







最小生成树
在前面我们了解到了无向图和加权有向图,类似的我们给无向图的每一条边加上权重,就得到了加权无向图,加权无向图在现实中也有许多应用,在这一篇,我们讨论对它的一个重要的处理,就是找出图中(本篇中默认为加权无向图)的最小生成树。
最小生成树:图的生成树是它的一棵含有所有顶点的无环连通子图。加权图的最小生成树(MST)是它的一棵权值之和最小的生成树
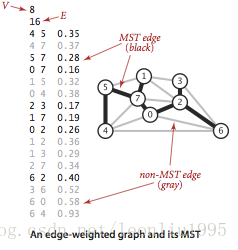
默认权值是不相同的,否则会产生不唯一的最小生成树
最小生成树算法有很多应用,比如顶点是城市,边是城市之间的航线,那么最小生成树可以看作覆盖这些城市做需要的最短总航线,下面我们先来看基本的实现原理。
贪心算法
首先我们先来介绍一个概念切分:切分就是将图的所有顶点分为两个非空且不重叠的两个集合,横切边是一条连接两个属于不同集合顶点的边
切分定理:在一副加权图中,给定任意切分,它的横切边中权重最小的必然位于最小生成树中
贪心算法是所有最小生成树算法的基础,基本原理就是从一个点开始,以已经找到的最小生成树的顶点,和其他顶点作为一个切分,找出权重最小的横切边,加入最小生成树,不断进行下去,直到包含了所有顶点。
基本数据结构
同样,对新的数据结构也要进行实现,不一样的是为了方便对边的操作,这里增加了边的对象
public class Edge implements Comparable<Edge>{
private final int v;
private final int w;
private final double weight;
public Edge(int v, int w, double weight){
this.v = v;
this.w = w;
this.weight = weight;//边的权重
}
public double weight(){
return weight;
}
public int either(){
return v;
}
public int other(int vertex){//返回另一个顶点
if (vertex == v) return w;
else if (vertex == w) return v;
else throw new RuntimeException("Inconsistent edge");
}
public int compareTo(Edge that){//边是可以按照权重大小比较的
if (this.weight<that.weight) return -1;
else if (this.weight>that.weight) return +1;
else return 0;
}
public String toString(){
return String.format("%d-%d %.2f", v,w,weight);
}
}然后才是加权无向图的实现
public class EdgeWeightedGraph {
private final int V;
private int E;
private Bag<Edge>[] adj;
public EdgeWeightedGraph(int V){
this.V = V;
this.E = 0;
adj = (Bag<Edge>[]) new Bag[V];
for(int v = 0; v<V;v++){
adj[v] = new Bag<Edge>();
}
}
public EdgeWeightedGraph(In in){
this(in.readInt());
int E = in.readInt();
for(int i=0;i<E;i++){
int v = in.readInt();
int w = in.readInt();
Double weight = in.readDouble();
Edge e = new Edge(v, w, weight);
addEdge(e);
}
}
public int V(){return V;}
public int E(){return E;}
public void addEdge(Edge e){
int v = e.either();
int w = e.other(v);
adj[v].add(e);
adj[w].add(e);
E++;
}
public Iterable<Edge> adj(int v){
return adj[v];
}
public Iterable<Edge> edges(){
Bag<Edge> bag = new Bag<Edge>();
for(int v=0;v<V;v++)
for (Edge e:adj[v])
