






1.关于几个常用的连接查询的小结
left join,right join,inner join full outer join,union,union all
left join(左连接) ——返回以左表为主的数据 右表中显示符合条件的数据 不符合的置为空
right join(右联接)——返回以右表为主的数据 左表中显示符合条件的数据 不符合的置为空
inner join(等值连接)—— 返回两个表中符合条件的数据full join (全连接) —— 返回两个表中所有的数据 不符合的数据置为空
union操作符用于合并两个或多个select语句的结果集
注意,union内部的select语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条select中的列顺序也必须相同,union只选取记录,而union all会列出所有记录
2. MySQL的存储引擎 myiasm 和innodb的区别
- InnoDB支持事物,而MyISAM不支持事物
- InnoDB支持行级锁,而MyISAM支持表级锁
- InnoDB支持MVCC, 而MyISAM不支持
- InnoDB支持外键,而MyISAM不支持
- InnoDB不支持全文索引,而MyISAM支持。
3.什么事务
是对数据库操作的最小单位 要么全部提交 要么全部不提交
4.事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。(update)
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。(insert)
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
5.事务的隔离级别 解决并发问题
Read uncommitted (读未提交):最低级别,任何情况都无法保证。
第一隔离级别怕回滚,因为它能读取到别的事务未提交的数据。如果当前事务将这个数据当成真正的数据,那么如果别的事务回滚,那么就会数据错误,导致脏读。
Read committed (读已提交):可避免脏读的发生。
第二个隔离级别怕提交,因为提交会导致不可重复读。
Repeatable read (可重复读):可避免脏读、不可重复读的发生。*MySQL默认隔离级别
Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
6.事务的四大特性是什么
atom 原子性 要么全部成功,要么全部失败
consistency 一致性 事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态(需进一步理解)
isolation 隔离型 事务对数据的修改其它事务不可见,事务与事务之间互不干扰
durability 持久性 事务提交完成之后,数据永久保存在磁盘中,不会因服务器宕机而丢失。
7.事务的四大特性是靠什么保证的
1.原子性
原子性是基于undolog来实现的。整个语句要么执行,要么不执行。一个原子性的事务 如果中间失败了,那么前面已经执行的怎么办?–回滚,利用undolog回滚执行一半的数据,以此保证事务的原子性。
2.一致性
一致性应该最后来说,一致性是靠其他三条特性共同保证的。
3.隔离性
Mysql利用锁和MVCC多版本并发控制(Multi Version Concurrency Control)来保证隔离性。
一个行记录数据有多个版本对快照数据,这些快照数据在undo log中。
如果一个事务读取的行正在做DELELE或者UPDATE操作,读取操作不会等行上的锁释放,而是读取该行的快照版本。
但是有一点说明一下,在事务隔离级别为读已提交(Read Commited)时,一个事务能够读到另一个事务已经提交的数据,是不满足隔离性的。但是当事务隔离级别为可重复读(Repeateable Read)中,是满足隔离性的。
4.持久性
innodb中的redo log可以保证持久性。Mysql是先把磁盘上的数据加载到内存中,在内存中对数据进行修改,再刷回磁盘上。如果此时突然宕机,内存中的数据就会丢失。
redo log解决上面的问题。当做数据修改的时候,不仅在内存中操作,还会在redo log中记录这次操作。当事务提交的时候,会将redo log日志进行刷盘(redo log一部分在内存中,一部分在磁盘上)。当数据库宕机重启的时候,会将redo log中的内容恢复到数据库中,再根据undo log和bin log内容决定回滚数据还是提交数据。
8.索引是什么,种类
索引是帮助MySQL高效获取数据的数据结构。当数据库中有大量的数据时,查询速度会变慢,索引就是一个加快数据库查询速度的方案。
1、从存储结构上来划分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。这里所描述的是索引存储时保存的形式,
2、从应用层次来分:普通索引,唯一索引,复合索引
3、根据中数据的物理顺序与键值的逻辑(索引)顺序关系:聚集(簇)索引,非聚集索引。
BTree索引是指 使用BTree存储索引 B-Tree(即Balanced Tree,平衡树)是一种数据结构,它能够保持所有的叶子节点在同一层级,而且每个叶子节点的数据记录都是按照键值大小排列的。
优点:
支持高效的查询、插入和删除操作;
