






作者丨游客26024@知乎(已授权) 编辑丨极市平台
来源丨https://www.zhihu.com/question/461811359/answer/2492822726
题外话,我为什么要写这篇博客,就是因为我穷!没钱!租的服务器使用多GPU时一会钱就烧没了(gpu内存不用),急需要一种trick,来降低内存加速。
回到正题,如果我们使用的数据集较大,且网络较深,则会造成训练较慢,此时我们要想加速训练可以使用Pytorch的AMP(autocast与Gradscaler);本文便是依据此写出的博文,对Pytorch的AMP(autocast与Gradscaler进行对比)自动混合精度对模型训练加速。
注意Pytorch1.6+,已经内置torch.cuda.amp,因此便不需要加载NVIDIA的apex库(半精度加速),为方便我们便不使用NVIDIA的apex库(安装麻烦),转而使用torch.cuda.amp。
AMP (Automatic mixed precision): 自动混合精度,那什么是自动混合精度?
先来梳理一下历史:先有NVIDIA的apex,之后NVIDIA的开发人员将其贡献到Pytorch 1.6+产生了torch.cuda.amp[这是笔者梳理,可能有误,请留言]
详细讲:默认情况下,大多数深度学习框架都采用32位浮点算法进行训练。2017年,NVIDIA研究了一种用于混合精度训练的方法(apex),该方法在训练网络时将单精度(FP32)与半精度(FP16)结合在一起,并使用相同的超参数实现了与FP32几乎相同的精度,且速度比之前快了不少
之后,来到了AMP时代(特指torch.cuda.amp),此有两个关键词:自动与混合精度(Pytorch 1.6+中的torch.cuda.amp)其中,自动表现在Tensor的dtype类型会自动变化,框架按需自动调整tensor的dtype,可能有些地方需要手动干预;混合精度表现在采用不止一种精度的Tensor, torch.FloatTensor与torch.HalfTensor。并且从名字可以看出torch.cuda.amp,这个功能只能在cuda上使用!
为什么我们要使用AMP自动混合精度?
1.减少显存占用(FP16优势)
2.加快训练和推断的计算(FP16优势)
3.张量核心的普及(NVIDIA Tensor Core),低精度(FP16优势)
4. 混合精度训练缓解舍入误差问题,(FP16有此劣势,但是FP32可以避免此)
5.损失放大,可能使用混合精度还会出现无法收敛的问题[其原因时激活梯度值较小],造成了溢出,则可以通过使用torch.cuda.amp.GradScaler放大损失来防止梯度的下溢
申明此篇博文主旨为如何让网络模型加速训练,而非去了解其原理,且其以AlexNet为网络架构(其需要输入的图像大小为227x227x3),CIFAR10为数据集,Adamw为梯度下降函数,学习率机制为ReduceLROnPlateau举例。使用的电脑是2060的拯救者,虽然渣,但是还是可以搞搞这些测试。
本文从1.没使用DDP与DP训练与评估代码(之后加入amp),2.分布式DP训练与评估代码(之后加入amp),3.单进程占用多卡DDP训练与评估代码(之后加入amp) 角度讲解。
运行此程序时,文件的结构:
D:/PycharmProject/Simple-CV-Pytorch-master
|
|
|
|----AMP(train_without.py、train_DP.py、train_autocast.py、train_GradScaler.py、eval_XXX.py
|等,之后加入的alexnet也在这里,alexnet.py)
|
|
|
|----tensorboard(保存tensorboard的文件夹)
|
|
|
|----checkpoint(保存模型的文件夹)
|
|
|
|----data(数据集所在文件夹)1.没使用DDP与DP训练与评估代码
没使用DDP与DP的训练与评估实验,作为我们实验的参照组
(1)原本模型的训练与评估源码:
训练源码:
注意:此段代码无比简陋,仅为代码的雏形,大致能理解尚可!