if(e.other(v)>v) bag.add(e);
return bag;
}
}值得注意的一点是,因为是无向图,所以添加的时候要在两个端点的Bag里面都要添加,但是因为添加的是Edge对象的引用,所以所有的Edge对象只存了一份。
Prim 算法
这里介绍的Prim算法和下面将要介绍的Kruskal算法基本原理都是上面说的贪心算法,可以发现算法实现的关键就是找出横切边。这两个算法被发现的年代都很早,我不知道最开始是具体怎么实现的,但是在《算法4》中,作者都使用的是最小优先队列,这个在我前面的博客《算法4》优先队列和堆排序中有过介绍,但是在Prim算法的即时版本中使用的是索引优先队列,具体的这种数据结构放在稍后介绍,主要功能是差不多的,在第一个位置能够得到最小的键值的索引,不过先来看Prim算法的具体实现原理。
这里只介绍书上的即时版本。代码中维护几个重要的数据结构:
edgeTo数组: 对于索引i,edgeTo[i]表示对于顶点i,将其链接到最小生成树上的边。
distTo数组:distTo[w] = edgeTo[w].weight(),就是上面所说的对应的边的权重。
marked数组:顶点v在树中则为true
IndexMinPQ的索引优先队列:保存顶点值如w和它到树的所有边中权重的最小值,也是distTo[w]的值,这个值会变化,只要在树的生长过程中发现某个顶点v到w的边的权重比distTo[w]小,那么distTo[w]的值就会改成边v-w的权值,相应的edgeTo[w]也会改成边v-w。
下面是从教材上截取的一幅图:
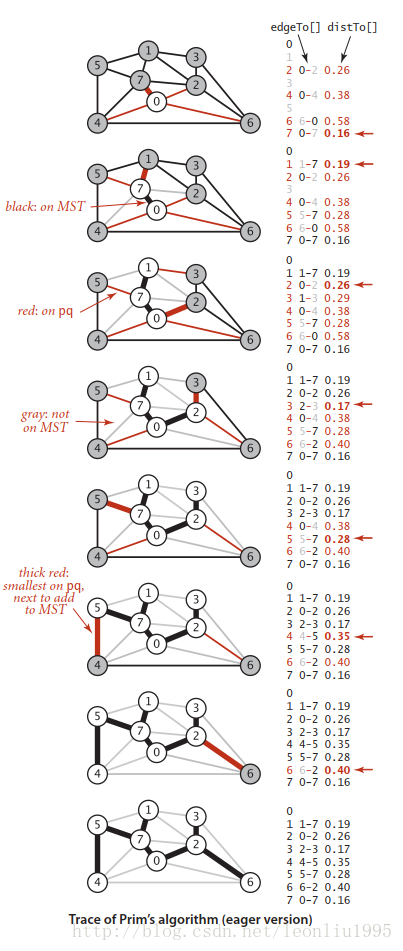
我们可以大致看下算法的运行过程,首先将0加入优先队列,之后将其弹出,插入和0相邻的顶点,图中左边显示了edgeTo[]和distTo[],红色的值代表当前阶段在优先队列中的边,也就是图示中细红色的边。再看第6步,原本是0-4这条边连接在生成树上的,但是当树生长到5节点的时候,发现5-4的权重更低,所以就更改了4连到树上的边。最后还有一点需要注意,树内的顶点是不能连接的,否则就会形成环,所以在生长的过程中不能连接marked[]为true的节点,下面是Prim算法的代码:
public class PrimMST {
private Edge[] edgeTo;
private double[] distTo;
private boolean[] marked;
private IndexMinPQ<Double> pq;//保存当前树的横切边
public PrimMST(EdgeWeightedGraph G){
edgeTo = new Edge[G.V()];
distTo = new double[G.V()];
marked = new boolean[G.V()];
for (int v = 0;v<G.V();v++)
distTo[v] =Double.POSITIVE_INFINITY;
pq = new IndexMinPQ<Double>(G.V());
distTo[0] = 0.0;
pq.insert(0, 0.0);
while(!pq.isEmpty())
visit(G, pq.delMin());//找到权重最小的横切边,和相应的顶点,然后再加入新的横切边
}
private void visit(EdgeWeightedGraph G, int v){
marked[v] =true;//将顶点v加入生成树
for (Edge e: G.adj(v)){//遍历v的所有边
int w = e.other(v);
if (marked[w]) continue;//另一个顶点如果在树中就不加入
if (e.weight()<distTo[w]){//发现更小权重的边就对数据结构更新
edgeTo[w] =e;
distTo[w] =e.weight();
if(pq.contains(w)) pq.change(w, distTo[w]);
else pq.insert(w, distTo[w]);
//优先队列中有的话就更新,没有的话就插入。
}
}
}
public Iterable<Edge> edges(){
Bag<Edge> mstBag = new Bag<Edge>();
for(int v=1;v<edgeTo.length;v++)
mstBag.add(edgeTo[v]);
return mstBag;
}
public double weight(){
double weight = 0;
for (int i=1;i<edgeTo.length;i++)
weight+=distTo[i];
return weight;
}
}