对于范围查询效率较高;
适用于多种数据类型。
缺点:
对于数据类型较长的列(如 VARCHAR)来说,B-Tree 索引可能会变得很大,这会影响查询性能和存储空间;
在有些情况下,如全文搜索等,B-Tree 索引的效果并不好。
链接:https://www.zhihu.com/question/584117106/answer/2898314682
1.)n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
2.)所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指
针,且叶子结点本身依关键字的大小自小而大顺序链接。3.)所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
4.)B+ 树中,数据对象的插入和删除仅在叶节点上进行。
5.)B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
Hash索引:Hash 索引使用哈希表数据结构来存储索引信息。哈希表的键值是通过哈希函数计算得到的一个数字,而不是直接存储在数据结构中的
优点:
支持快速的等值查询操作,比如 WHERE column = value;
对于查询频率较高的列,Hash 索引的效率通常比B-Tree 索引高。
缺点:
不支持范围查询操作;
哈希函数的选择非常重要,不同的哈希函数可能导致哈希冲突,降低查询效率;
Hash 索引在存储空间上通常比B-Tree 索引更大。
普通索引是 MySQL 中最基本的索引类型之一,它可以加快对表中数据的查询速度,并且它只是用于提高查询效率。
唯一索引 是在表上一个或者多个字段组合建立的索引,这个(或这几个)字段的值组合起来在表中不可以重复。一张表可以建立任意多个唯一索引,但一般只建立一个。
主键是一种特殊的唯一索引,区别在于,唯一索引列允许null值,而主键列不允许为null值。一张表最多建立一个主键,也可以不建立主键
聚集索引 表记录的顺序和索引的排列顺序一致,所以查询效率快。只有当表包含聚集索引时,表内的数据行才会按找索引列的值在磁盘上进行物理排序和存储。每张表只能有一个聚集索引,原因很简单,因为数据行本身只能按一个顺序存储。
非聚集索引 指定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致。 非聚集索引在查找的时候要经过两个步骤,需要先搜索非聚集索引的B+Tree,这个B+Tree的叶子结点存储的不是完整的数据行,而是主键值,当我们搜索完成后得到主键的值,然后拿着主键值再去搜索主键索引的B+Tree,就可以获取到一行完整的数据。
原文链接:https://blog.csdn.net/qq_43592352/article/details/127351846
通俗一点就是
聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的索引顺序与数据物理排列顺序无关。举例来说,你翻到新华字典的汉字“爬”那一页就是P开头的部分,这就是物理存储顺序(聚簇索引);而不用你到目录,找到汉字“爬”所在的页码,然后根据页码找到这个字(非聚簇索引)。
9.索引的优缺点
1.索引可以提高数据检索的效率,降低数据库的IO成本,就类似与书的目录
2.索引并不是没有开销,他也是需要占用内存空间
3.索引只对当前列有效,即在字段age上创建的索引只有在age上有效,在字段name上就没有效果了
4.索引的创建会影响增删改的效率,因为对某一条记录进行更改时也要对索引进行更改
10.索引失效的几种方式
1、使用!= 或者 <> 导致索引失效
2、类型不一致导致的索引失效
3、函数导致的索引失效
4、运算符导致的索引失效
5、OR引起的索引失效
6、模糊搜索导致的索引失效
7、NOT IN、NOT EXISTS导致索引失效
8 、like "% xxx%" %在前会失效
11.索引的原则
MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引.最左匹配原则都是针对联合索引来说的
优点:最左前缀原则的利用也可以显著提高查询效率,是常见的MySQL性能优化手段。
12.为什么索引用的是B+树
①因为b+树是把数据都存放在叶子节点中的(在innodb存储引擎中一个b+树的节点是 一页(16k)),那么在固定大小的容量中 B+树的非叶子节点中就可以存放更多的索引列数据,也就意味着B+树的非叶子节点存储的数据的范围就会更大,那么树的层次就会更少,IO次数也就会更少;
②b+树的叶子节点维护了一个双向链表,它更有利于范围查询
③b+树中的叶子节点和非叶子节点的数据都是分开存储的,分别存放在叶子节点段和非叶子节点段,那么进行全表扫描的时候,就可以不用再扫描非叶子节点的数据了,并且这是一个顺序读取数据的过程(顺序读比随机读的速度要快很多很多),扫描的速度也会大大提高;
13.MySQL优化
1.show status 命令了解各种 sql 的执行频率
2.通过慢查询日志定位那些执行效率较低的 sql 语句
3.explain 分析低效 sql 的执行计划(这点非常重要,日常开发中用它分析Sql,会大大降低Sql导致的线上事故)
更为详细的请看这个内容 :https://juejin.cn/post/6844903493635932167
