑一个RTF(Rich Text Format) reader, 它可能会需要把一个RTF文档转换成无格式的 ASCII 文本, 也有可能会被转换成一个可交互的文本部件(Text Widget, 例如通过嵌入脚本实现的的可交互网页文字小部件)。 问题在于, 同一种文本有可能会被转换成无限数量的格式, 但是reader 只有一个。 所以应该实现在不需要改动reader 代码的情况下, 完成可转换格式的增添。
解决方案
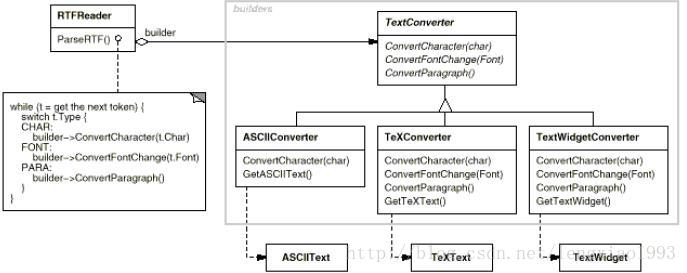
抽象过后的结果如下
图例说明
- 图片中的空心三角箭头,代表着继承(extends)或实现(Implement)关系, 由继承者/实现者 指向 被继承者/被继承者。
- 图片中的实心三角箭头且箭头末尾没有圆圈的, 代表着单一的引用关系, 但是被引用的对象也有可能被其他对象引用。
- 图片中的实心三角箭头且箭头末尾有圆圈的, 代表着一对多的引用关系。
- 图片中的虚线实心三角箭头, 代表着创建或者实例化的关系。
- 图片中的末端有圆圈的虚线是一个对方法体内容用伪代码说明的关系
- 思考:
- RTFReader 中持有一个TextConverter 对象的引用, 而TextConverter 有多种子类实现, 如果想要扩展可被转换的文本格式, 只要增加一个TextConverter 的实现类就完成了, 这好像只是一个通过继承来实现代码复用的情景, 为何会被单独列为一个创建者设计模式。
- 值得注意的是 ParseRTF()中的内容, 该方法的内容其实是RTF的解析算法, 在解析的过称中, 负责文本转换功能的TextConverter 被不断调用 。 在解析完成之后, TextConverter 也完成了整个文档的转换工作。
- 在parseRTF被执行完毕之后, 此时则可以调用TextConverter子类的GetXXXText() 方法.
- 注意: *TextConverter中并没有一个GetText 方法。 这说明RTFReader 中是无法调用GetXXXText()方法的。*
- 原因在于, 不同的Builder所产生的产品差别过大, 没有办法为不同的产品定义一个共同的父类和接口。 具体到图中的例子, 或许ASCIIText 和TeXText可以共同继承一个抽象父类或共同实现一个接口, 但是ASCIIText 和 TextWidet 就明显差别过大, 不可能有一个共同的接口或父类。
- 实际上, 这些产品也没有必要拥有一个共同的父类, 以期TextConverter中能够定义一个公共的返回值。原因在于客户端代码(这里的客户端是指使用RTFReader的代码)会负责将TextConverter实例化为特定类别的转换器对象。 最终的GetXXXX操作也是客户端完成调用的。 具体过程如下
- 由上图可以看出, client 代码是负责实例化ASCIITextConverter对象的, 因此client 持有的引用并不是TextConverter类型, 所以也可以直接调用GetASCIIText获取返回结果。
- ASCIITextConverter 中仅仅实现了convertCharacter()方法, 而parseRTF中同样还会调用 convertParagraph(), convertFontChange() 方法。 ASCIITextConverter会直接忽略这两种转换请求, 什么操作也不进行。
- RTFReader 中持有一个TextConverter 对象的引用, 而TextConverter 有多种子类实现, 如果想要扩展可被转换的文本格式, 只要增加一个TextConverter 的实现类就完成了, 这好像只是一个通过继承来实现代码复用的情景, 为何会被单独列为一个创建者设计模式。

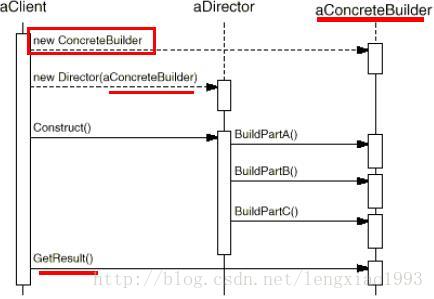
创建者模式中的Builder
- 创建者模式中, builder是一个共用的接口或者父类, 其中包含了buildPart1, buildPart2, buildPart3 的方法。 这就强制了最终生成的产品, 其整体结构是完全一致的(即使不一致,也只能是一个子集关系)