train_without.py
import time
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import alexnet
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()运行结果:
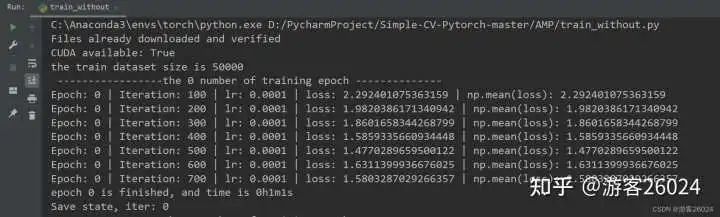
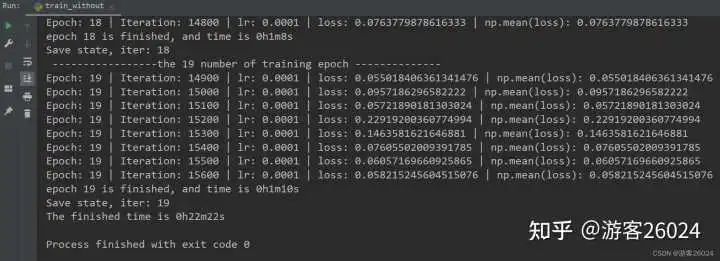
Tensorboard观察:
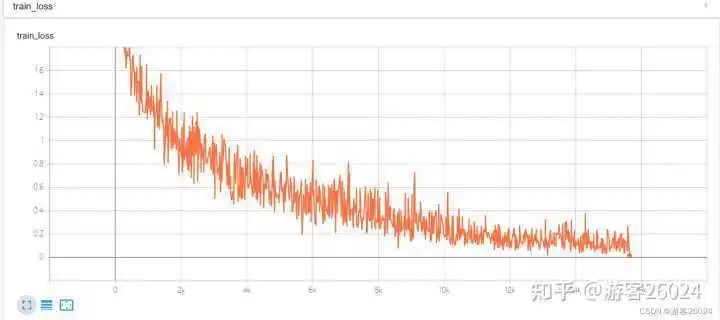
评估源码:
代码特别粗犷,尤其是device与精度计算,仅供参考,切勿模仿!
eval_without.py
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from alexnet import alexnet
import argparse
# eval
def parse_args():
parser = argparse.ArgumentParser(description='CV Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create model
model = alexnet()
# 2.Ready Dataset
if args.dataset == 'CIFAR10':
test_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=False,
transform=transforms.Compose(
[transforms.Resize(args.img_size),
transforms.ToTensor()]),
download=True)
else:
raise ValueError("Dataset is not CIFAR10")
# 3.Length
test_dataset_size = len(test_dataset)
print("the test dataset size is {}".format(test_dataset_size))
# 4.DataLoader
test_dataloader = DataLoader(dataset=test_dataset, batch_size=args.batch_size)
# 5. Set some parameters for testing the network
total_accuracy = 0
# test
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
device = torch.device('cpu')
imgs, targets = imgs.to(device), targets.to(device)
model_load = torch.load("{}/AlexNet.pth".format(args.checkpoint), map_location=device)
model.load_state_dict(model_load)
outputs = model(imgs)
outputs = outputs.to(device)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
accuracy = total_accuracy / test_dataset_size
print("the total accuracy is {}".format(accuracy))运行结果:
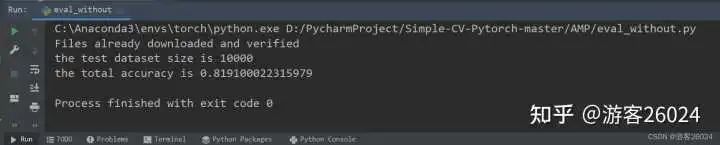
分析:
原本模型训练完20个epochs花费了22分22秒,得到的准确率为0.8191
(2)原本模型加入autocast的训练与评估源码:
训练源码:
训练大致代码流程:
from torch.cuda.amp import autocast as autocast
...
# Create model, default torch.FloatTensor
model = Net().cuda()
# SGD,Adm, Admw,...
optim = optim.XXX(model.parameters(),..)
