






一、Hashset是什么
- 在java中集合分为Collection集合(单列集合)和Map集合(双列集合)
- Hashset集合是set接口的一个实现类,set接口也继承自顶级父类Collection接口,所以HashSet可以拥有Collection中共有的方法
- set接口的特点:无序,无下标,元素不重复。
- HashSet定义:此类实现Set接口,底层由哈希表(实际为HashMap实例)支持。对set的迭代次序不作保证。特别是,该类允许null元素。
二、 HashSet实现元素不重复的原理
1、HashSet底层
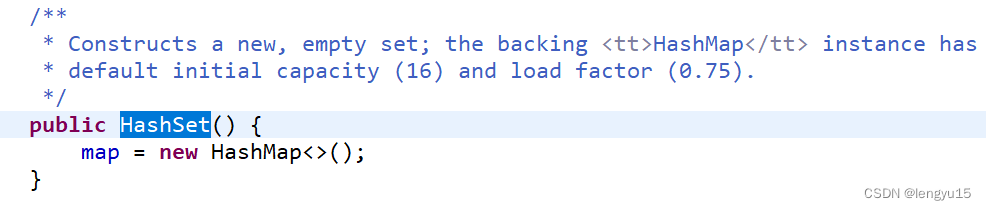
可以看出其底层继承了HashMap,是哈希表。
2、HashSet的重复数据
创建一个Student类,将其作为对象放入HashSet集合中
public class Student {
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
创建一个测试类测试,添加重复数据
public class Test {
public static void main(String[] args) {
//创建一个HashSet集合,存放Student对象
HashSet<Student> hset=new HashSet<Student>();
//创建三个Student具体实现
Student stu1=new Student("张三", 21);
Student stu2=new Student("张三", 21);
Student stu3=new Student("李四", 28);
//将上述三个对象放入HashSet集合中
hset.add(stu1);
boolean b1=hset.add(stu2);//插入重复对象(地址不同,但内容相同),允许插入
hset.add(stu3);
boolean b2=hset.add(stu1);//插入重复对象(地址相同),不允许插入
//使用增强for循环,输出HashSet中元素
for (Student student : hset) {
System.out.println(student);
}
//观察两个重复数据的添加进HashSet集合的情况
System.out.println("插入重复对象(地址不同,内容相同)"+b1);
System.out.println("插入重复对象(地址相同)"+b2);
}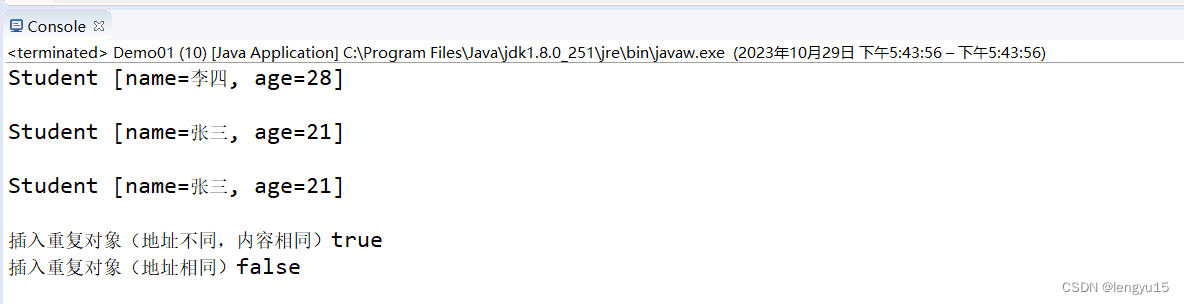
- 从上述结果可以看到,我们添加了两类重复数据,一个成功一个失败。我们认为的添加进去的两个张三对象内容相同,其也应为重复数据,不应该添加进HashSet集合中。按照HashSet所继承的Ste接口的特点来说应该是无序,不重复。那么为什么重复的元素张三被添加进去了。
- 这与编译器识别重复数据的方法有关,怎样去让编译器去识别内容相同的对象的,这需要我们在Student类中重写equals()方法,来比较对象属性值的异同。若equals()返回true则是重复数据,反之则不是。
在Student类中可以直接生成equals()方法也可以自己定义,然后再次运行测试类
//自定义重写equal()方法
@Override
public boolean equals(Object obj) {
if(this==obj) {
return true;
}
if(obj==null || this.getClass() != obj.getClass()) {
return false;
}
//向下转型
Student stu=(Student) obj;
return Objects.equals(name, stu.name) &&
Objects.equals(age, stu.age);
}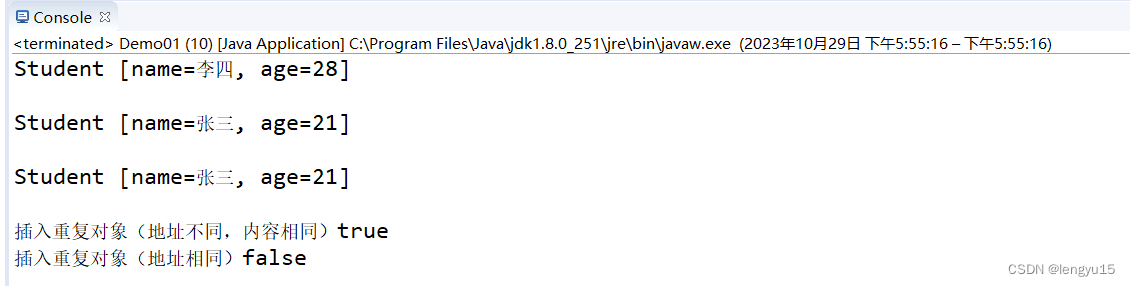
我们会惊讶的发现和我们预期的结果不一样,我们重写的equals()方法没有起到效果。那么是因为什么呢?
