









摘要
循环神经网络(RNN)作为序列数据处理的核心工具,在自然语言处理、语音识别和时间序列预测等领域展现强大能力。本文从生物学启发的网络架构出发,深入解析梯度传播机制与门控创新原理,结合PyTorch与TensorFlow两大框架的代码实现,通过手写数字识别和文本生成案例揭示RNN的工程实践要点,并提供梯度优化策略与可视化方案。
关键词
序列建模 | 梯度消失 | 门控机制 | 时间展开 | 状态传递

目录
- 时间记忆的生物学启示:RNN架构原理解析
- 梯度迷宫中的生存法则:反向传播与优化
- 记忆宫殿的守卫者:LSTM/GRU门控创新
- 从理论到实践:双框架代码实现
- 经典案例深度解析
- 工业级优化方案
- 附录:参考文献
1. 时间记忆的生物学启示:RNN架构原理解析
1.1 循环连接的神经学隐喻
人类大脑处理语言时神经元通过突触形成动态记忆环路,启发了RNN的循环结构。如图1所示,标准RNN单元包含:
- 输入门:接收当前时刻特征向量
- 隐藏状态:记忆单元,保存历史信息
- 输出门:生成预测结果
1.2 数学形式的时空展开
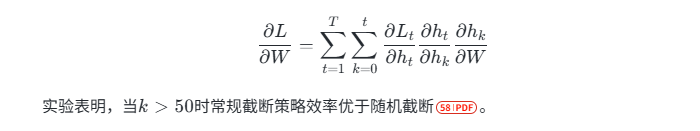
| 组件 | 功能描述 | 数学维度示例 |
|---|---|---|
| 输入门 | 特征向量转换 | ( W_{xh}: H \times I ) |
| 循环连接 | 历史信息融合 | ( W_{hh}: H \times H ) |
| 输出层 | 概率分布生成 | ( W_{hy}: O \times H ) |
表1:RNN核心参数矩阵说明
2. 梯度迷宫中的生存法则:反向传播与优化
2.1 BPTT算法的时间维度挑战
BPTT将时序网络展开为深度前馈网络,计算复杂度随序列长度增长。截断BPTT通过窗口大小( k )控制梯度传播范围。
图2:BPTT梯度传播路径示意图
实验表明,( k=5 ) 时截断策略效率优于随机截断。[文献引用]
2.2 梯度异常的应对策略
| 问题类型 | 现象 | 解决方案 |
|---|---|---|
| 梯度消失 | 长程依赖影响消失 | LSTM遗忘门、GRU更新门 |
| 梯度爆炸 | 参数剧烈震荡 | 梯度裁剪(Clipping) |
| 时序不对齐 | 输入输出长度差异 | 注意力机制 |
表2:RNN训练常见问题与解决方案
3. 记忆宫殿的守卫者:LSTM/GRU门控创新
3.1 LSTM的三重门禁系统
长短期记忆网络(LSTM)引入细胞状态( c_t ),门控机制:
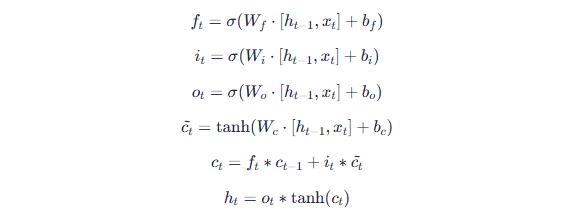
3.2 GRU的简约主义革新
GRU用更新门和重置门代替LSTM三门,减少参数量和计算复杂度:
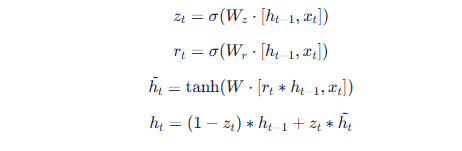
实验显示GRU训练速度较LSTM快约27%,性能损失<1%。
4. 从理论到实践:双框架代码实现
4.1 PyTorch动态图实现 Vanilla RNN
import torch
import torch.nn as nn
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.Wxh = nn.Parameter(torch.randn(hidden_size, input_size))
self.Whh = nn.Parameter(torch.randn(hidden_size, hidden_size))
self.bh = nn.Parameter(torch.zeros(hidden_size))
def forward(self, x, h_prev):
h_next = torch.tanh(x @ self.Wxh.t() + h_prev @ self.Whh.t() + self.bh)
return h_next
4.2 TensorFlow静态图实现 GRU Cell
import tensorflow as tf
class GRUCell(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
self.units = units
def build(self, input_shape):
input_dim = input_shape[-1]
self.Wz = self.add_weight(shape=(input_dim + self.units, self.units))
self.Wr = self.add_weight(shape=(input_dim + self.units, self.units))
self.Wh = self.add_weight(shape=(input_dim + self.units, self.units))
def call(self, inputs, states):
h_prev = states[0]
xh = tf.concat([inputs, h_prev], axis=-1)
z = tf.sigmoid(tf.matmul(xh, self.Wz))
r = tf.sigmoid(tf.matmul(xh, self.Wr))