...
for imgs,targets in dataloader:
imgs,targets = imgs.cuda(),targets.cuda()
....
with autocast():
outputs = model(imgs)
loss = loss_fn(outputs,targets)
...
optim.zero_grad()
loss.backward()
optim.step()
...train_autocast_without.py
import time
import torch
import torchvision
from torch import nn
from torch.cuda.amp import autocast
from torchvision import transforms
from torchvision.models import alexnet
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()运行结果:
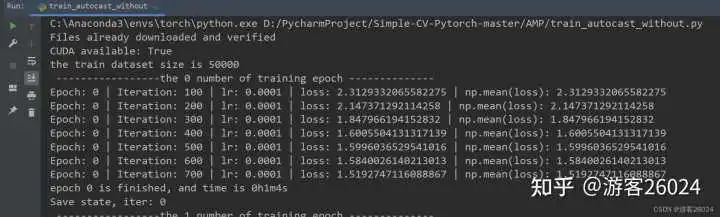
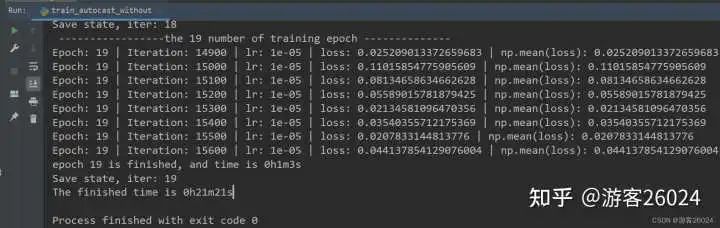
Tensorboard观察:
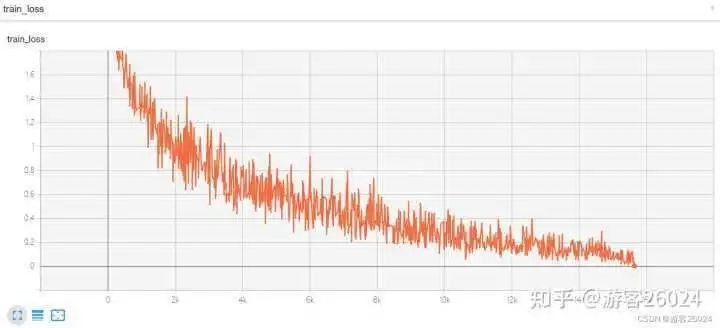
评估源码:
eval_without.py 和 1.(1)一样
运行结果:

分析:
原本模型训练完20个epochs花费了22分22秒,加入autocast之后模型花费的时间为21分21秒,说明模型速度增加了,并且准确率从之前的0.8191提升到0.8403
(3)原本模型加入autocast与GradScaler的训练与评估源码:
使用torch.cuda.amp.GradScaler是放大损失值来防止梯度的下溢
训练源码:
训练大致代码流程:
from torch.cuda.amp import autocast as autocast
from torch.cuda.amp import GradScaler as GradScaler
...
# Create model, default torch.FloatTensor
model = Net().cuda()
# SGD,Adm, Admw,...
optim = optim.XXX(model.parameters(),..)
scaler = GradScaler()
...
for imgs,targets in dataloader:
imgs,targets = imgs.cuda(),targets.cuda()
...
optim.zero_grad()
....
with autocast():
outputs = model(imgs)
loss = loss_fn(outputs,targets)
scaler.scale(loss).backward()
scaler.step(optim)
scaler.update()
...train_GradScaler_without.py
import time
import torch
import torchvision
from torch import nn
from torch.cuda.amp import autocast, GradScaler
from torchvision import transforms
from torchvision.models import alexnet
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
scaler = GradScaler()
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
optim.zero_grad()
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
scaler.scale(loss_train).backward()
scaler.step(optim)
scaler.update()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()运行结果:
Tensorboard观察:

评估源码:
eval_without.py 和 1.(1)一样
运行结果:

分析:
为什么,我们训练完20个epochs花费了27分27秒,比之前原模型未使用任何amp的时间(22分22秒)都多了?
