






 这本书是机器学习和深度学习领域的经典之作,新版基于TensorFlow2和Scikit-Learn更新,内容丰富,适合初学者和工程师。书中包含理论与实践结合的案例,提供GitHub代码,是AI项目的实用参考。Keras之父和前谷歌工程师联袂推荐,助你快速掌握最新技术。
这本书是机器学习和深度学习领域的经典之作,新版基于TensorFlow2和Scikit-Learn更新,内容丰富,适合初学者和工程师。书中包含理论与实践结合的案例,提供GitHub代码,是AI项目的实用参考。Keras之父和前谷歌工程师联袂推荐,助你快速掌握最新技术。
注:文末将送2本正版纸质图书!
传说中的机器学习“四大名著”中最适合入门的一本——“蜥蜴书”新版来了!

这本书的英文原版是美国亚马逊AI霸榜图书,在人工智能、计算机神经网络、计算机视觉和模式识别三大榜单中,均为榜首!
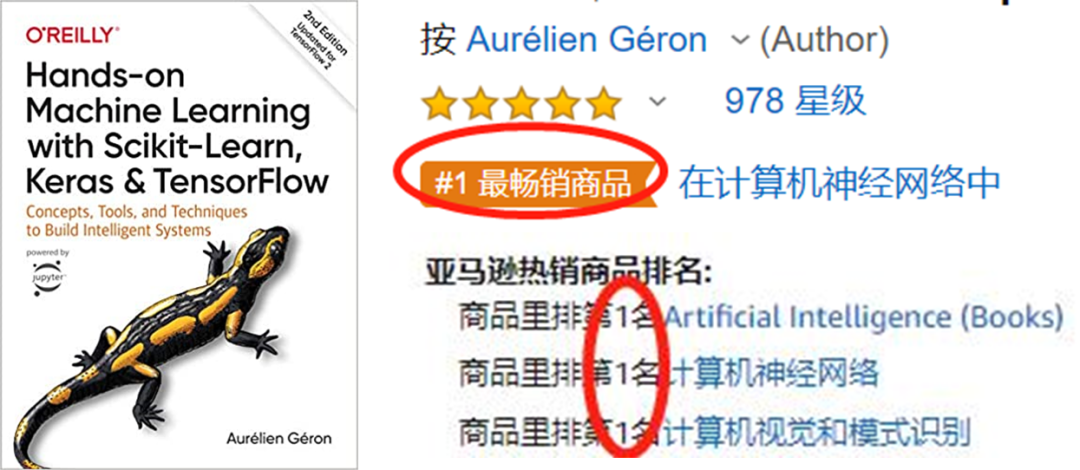
国内外好评率均超过90%!
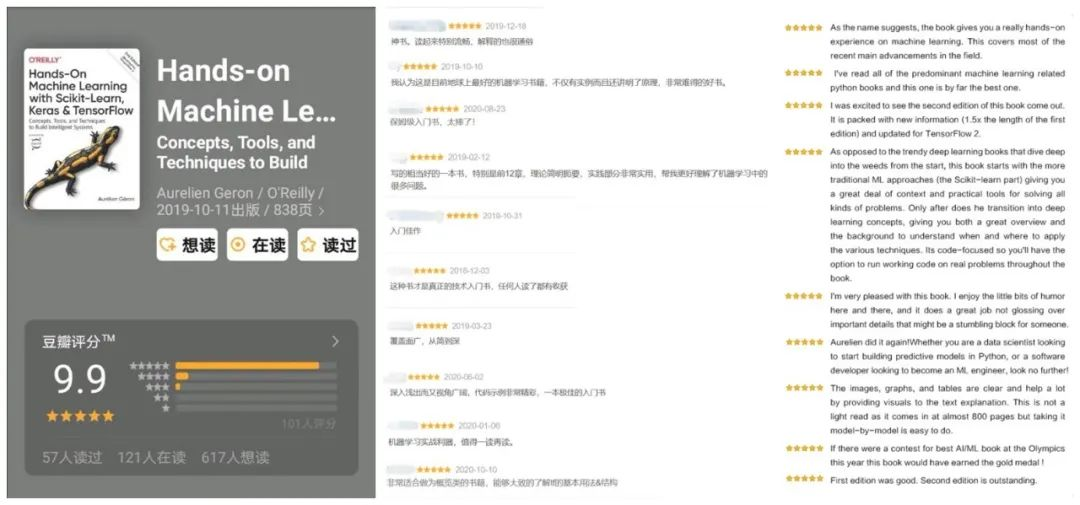
读者纷纷表示,希望能出中文版。
现在,中文版来了!
被国内外工程师们奉为“最强存在”的神书,闭眼入即可。
越早看,越受益!

如果你是是AI初学者,正在寻求一个切入点,那么强烈建议你把本书当作入门教材。
如果你是AI工程师,需要使用机器学习或者深度学习算法解决实际问题,可将本书当作实战手册,它可以让你了解深度学习的最新研究成果和实用技巧。
这本书能带给我什么?
对于想要踏入机器学习和深度学习领域的初学者和工程师而言,一本理论和实践相结合的书籍是必不可少的,本书就是这样一本书。
从理论上讲,本书最大的特色就是有深度,覆盖面广,但是书中并没有太多复杂的数学公式推导,很容易看懂。这在现在很多机器学习书籍中是不多见的。
从实战来说,本书使用了当前热门的机器学习框架Scikit-Learn及深度学习框架 TensorFlow和Keras,每一章都配备相应的项目示例,代码的实操性和可读性非常好。
本书也是为有经验的工程师而写的,是一本实用指南。特别是附录 B 给出的机器学习项目清单,如果工业界想做一套机器学习的解决方案,完全可以按照这个清单去做。

我看过第一版了,还要买第二版吗?
需要。第二版基于最新的TensorFlow 2和新版Scikit-Learn全面升级,内容增加近一倍。作者对书中的代码和习题也进行了全面更新,帮你更快进阶,掌握业界最新研究成果。

此外,本书还得到了Keras之父的鼎力推荐,作者本人也是前谷歌工程师,机器学习资深顾问:

阅读体验如何?
本书保持了O'REILLY精品图书一贯的严谨、清晰风格,通过代码注释和附注说明全面讲解知识点,配套GitHub代码、习题与答案,清楚明了。

实拍视频介绍
学习是对自己最好的投资!一本好书是1024程序员节送自己的最好礼物!
点击下方链接,即可优惠购书,即刻发货!书到用时方恨少,赶紧入手“蜥蜴书”,动手练起来吧!
《机器学习实战:基于Scikit-Learn、Keras和TensorFlow(原书第2版)》
AI霸榜书重磅更新!“美亚”AI+神经网络+CV三大畅销榜首图书,基于TensorFlow 2和新版Scikit-Learn全面升级,内容增加近一倍!前谷歌工程师撰写,Keras之父和TensorFlow移动端负责人鼎力推荐,从实践出发,手把手教你从零开始搭建起一个神经网络。
【赠书福利】
本次为大家送出2本“新版蜥蜴书”!10月11日22点结束并开奖。中奖读者将被免费寄送!
参与方法:
1、文末点 在看 !
2、公众号后台、或者扫以下码,回复 168 ,参与抽奖!

也可直接长按下述购买二维码:



















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









