






看完摘要习惯性先去看整体框架图,如下图,在卷积结构中看到了Batch Normalization,因此首先去了解了一下什么是Batch Normalization。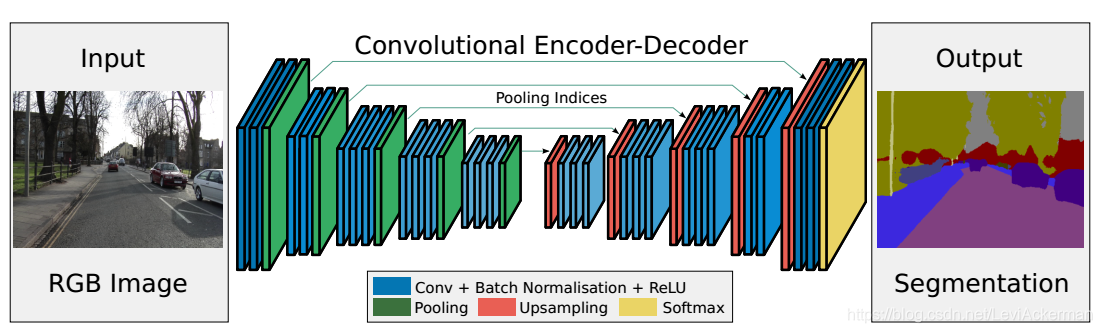
推荐博客:http://www.cnblogs.com/guoyaohua/p/8724433.html,看完后基本都懂了。在这里我简单总结一下:
BN的目的是解决“Internal Covariate Shift”问题,主要作用是防止梯度消失或爆炸,加快学习速度,用于卷积之后,激活函数之前。
Covariate Shift:输入数据X的分布总是在变,这与假设训练数据及测试数据满足独立同分布的假设不符合。
类似白化:
白化可以去除数据的冗余信息,通过白化可使得数据具有特征:1)特征之间相关性较低;2)所有特征具有相同的方差。
所谓的白化就是将图像像素值转化成零均值和单位方差的正态分布,均值为0,方差为1。(零均值化:当数据的均值过大时,可能会导致参数的梯度过大,而零均值并不会改变像素之间的差异,提取信息时通常也不关注像素值的高低,而是像素之间的相对色差。)
对输入层做白化操作可以使神经网络较快收敛,那对每一层做白化操作呢,BN就是通过一定的规范化手段,将每个隐层神经元逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布,强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
至于为什么要将图像转为均值为0方差为1的图像,可以参考上面的博客,这里不详细描述了。
将结构框图重新展示一下,本文作者所提的分割结构包含encoder network以及decoder network以及最后一层softmax进行像素级分类。encoder在拓扑结构上与VGG16的13层卷积层一致,而decoder 则是将低分辨率的feature map 映射到全输入分辨率,进行pixel-wise 的分类。本文重点就在于将低分辨率的featuremap上采样至输入尺寸的方式。具体来说,就是在encoder中的max-pooling 过程中,保存pooling indices ,在decoder中利用 pooling indices来实行非线性的上采样过程。
作者说这个ideal的灵感来自于无监督特征学习的结构设计。此外作者认为,使用CRF能够提升性能,是因为在核心前馈分割机制中没有较好的解码技术。
Encoder network 包含VGG16的13层卷积层,通过在大型数据集上进行分类的权重训练来初始化训练过程,每一个编码层都有一个相关的解码层,因此,解码层也有13层。每一个encoder都是首先利用滤波器进行卷积操作来生成一系列的feature map ,然后对这些feature map进行BN,再通过非线性ReLU。以上操作为卷积层(蓝色)的操作,接下来对卷积层输出进行最大池化层操作,池化模板大小为22,步长为2,输出结果相当于系数为2的下采样。Max-pooling使得输入图像的小空间位移上实现平移不变性。但却会产生空间信息的损失,对于分割中的边界细节非常不利,因此有必要在下采样之前获取并保存边界信息。
鉴于内存的限制,本文作者提出了一种高效的信息存储方法。该方法指仅保存每个pooling中最大值的feature的位置,即max-pooling indices,这样,原则上每个22的pooling window仅需要2bits。
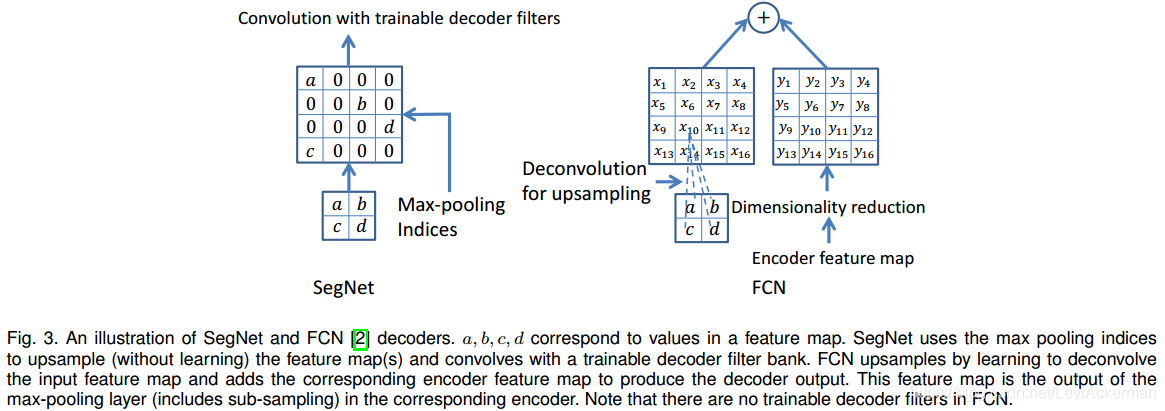
在decoder network中,每个decoder首先对利用记忆的max-pooling indices对输入的feature map进行上采样,这一步会产生一个稀疏的feature map,如上所示,然后再通过可训练的解码滤波器进行卷及操作,生成一个密集的feature map。后续进行BN。
这里注意的一点是,BN在encoder和decoder中得卷积操作中都要进行的,但是没有偏置biases,在decoder中也没有进行ReLU。在encoder和decoder中所有的卷积核大小都固定为7 * 7,且是使用的same卷积,卷积后不改变图片大小。采用这么大的卷积核是为了to provide a wide context for smooth labelling。比如在第四层的featuremap中的像素其感受野可以达到输入图像的106 * 106。
此外,作者说:注意,与第一个编码器对应的解码器(最靠近输入图像)产生一个多通道特征映射,尽管其编码器输入有3个通道(RGB)。这与网络中的其他解码器不同,其他解码器生成的特征映射具有与其编码器输入相同数量的大小和通道。因为最后一个要输出与类别相同数目的通道数。
最后输出的soft-max分类器是一个K通道的概率图像,K为类别数。每一个像素取其概率值最大的为分类类别。
【论文阅读】SegNet A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
最新推荐文章于 2023-04-08 16:22:38 发布















 2862
2862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