这是因为我们使用了GradScaler放大了损失降低了模型训练的速度,还有个原因可能是笔者自身的显卡太小,没有起到加速的作用
2.分布式DP训练与评估代码
(1)DP原本模型的训练与评估源码:
训练源码:
train_DP.py
import time
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import alexnet
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()运行结果:
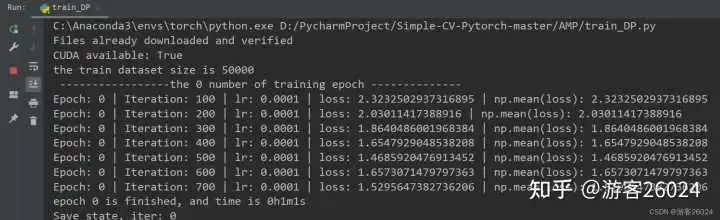
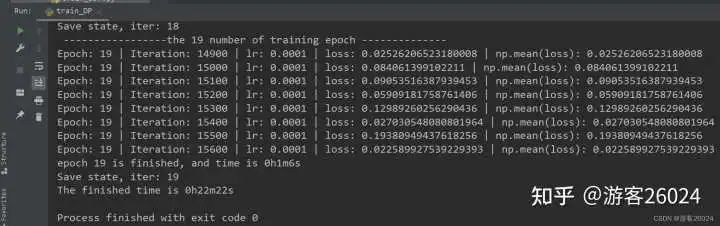
Tensorboard观察:
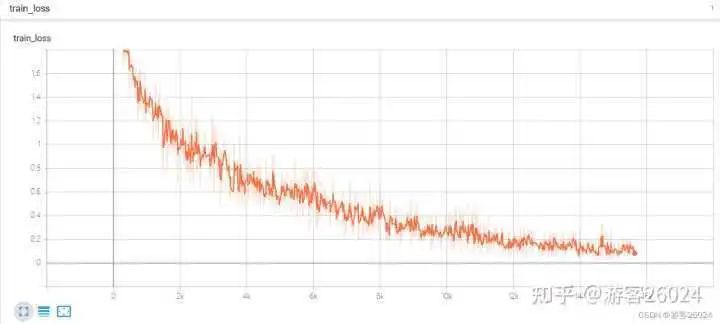
评估源码:
eval_DP.py
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from alexnet import alexnet
import argparse
# eval
def parse_args():
parser = argparse.ArgumentParser(description='CV Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create model
model = alexnet()
model = torch.nn.DataParallel(model)
# 2.Ready Dataset
if args.dataset == 'CIFAR10':
test_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=False,
transform=transforms.Compose(
[transforms.Resize(args.img_size),
transforms.ToTensor()]),
download=True)
else:
raise ValueError("Dataset is not CIFAR10")
# 3.Length
test_dataset_size = len(test_dataset)
print("the test dataset size is {}".format(test_dataset_size))
# 4.DataLoader
test_dataloader = DataLoader(dataset=test_dataset, batch_size=args.batch_size)
# 5. Set some parameters for testing the network
total_accuracy = 0
# test
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
device = torch.device('cpu')
imgs, targets = imgs.to(device), targets.to(device)
model_load = torch.load("{}/AlexNet.pth".format(args.checkpoint), map_location=device)
model.load_state_dict(model_load)
outputs = model(imgs)
outputs = outputs.to(device)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
accuracy = total_accuracy / test_dataset_size
print("the total accuracy is {}".format(accuracy))运行结果:

(2)DP使用autocast的训练与评估源码:
训练源码:
如果你这样写代码,那么你的代码无效!!!
...
model = Model()
model = torch.nn.DataParallel(model)
...
with autocast():
output = model(imgs)
loss = loss_fn(output)正确写法,训练大致流程代码:
1.Model(nn.Module):
@autocast()
def forward(self, input):
...
