






 NVIDIA提出ADA技术,显著降低GAN训练所需数据量,仅需数千张图像即可获得良好效果,有望推动医学成像等领域的应用。
NVIDIA提出ADA技术,显著降低GAN训练所需数据量,仅需数千张图像即可获得良好效果,有望推动医学成像等领域的应用。
点击上方“机器学习与生成对抗网络”,关注"星标"获取有趣、好玩的前沿干货!
来源 | venturebeat
报道 | 新智元 编辑 | 科雨
【导读】Nivida最新力作将于NeurlPS2020露面,强大的ADA模型可大幅降低GAN的训练数据要求,仅靠千张图片,即可训练出强大的GAN网络,下面我们就来一探究竟。
我们大家都知道,训练常规的GAN需要大量的数据,比如100,000张图。
近日,Nivida的研究人员研发出了一种被称为自适应鉴别器增强(ADA, Adaptive Discriminator Augmentation)的方法,直接将训练数据量减少10到20倍,此研究成果已经被发布在《用有限数据训练生成对抗网络(Training Generative Adversarial Networks with Limited Data》这篇论文中,该论文也将参加今年的NeurlPS2020会议。

论文中表示:「使用小型数据集的关键问题在于,判别器在训练样本上出现了过拟合,从而向生成器中传递的反馈开始失去意义,训练情况也逐渐开始变得一致。」
为了证明实验结果解决了这一技术难题,研究人员展示了在几个数据集上,仅仅使用几千个图像,就可以得到可观的结果,并且在通常情况下,可以将StyleGAN2的结果与数量很少的图像相匹配。」
借鉴bCR方法,增强判别器泛化能力
该论文使用的方法借鉴了bCR的处理过程,什么是bCR呢?
从定义上来说,任何应用到训练数据集的增强效果都会被生成的图像继承。Zhao 等人在CoRR2020上发表的《GAN的改善一致正则化(Improved consistency regularization for GANs》中的平衡一致正则化(balanced Consistency Regularization, bCR)就是针对此问题的一个解决方案。
一致正则化主要表明,使用在相同输入图像中的两组增强,应该产生相同的输出。Zhao等人将一致正则化条件添加到判别器损失中,并将判别器一致性强制使用在真实图像和生成图像中,而训练生成器的时候则不使用增强操作和一致性损失操作。
如此,bCR这一方法通过令判别器对在一致正则化(CR)条件下的增强效果视而不见,从而有效地对判别器进行了泛化。
该论文的方法和bCR相似,都对展示给判别器的所有图像做了一系列增强操作,而和bCR不同的是,该篇论文并没有添加分离CR损失,而只使用了增强过的图像,并在训练生成器的过程中也做了此操作。此方法被研究人员称为随机判别器增强(Stochastic Discriminator Augmentation)。
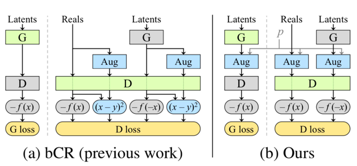
两种方法的比较:左:bCR,右:Stochastic Discriminator Augmentation
下图展示了研究人员对每张判别器处理的图像进行一系列增强操作的结果,其中,此过程由增强概率p控制:

bCR方法在有效泛化判别器的同时,也导致了泄漏增强效果的后果,因为生成器可以自由生成包含增强结果的图像,却没有收到任何惩罚。
在Nivida最新论文中,研究者通过实验发现,只要p小于0.8,增强效果的泄漏就不可能在实际操作中出现,从而通过p的调整,有效解决了bCR出现的问题。
下图展示了使用有限训练数据,在ADA的操作下,在不同数据集下的生成图像结果:

此外,今年早些时候,来自来自Adobe Research,麻省理工学院和清华大学的研究人员详细介绍了DiffAugment,这是GAN增强的另一种方法。
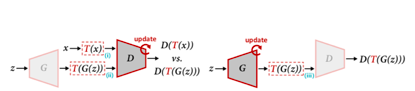
DiffAugment模型概括
降低数据量限制,或将在医学成像中大有应用
Nvidia图形研究副总裁David Luebke表示,任何在实践过程中使用过实际数据科学工具的人都知道,绝大多数时间都被花费在收集和整理数据上,这个过程有时候被称为ETL管道(ETL pipeline):提取(extract),转换(transform)和加载(load)。
仅此一项,就需要大量的真实数据,因此,自适应鉴别器增强(ADA)方法的出现为使用者提供了巨大的帮助,因为不需要那么多的数据,就可以获得有用的结果。
他表示,在和没有太多空余时间的注释人员一起工作的时候,这个成果将会起着更重要的作用。
此论文的作者认为,减少数据的限制,可以让研究人员能够发掘出GAN的更多用例。除了伪造人或者动物的照片之外,研究人员认为GAN可能会在医学成像数据中得到广泛的应用。
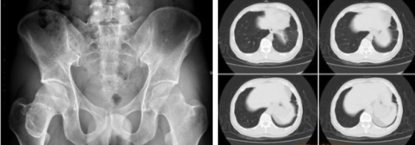
「如果有一位专门研究特定疾病的放射科医生,让他们坐下来并为50,000张图像进行注释的事情很可能不会发生,但是,如果让他们为1,000张图像进行注释,似乎很有可能。
这项研究成果,的确改变了实际的数据科学家在整理数据的时候所需要付出的努力,而这会令探索新的应用变得容易很多。」Luebke说。
相关突破颇多,Yoshua Bengio新作同期亮相NeurlPS2020
《用有限数据训练生成对抗网络(Training Generative Adversarial Networks with Limited Data》并非是NeurlPS2020中唯一一篇与GAN有关的论文。
MILA 魁北克人工智能研究所(MILA Quebec Artificial Intelligence Institute)和Google Brain的研究人员(其中包括蒙特利尔Google Brain小组组长兼NeurlPS会议主席Yoshua Bengio和Hugo Larochelle),就发表了另外一篇判别器驱动的潜在采样方法(Discriminator Driven Latent Sampling, DDLS),该方法的结果显示,当使用CIFAR-10数据集进行评估时,它可以提高现成GAN的性能。

最后附上ADA方法的论文传送站,感兴趣的朋友可以自行探索实现细节:
https://proceedings.neurips.cc/paper/2020/hash/8d30aa96e72440759f74bd2306c1fa3d-Abstract.html
参考链接:
https://venturebeat.com/2020/12/07/nvidia-researchers-devise-method-for-training-gans-with-less-data/
相关阅读:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