创建者模式中的Director
- 创建者模式中, Director 也是一个共用的类, Director中的construct 方法决定了buildPartX() 的执行次序和执行逻辑。 同样,这个逻辑必须足够泛化, 对于潜在的无限产品类型是通用的。
创建者模式与工厂类模式(抽象工厂、 工厂方法)的区别
和工厂方法模式里对象被一气呵成创建的方式(直接调用create方法) 不同, 创建者模式构建对象的过程是在Director的控制下一步一步进行的, 有了director 的参与, 可以保证产品只有在必要的构建步骤全部执行以后, 才能通过GetProduct 方法取得。 因此builder 的接口,比其他的创建型模式都更能反应产品的构建过程(分几个步骤构建, 有哪些大的部件), 这样就可以实现对产品创建过程更加细粒度的控制。
抽象工厂模式与创建者模式在结构上看起来会很相似, Builder 中的接口定义了buildPart1, buildPart2, buildPart3。 AbstractFactory 中定义了createProductA, createProductB, createProductC。 然后都由不同的子类去重写这些方法。 但他们的实际区别是:
- 抽象工厂方法关注的是产品系列的创造, 目的在于保证不同系列的产品之间不会被混用。 同时, 每个系列都产生的产品类型都是完整而全面的。
- 创建者模式关注的是是一个复杂产品的分步骤创造, 目的在于在不改动产品的构建过程(分几个步骤构建, 有哪些部件)的情况下, 实现创建的产品类型的扩展。
- 抽象工厂中最终输出的是一个系列的多个产品。
- 创建者模式最终输出的是一个由多个零部件组装成的复杂的单个产品
创建者模式分析
- 回顾创建者模式的设计动机: 将一个复杂对象的构建与展现分离, 使得同样的构建过程可以创造出不同的展现形式
- 其实这句话对应到GOF书中的例子上来, 总觉得有点不合适。 创建者模式与其说分离了构建与展现, 倒不如说分离了创建流程与零部件的制造 ,可以在不改变创建流程的情况下, 完成新的一套零部件的扩展。
- 值得思考的是, 创建者模式与工厂方法模式相比, 真正的好处是什么?
- GOF书中提到的是对创建流程可以实现更细粒度的控制, 但实际上工厂方法中的创建流程也是可以随意控制的,而且相比创建者模式, 更加灵活, 毕竟不同的产品之间不需要共享同一个创建流程, 也不需要把不同产品, 都划分出统一的部件。
- 所以归根结底, 创建者模式的使用至少需要满足以下3个条件:
- 一个产品的构建流程比较复杂,但是该流程对于同一个产品的不同类型来说是可以通用的 ,因此会希望这个构建流程可以被复用
- 例如将一个RTF 文档构建成 TeX文本或ASCIIText 的文本都是依次对RTF每一个标识符依次进行识别, 完成文本逻辑层面【单个文字, 段落, 字体】的相应转换)。 且RTF的解析流程是比较复杂的, 这个流程我们希望可以复用。
- 一个产品可以被划分为多个部件, 这些部件的粒度, 对于不同类型的产品也是通用的
- 不同类型的文档都可以被划分为单个文字,段落的部分)。
- 一个产品存在被不断扩展类型的“刚性需求“, 且在这个过程中, 我们不希望修改创建的流程。
- 这个要求最为微妙, 也最容易被人们忽略,造成模式的误用。 注意到RTFReader的例子中, 我们不想修改RTFReader , 而完成对可转换文本类型的扩展。 其原因除了想复用Reader 的流程以外, 更为重要的一个原因是, RTFReader 这种代码, 往往是作为工具包类库,或者框架的一部分发布给程序员使用的, 所以工具包需要支持在不被改动的情况下, 让程序员通过继承或实现接口的方式来完成定制化格式文本的扩展。
- 一个产品的构建流程比较复杂,但是该流程对于同一个产品的不同类型来说是可以通用的 ,因此会希望这个构建流程可以被复用















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