2.Model(nn.Module):
def foward(self, input):
with autocast():
...1与2皆可,之后:
...
model = Model()
model = torch.nn.DataParallel(model)
with autocast():
output = model(imgs)
loss = loss_fn(output)
...模型:
须在forward函数上加入@autocast()或者在forward里面最上面加入with autocast():
alexnet.py
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
from torch.cuda.amp import autocast
from typing import Any
__all__ = ['AlexNet', 'alexnet']
model_urls = {
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
}
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
@autocast()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def alexnet(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> AlexNet:
r"""AlexNet model architecture from the
`"One weird trick..." <https://arxiv.org/abs/1404.5997>`_ paper.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
model = AlexNet(**kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls["alexnet"],
progress=progress)
model.load_state_dict(state_dict)
return modeltrain_DP_autocast.py 导入自己的alexnet.py
import time
import torch
from alexnet import alexnet
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.cuda.amp import autocast as autocast
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()运行结果:
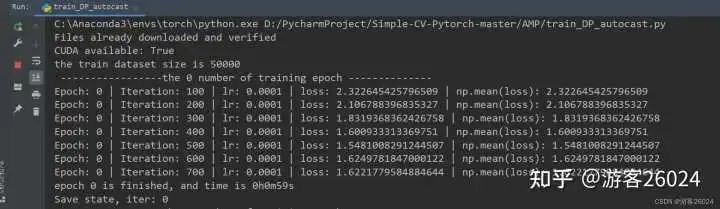
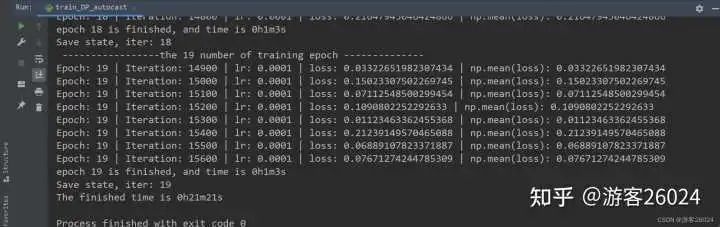
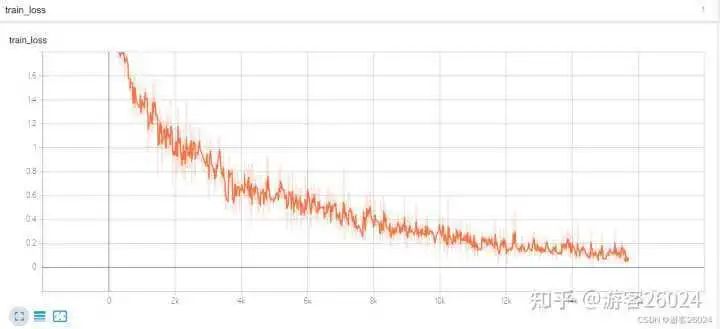
Tensorboard观察:
评估源码:
eval_DP.py 相比与2. (1)导入自己的alexnet.py
运行结果:

分析:
可以看出DP使用autocast训练完20个epochs时需要花费的时间是21分21秒,相比与之前DP没有使用的时间(22分22秒)快了1分1秒
之前DP未使用amp能达到准确率0.8216,而现在准确率降低到0.8188,说明还是使用自动混合精度加速还是对模型的准确率有所影响,后期可通过增大batch_sizel让运行时间和之前一样,但是准确率上升,来降低此影响
(3)DP使用autocast与GradScaler的训练与评估源码:
训练源码:
train_DP_GradScaler.py 导入自己的alexnet.py
import time
import torch
from alexnet import alexnet
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.cuda.amp import autocast as autocast
from torch.cuda.amp import GradScaler as GradScaler
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
scaler = GradScaler()
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
optim.zero_grad()
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
scaler.scale(loss_train).backward()
scaler.step(optim)
scaler.update()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()运行结果:
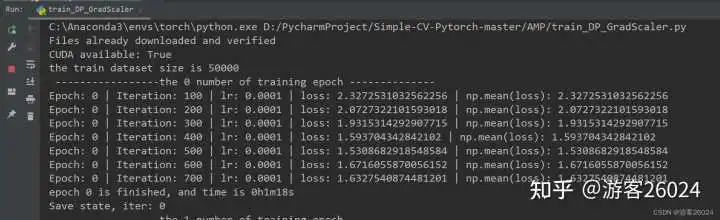
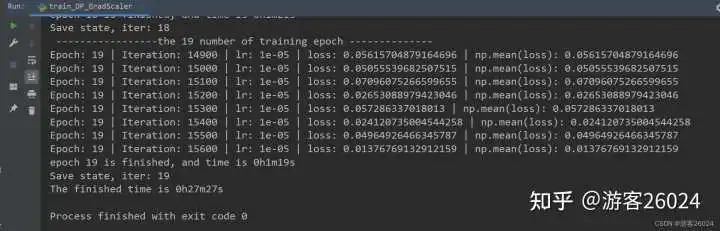
Tensorboard观察:
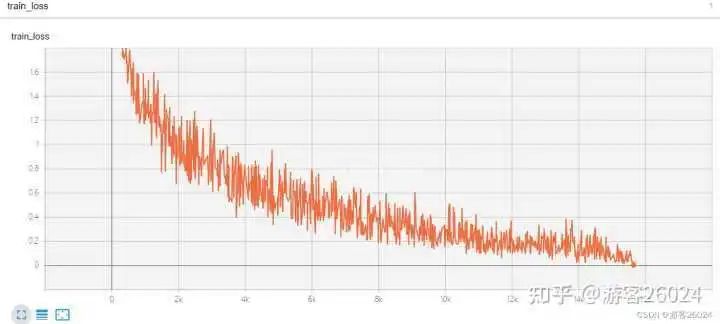
评估源码:
eval_DP.py 相比与2. (1)导入自己的alexnet.py
运行结果:

分析:
跟之前一样,DP使用了GradScaler放大了损失降低了模型训练的速度
现在DP使用了autocast与GradScaler的准确率为0.8409,相比与DP只使用autocast准确率0.8188还是有所上升,并且之前DP未使用amp是准确率(0.8216)也提高了不少