14.数据库的中间件了解吗
sharding-jdbc目前是基于jdbc驱动,无需额外的proxy,因此也无需关注proxy本身的高可用。Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库,而 Sharding-JDBC 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的。
15.mysql覆盖索引和回表
覆盖索引: 查询列要被所建的索引覆盖,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
回表:二级索引无法直接查询所有列的数据,所以通过二级索引查询到聚簇索引后,再查询到想要的数据,这种通过二级索引查询出来的过程,就叫做回表。
16.Sql的生命周期
服务器与数据库建立连接
数据库进程拿到请求sql
解析并生成执行计划,执行
读取数据到内存,并进行逻辑处理
通过步骤一的连接,发送结果到客户端
关掉连接,释放资源
17.Mysql中的锁
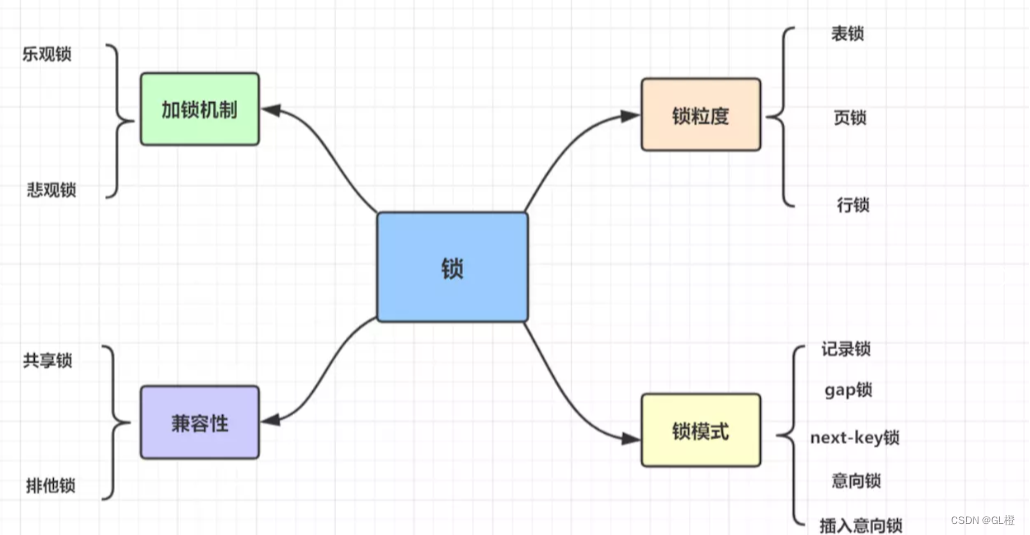
如果按锁粒度划分,有以下3种:
-
表锁: 开销小,加锁快;锁定力度大,发生锁冲突概率高,并发度最低;不会出现死锁。
-
行锁: 开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高。
-
页锁: 开销和加锁速度介于表锁和行锁之间;会出现死锁;锁定粒度介于表锁和行锁之间,并发度一般
18.mysql和oracle的区别
Oracle是闭源付费的大型数据库,占有内存空间大,支持高并发访问量
MySQL是开源免费的中小型数据库,占有内存空间小,支持的并发访问量小
Oracle没有自动增长类型,Mysql一般使用自动增长类型
19.场景题
1.事务方面
前提条件 A 调用 B
场景一 如果A和B方法在同一个类中:
如果A加@Transactional注解,B加不加@Transactional注解,事务是有效的,则AB在同一事务中。
如果A不加@Transactional注解,B加不加@Transactional注解,事务都是无效的。(但是如果使用代理类来进行b方法调用,那么B会开启事务,A不会开启事务)
场景二 如果A和B不在同一个类中:
2.1 如果A方法加@Transactional注解,b方法不加@Transactional注解:
结论:当不同类方法调用的时候(A调用B),若A方法添加了@Transional,B方法没有添加@Transional,那么B方法会加入到A方法的事务中。
(若B方法添加了@Transional,AB方法也在同一事务中,因为spring的事务默认传播等级)
2.2 如果A方法不加@Transactional注解,B加@Transactional注解:
因在b方法中出现了异常,mysql中只有goods表进行了数据回滚,说明只有B方法开启了事务。
结论:在不同类中,A不添加@Transitional方法调用B添加@Transitional的方法,A不会开启事务,B会开启事务。
引用的 原文链接:https://blog.csdn.net/lzq2357639195/article/details/129633850
2.一条SQL语句在mysql如何执行的

流程:
先检查该语句是否有权限
如果没有权限,直接返回错误信息
如果有权限,在 MySQL8.0 版本以前,会先查询缓存。
如果没有缓存,分析器进行词法分析,提取 sql 语句select等的关键元素。然后判断sql 语句是否有语法错误,比如关键词是否正确等等。
优化器进行确定执行方案
进行权限校验,如果没有权限就直接返回错误信息,如果有权限就会调用数据库引擎接口,返回执行结果。
SQL 等执行过程分为两类,
一类对于查询等过程如下:权限校验---》查询缓存---》分析器---》优化器---》权限校验---》执行器---》引擎
对于更新等语句执行流程如下:分析器----》权限校验----》执行器---》引擎---redo log prepare---》binlog---》redo log commit
出自此博客:MySQL面试经典100题(收藏版,附答案)_mysql面试必会100道题-CSDN博客
3.百万级数据量的处理
直接使用数据库提供的 SQL 语句
语法 : SELECT * FROM 表名称 LIMIT M,N
适用于数据量较少的情况 (元组百 / 千级)
原因 / 缺点: 全表扫描, 速度会很慢 且 有的数据库结果集返回不稳定 (如某次返回 1,2,3, 另外的一次返回 2,1,3). Limit 限制的是从结果集的 M 位置处取出 N 条输出, 其余抛弃.
基于索引在排序
语句样式: MySQL 中, 可用如下方法: SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
适应场景: 适用于数据量多的情况 (元组数上万). 最好 ORDER BY 后的列对象是主键或唯一所以, 使得 ORDERBY 操作能利用索引被消除但结果集是稳定的 (稳定的含义, 参见方法 1)
















 27万+
27万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