索引优先队列在本篇中不是重点,下面只给出代码实现,不做具体分析:
public class IndexMinPQ<Key extends Comparable<Key>> implements Iterable<Integer> {
private int N;
private int[] pq;
private int[] qp;
private Key[] keys;
private int maxN ;
public IndexMinPQ(int maxN){
this.maxN =maxN;
N=0;
keys = (Key[]) new Comparable[maxN+1];
pq =new int[maxN+1];
qp =new int[maxN+1];
for (int i=0;i<=maxN;i++) qp[i] = -1;
}
public boolean isEmpty(){
return N==0;
}
public boolean contains(int k){
return qp[k] !=-1;
}
public int size(){
return N;
}
private boolean greater(int i, int j){
return keys[pq[i]].compareTo(keys[pq[j]])>0;
}
private void exch (int i, int j){
int swap = pq[i];
pq[i] = pq[j];
pq[j] =swap;
qp[pq[i]] =i;
qp[pq[j]] =j;
}
public void insert(int k, Key key){
N++;
qp[k] =N;
pq[N] = k;
keys[k] =key;
swim(N);
}
public Key min(){
return keys[pq[1]];
}
private void swim(int k){
while(k>1 && greater(k/2, k)){
exch( k, k/2);
k = k/2;
}
}
private void sink(int k){
while(2*k<N){
int j=2*k;
if (j<=N && greater(j, j+1)) j++;
if (!greater(k, j)) break;
exch( k, j);
k=j;
}
}
public void change(int i, Key key){
keys[i] =key;
swim(qp[i]);
sink(qp[i]);
}
public int delMin(){
int min =pq[1];
exch(1, N--);
sink(1);
assert min == pq[N+1];
qp[min] = -1;
keys[min] = null;
pq[N+1] = -1;return min;
}
public void delete(int i){
int index = qp[i];
exch(index, N--);
swim(index);
sink(index);
keys[i] = null;
qp[i] = -i;
}
public Iterator<Integer> iterator() { return new HeapIterator(); }
private class HeapIterator implements Iterator<Integer> {
// create a new pq
private IndexMinPQ<Key> copy;
// add all elements to copy of heap
// takes linear time since already in heap order so no keys move
public HeapIterator() {
copy = new IndexMinPQ<Key>(pq.length - 1);
for (int i = 1; i <= N; i++)
copy.insert(pq[i], keys[pq[i]]);
}
public boolean hasNext() { return !copy.isEmpty(); }
public void remove() { throw new UnsupportedOperationException(); }
public Integer next() {
if (!hasNext()) throw new NoSuchElementException();
return copy.delMin();
}
}
}
Kruskal算法