3.单进程占用多卡DDP训练与评估代码
(1)DDP原模型训练与评估源码:
训练源码:
train_DDP.py
import time
import torch
from torchvision.models.alexnet import alexnet
import torchvision
from torch import nn
import torch.distributed as dist
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def train():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, sampler=train_sampler,
num_workers=2,
pin_memory=True)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model).cuda()
else:
model = torch.nn.parallel.DistributedDataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
train()运行结果:
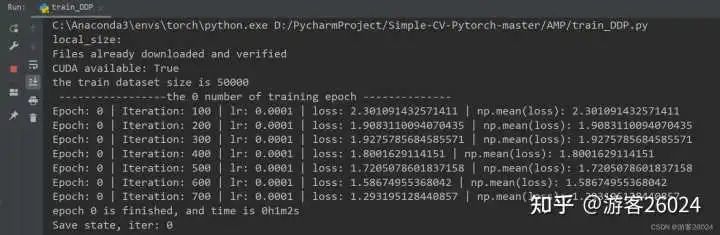
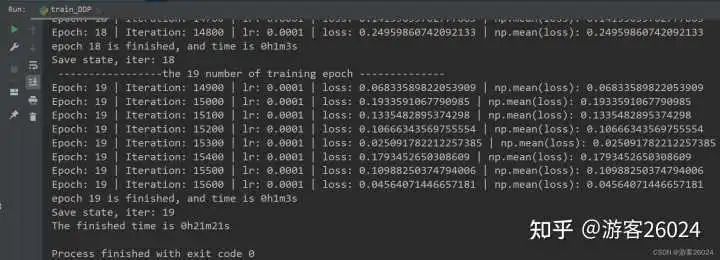
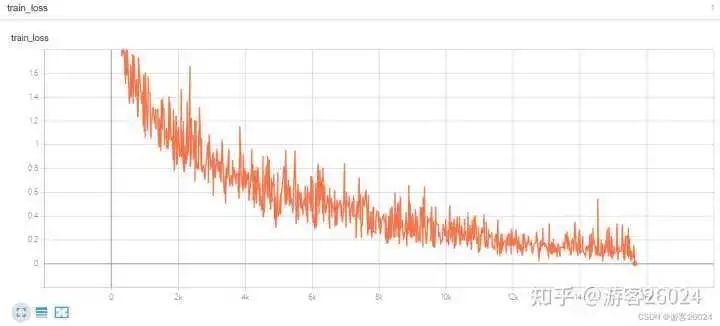
Tensorboard观察:
评估源码:
eval_DDP.py
import torch
import torchvision
import torch.distributed as dist
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
# from alexnet import alexnet
from torchvision.models.alexnet import alexnet
import argparse
# eval
def parse_args():
parser = argparse.ArgumentParser(description='CV Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def eval():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create model
model = alexnet()
model = torch.nn.parallel.DistributedDataParallel(model)
# 2.Ready Dataset
if args.dataset == 'CIFAR10':
test_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=False,
transform=transforms.Compose(
[transforms.Resize(args.img_size),
transforms.ToTensor()]),
download=True)
else:
raise ValueError("Dataset is not CIFAR10")
# 3.Length
test_dataset_size = len(test_dataset)
print("the test dataset size is {}".format(test_dataset_size))
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
# 4.DataLoader
test_dataloader = DataLoader(dataset=test_dataset, sampler=test_sampler, batch_size=args.batch_size,
num_workers=2,
pin_memory=True)
# 5. Set some parameters for testing the network
total_accuracy = 0
# test
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
device = torch.device('cpu')
imgs, targets = imgs.to(device), targets.to(device)
model_load = torch.load("{}/AlexNet.pth".format(args.checkpoint), map_location=device)
model.load_state_dict(model_load)
outputs = model(imgs)
outputs = outputs.to(device)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
accuracy = total_accuracy / test_dataset_size
print("the total accuracy is {}".format(accuracy))
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
eval()运行结果:

(2)DDP使用autocast的训练与评估源码:
训练源码:
train_DDP_autocast.py 导入自己的alexnet.py
import time
