







 本文详细介绍了MetaQA数据集,涵盖Vanilla、NTM文本和音频数据,知识库来自MovieQA的 Wikidata。研究了MetaQA上各类模型的性能,如KV-MemNN、VRN、GRAFT-Net等,并展示了从知识图谱到复杂问答的处理方法。
本文详细介绍了MetaQA数据集,涵盖Vanilla、NTM文本和音频数据,知识库来自MovieQA的 Wikidata。研究了MetaQA上各类模型的性能,如KV-MemNN、VRN、GRAFT-Net等,并展示了从知识图谱到复杂问答的处理方法。
目录
1. 论文相关
MetaQA [Zhang et al., 2018]
源自论文:Variational reasoning for question answering with knowledge graph
数据集:https://github.com/yuyuz/MetaQA(也可以直接点击下边链接下载数据集:https://drive.google.com/drive/folders/0B-36Uca2AvwhTWVFSUZqRXVtbUE?resourcekey=0-kdv6ho5KcpEXdI2aUdLn_g)
各种模型在MetaQA上的性能比较:MetaQA Dataset | Papers With Code
2. 数据集概述
MetaQA是Movie Text Audio QA的缩写。
2.1 内容介绍
数据集提供问答对,不提供SPARQL查询。这个数据集包括3个主要的组件:
① Vanilla text data
它总共有三个数据集:1-hop,2-hop,3-hop。其中1-hop源自Facebook MovieQA(也称 WikiMovies)数据集中的"wiki_entities"分支,相比MovieQA,Vanilla 1-hop 移除了问题中有歧义的实体,故该数据集也相对较小。
2-hop和3-hop也源于同一个知识库。其中2-hop有21种问题类型,3-hop有15种问题类型,每种类型都有10种文本模板。(如下图所示)


② NTM(Neural translation model) text data
在神经翻译模型的帮助下,可以自动引入更多的问题变量。我们将Vanilla数据集中的每个问题翻译成法语,然后用beam search 将其翻译回英语,以得到一个释义问题。实体被证实保留在释义问题中。
③ Audio data
用 Google text-to-speech API 读取Vanilla数据集中所有的问题并将音频保存为mp3文件。为了用户的方便,我们还提供对每个问题提取的MFCC特征。
2.2 使用的知识库
MetaQA中的所有问题都是从MovieQA中的电影知识库Wikidata中生成的。
知识库中存储的三元组形式: subject|relation|object
例:
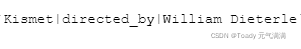
2.3 数据统计
该数据集给1-hop,2-hop,3-hop分别提供了train / dev / test ,且所有组件数据划分相同。数据集划分情况如下:
| 1-hop | 2-hop | 3-hop | |
| Train | 96,106 | 118,980 | 114,196 |
| Dev | 9,992 | 14,872 | 14,274 |
| Test | 9,947 | 14,872 | 14,274 |
2.4 文件内容介绍
kb.txt:知识库。每行都是一个知识三元组。
qa_(test/train/dev)_qtype.txt:问题类型相关文件(将性能分解为不同的问题类型,通常用于QA系统的评估)
entity(文件夹):存储了知识库中所有实体的音频。
entity_mp3.tar.gz:初始的MP3文件(与kb_entity_dict.txt中的索引顺序一致);
kb_entity_dict.txt:有索引的实体(从0开始);
kb_entity.npz:提取到的每个实体的MFCC特征。
3. 模型性能比较
这一部分主要是根据我看的论文进行了整理,在MetaQA数据集上的性能比较。
以上整理的内容若有不正确的地方,欢迎大家评论补充~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