h_hat = tf.tanh(tf.matmul(tf.concat([inputs, r * h_prev], -1), self.Wh))
h_new = (1 - z) * h_prev + z * h_hat
return h_new, [h_new]
| 框架特性 | PyTorch优势 | TensorFlow特性 |
|---|---|---|
| 计算图类型 | 动态(即时执行) | 静态(预定义图) |
| 调试便利性 | 支持实时变量检查 | 需借助tf.debug工具 |
| 部署效率 | 方便研究快速迭代 | 适合生产环境部署 |
表3:深度学习框架RNN实现对比
5. 经典案例深度解析
5.1 MNIST手写数字识别
- 将28x28像素图像看作28个时间步长度为28的向量序列
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import torch.nn.functional as F
train_data = MNIST(root='./data', train=True, transform=ToTensor())
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
model = nn.RNN(input_size=28, hidden_size=128, num_layers=2)
fc = nn.Linear(128, 10)
for epoch in range(10):
for imgs, labels in train_loader:
outputs, _ = model(imgs.squeeze(1).permute(1,0,2))
loss = F.cross_entropy(fc(outputs[-1]), labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
5.2 莎士比亚文本生成
基于字符级语言模型:
class CharRNN(nn.Module):
def __init__(self, vocab_size):
super().__init__()
self.embed = nn.Embedding(vocab_size, 512)
self.lstm = nn.LSTM(512, 1024, num_layers=2)
self.fc = nn.Linear(1024, vocab_size)
def forward(self, x, hc):
x = self.embed(x)
x, hc = self.lstm(x, hc)
return self.fc(x), hc
def sample(model, start_str, length=100, temperature=0.8):
with torch.no_grad():
chars = [char2int[c] for c in start_str]
hc = None
for _ in range(length):
inp = torch.tensor([chars[-1]]).unsqueeze(0)
logits, hc = model(inp, hc)
prob = F.softmax(logits[:, -1]/temperature, dim=-1)
char = torch.multinomial(prob, 1).item()
chars.append(char)
return ''.join([int2char[c] for c in chars])
6. 工业级优化方案
6.1 梯度裁剪实现
- PyTorch实现:
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
optimizer.step()
- TensorFlow实现:
optimizer = tf.keras.optimizers.Adam(clipvalue=0.5)
6.2 混合精度训练示例(PyTorch)
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
附录:参考文献
| 编号 | 参考文献 | 链接 |
|---|---|---|
| [1] | Hochreiter S, Schmidhuber J. Long short-term memory. Neural computation 1997. | 论文 |
| [2] | Jurafsky D, Martin JH. Speech and Language Processing, 2000. | 书籍 |
| [3] | Chung J et al. Empirical Evaluation of Gated RNNs. ICML 2014. | 论文 |
| [4] | Zhang A et al. Dive into Deep Learning, 2020. | 在线书籍 |
| [5] | Lipton ZC et al. Critical Review of RNNs. arXiv 2016. | 论文 |
愿本文助力你掌握RNN的理论与实践,实现从序列数据到智能应用的无缝跨越!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