import torch
from alexnet import alexnet
import torchvision
from torch import nn
import torch.distributed as dist
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.cuda.amp import autocast as autocast
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def train():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, sampler=train_sampler,
num_workers=2,
pin_memory=True)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model).cuda()
else:
model = torch.nn.parallel.DistributedDataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
train()运行结果:
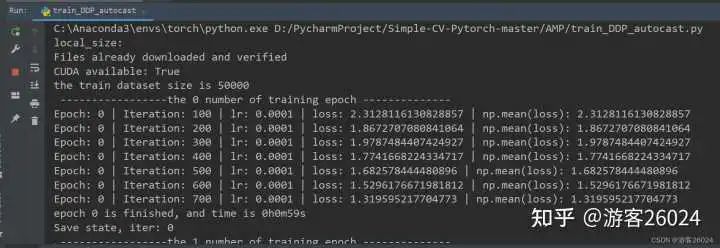
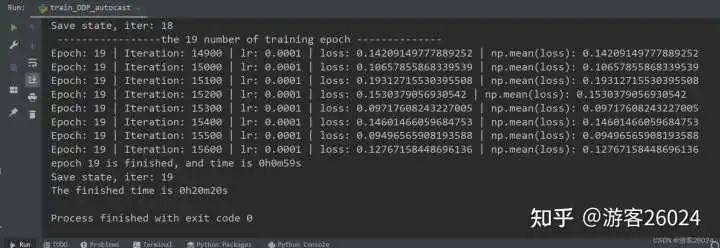
Tensorboard观察:
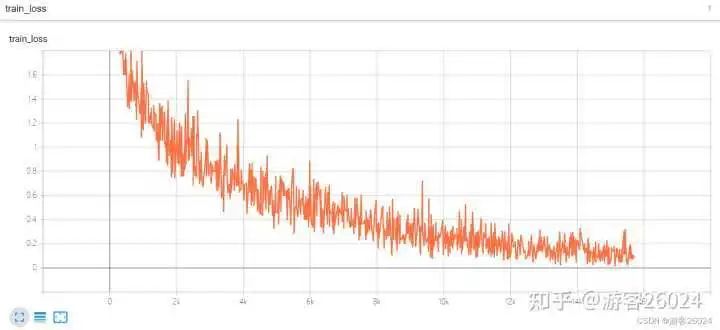
评估源码:
eval_DDP.py 导入自己的alexnet.py
import torch
import torchvision
import torch.distributed as dist
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from alexnet import alexnet
# from torchvision.models.alexnet import alexnet
import argparse
# eval
def parse_args():
parser = argparse.ArgumentParser(description='CV Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def eval():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create model
model = alexnet()
model = torch.nn.parallel.DistributedDataParallel(model)
# 2.Ready Dataset
if args.dataset == 'CIFAR10':
test_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=False,
transform=transforms.Compose(
[transforms.Resize(args.img_size),
transforms.ToTensor()]),
download=True)
else:
raise ValueError("Dataset is not CIFAR10")
# 3.Length
test_dataset_size = len(test_dataset)
print("the test dataset size is {}".format(test_dataset_size))
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
# 4.DataLoader
test_dataloader = DataLoader(dataset=test_dataset, sampler=test_sampler, batch_size=args.batch_size,
num_workers=2,
pin_memory=True)
# 5. Set some parameters for testing the network
total_accuracy = 0
# test
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
device = torch.device('cpu')
imgs, targets = imgs.to(device), targets.to(device)
model_load = torch.load("{}/AlexNet.pth".format(args.checkpoint), map_location=device)
model.load_state_dict(model_load)
outputs = model(imgs)
outputs = outputs.to(device)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
accuracy = total_accuracy / test_dataset_size
print("the total accuracy is {}".format(accuracy))
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
eval()运行结果:

分析:
从DDP未使用amp花费21分21秒,DDP使用autocast花费20分20秒,说明速度提升了
DDP未使用amp的准确率0.8224,之后DDP使用了autocast准确率下降到0.8162