Prim算法是从一个顶点开始不断地生长,Kruskal算法却不是这样,他的基本想法是,对所有边的权重进行排序,然后从小到大,不断地将最小的边加入优先队列,这里又用到了优先队列。到最后所有的边连在一起形成一整棵树的时候,算法就可以停止。但是要注意的是,即使我们得到了一个权重最小的边,也不一定能加入到树中,新加入的边不能让已有的边形成环,因为生成树肯定是没有环的。《算法4》中又使用了一种数据结构UnionFound,可以用来快速查找节点之间是否连通,本质上还是树,查找的时候从叶结点不断上溯到根节点,以根节点为连通分量的区分标志。具体的结构不再详述,感兴趣的可查找其他资料。
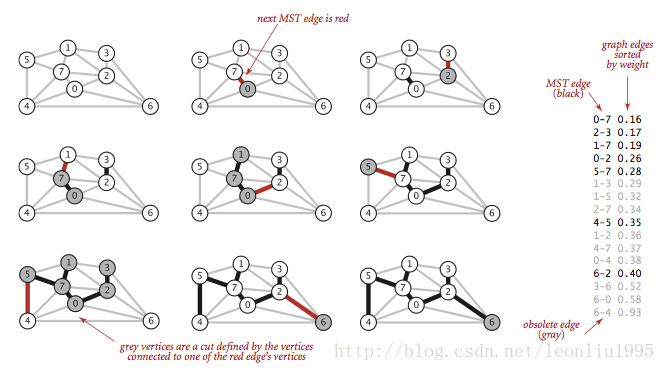
看着上面的图就会发现过程很好理解,右边是按照权重排序好的边,黑色的是插入树的边,灰色的是插入时会形成环的,所以没有插入的边,这样的边直接略过,最后只要总的边数达到V-1就行了。下面是代码示例:
public class KruskalMST {
private Queue<Edge> mst;
public KruskalMST(EdgeWeightedGraph G){
mst = new Queue<Edge>();
MinPQ<Edge> pq = new MinPQ<Edge>(G.E());
for(Edge e:G.edges())pq.insert(e);
WeightedQuickUnionUF uf =new WeightedQuickUnionUF(G.V());
while(!pq.isEmpty() && mst.size()<G.V()-1){
Edge edge= pq.delMin();
int v= edge.either(), w=edge.other(v);
if (uf.connected(v, w)) continue;
uf.union(v, w);
mst.enqueue(edge);
}
}
public Iterable<Edge> edges(){
return mst;
}
public double weight(){
double weight =0 ;
for (Edge e:mst)
weight+=e.weight();
return weight;
}
}
可以看出代码很短,当然也是因为用了比较高级的数据结构,算法本身其实也不复杂,下面是UnionFound的代码,以供参考:
public class WeightedQuickUnionUF {
private int[] id;
private int[] sz;
private int count;
public WeightedQuickUnionUF(int N){
count = N;
id =new int[N];
for(int i=0;i<N;i++) id[i] =i;
sz = new int[N];
for (int i=0;i<N;i++) sz[i] =i;
}
public int count(){return count;}
public boolean connected(int p, int q){
return find(p)==find(q);
}
public int find(int p){
while(p!=id[p]) p=id[p];
return p;
}
public void union(int p, int q){
int i = find(p);
int j = find(q);
if (i==j) return ;
if (sz[i]<sz[j]) {id[i] =j;sz[j]+=sz[i];}
else {id[j] = i; sz[i]+=sz[j];}
count--;
}
}
这里用的是一种加权的算法,可以有效地降低树的高度,增加查找的速度
总结
对于时间成本上面介绍的即使Prim算法的速度最坏情况下可以达到
ElogV
,因为它维护的是一个关于顶点的优先队列,所以一次最坏速度为
logV
,算法进行过程中需要V次插入,V次删除最小值,以及最坏情况下E次改变权重,而每次改变权重都需要重新使堆有序,也就是又一次
logV
,所以总共的最坏速度为
ElogV
对于Kruskal算法就要慢一些对于最坏情况下速度为
ElogE
,主要是因为它维护了一个所有边的优先队列,那每次对优先队列操作成本为
logV
,而最坏情况下需要遍历所有边才能够得到我们需要的V-1条,其他的UnionFound的操作因为是对顶点进行的,所以乘的是
logV
,量级上比较小,所以忽略。
综上,是最小生成树的两种常用算法。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