其实是为了节省内存空间,节省资源,此时虽然用户写了覆盖eauals()方法,但是程序编译器认为没有必要使用。就是——“可以用,但没必要”。
原因很简单,如果每一次都调用equals(),插入5个对象将会调用多少次呢?(设比较的总次数为n)
插入对象1,需要比较0次(n=0);
插入对象2,需要比较1次(n=1);
插入对象3,需要比较2次(n=3);
插入对象4,需要比较3次(n=6);
插入对象5,需要比较4次(n=10);
仅仅插入5个对象就需要使用equals()方法10次,大大降低了程序的效率,显然编译程序就没有调用该方法。从此也可以看出equals()方法是有使用条件的,这个条件就是HashCode()编码值。只有当HashCode()方法返回的值相同(即地址相同),才去调用equals()方法进行比较内容。
这也就证明了,为什么我们单独使用equals();没有达到预期的去重效果了。
因此,为了满足地址不同、内容相同的对象也可以被查重,我们需要去人为的干预一下,干预的方法就是让地址不同、内容相同(属性相同)的对象拥有一致的HashCode,以便于我们去用equals()方法比较其内容异同。所以我们可以自定义HashCode()方法去覆盖的父类的HashCode()方法,怎么定义呢?当然,随意定义显然不合理,需要结合对象的各个属性的HashCode做结合,即为整个对象的HashCode;
重写HashCode()方法,再次运行测试类
// 自定义重写HashCode()方法
public int hashCode() {
return Objects.hash(name,age);
} 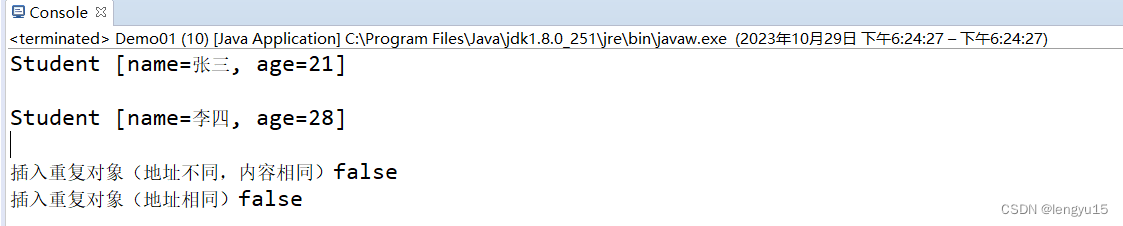
可以发现此时,HashSet集合中只有一个张三对象。
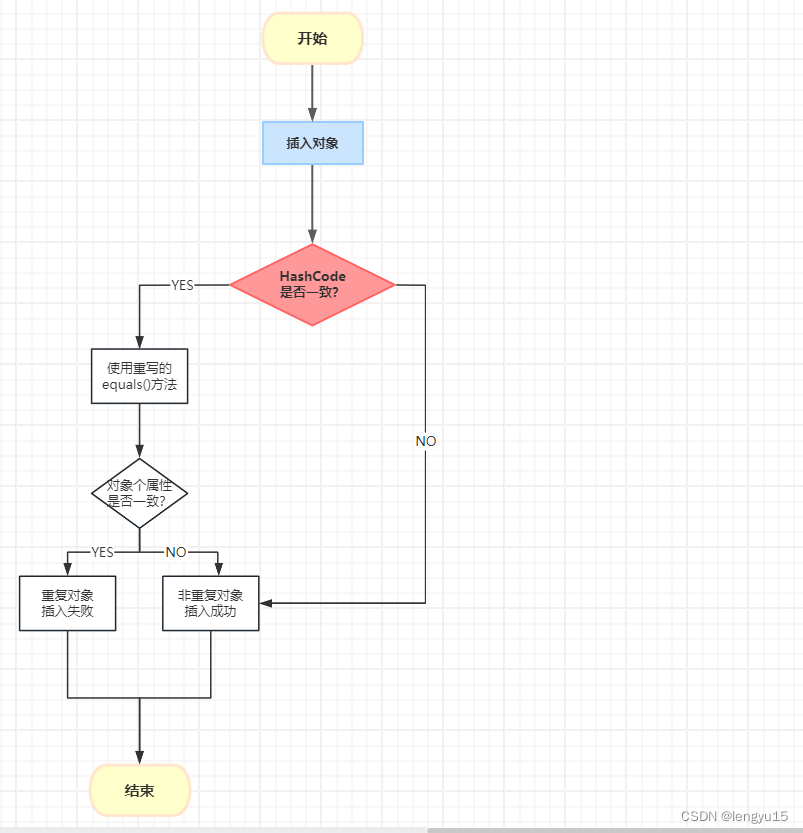
3、HashSet是如何识别重复元素的
1.当我们的HashSet调用add()方法去存储对象的时候,是先调用对象的HashCode()得到一个哈希值,然后在集合中找是否有哈希值相同的对象。
- 如果没有哈希值相同的对象就直接加入到集合当中不用再经过equals()方法进行对比
- 如果哈希值相同的对象的话,就进一步用equals()方法比对去重
2.将我们自定义的对象存入set集合当中时:
- 类中必须重写equals()和HashSet()这两个方法(必须同时重写,不能只单独重写其中一个,没有效果)
- HashCode():属性相同的对象返回值必须是相同的,属性不相同的对象返回值一定不同
- equals():属性相同就返回true,属性不同就返回false;(此方法是判断是否为同一个对象的最后审判)
三、小结
1、具体流程图
2、小结
- HashSet基于HashCode来实现元素的不可重复
- 当存入元素的HashCode相同时,会调用equals()进行确认,结果为true,则拒绝存入
希望各位看官,点赞支持哦~















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