(3)DDP使用autocast与GradScaler的训练与评估源码
训练源码:
train_DDP_GradScaler.py 导入自己的alexnet.py
import time
import torch
from alexnet import alexnet
import torchvision
from torch import nn
import torch.distributed as dist
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.cuda.amp import autocast as autocast
from torch.cuda.amp import GradScaler as GradScaler
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='CV Train')
parser.add_mutually_exclusive_group()
parser.add_argument("--rank", type=int, default=0)
parser.add_argument("--world_size", type=int, default=1)
parser.add_argument("--master_addr", type=str, default="127.0.0.1")
parser.add_argument("--master_port", type=str, default="12355")
parser.add_argument('--dataset', type=str, default='CIFAR10', help='CIFAR10')
parser.add_argument('--dataset_root', type=str, default='../data', help='Dataset root directory path')
parser.add_argument('--img_size', type=int, default=227, help='image size')
parser.add_argument('--tensorboard', type=str, default=True, help='Use tensorboard for loss visualization')
parser.add_argument('--tensorboard_log', type=str, default='../tensorboard', help='tensorboard folder')
parser.add_argument('--cuda', type=str, default=True, help='if is cuda available')
parser.add_argument('--batch_size', type=int, default=64, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--epochs', type=int, default=20, help='Number of epochs to train.')
parser.add_argument('--checkpoint', type=str, default='../checkpoint', help='Save .pth fold')
return parser.parse_args()
args = parse_args()
def train():
dist.init_process_group("gloo", init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=args.rank,
world_size=args.world_size)
# 1.Create SummaryWriter
if args.tensorboard:
writer = SummaryWriter(args.tensorboard_log)
# 2.Ready dataset
if args.dataset == 'CIFAR10':
train_dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True, transform=transforms.Compose(
[transforms.Resize(args.img_size), transforms.ToTensor()]), download=True)
else:
raise ValueError("Dataset is not CIFAR10")
cuda = torch.cuda.is_available()
print('CUDA available: {}'.format(cuda))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, sampler=train_sampler,
num_workers=2,
pin_memory=True)
# 5.Create model
model = alexnet()
if args.cuda == cuda:
model = model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model).cuda()
else:
model = torch.nn.parallel.DistributedDataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
optim = torch.optim.AdamW(model.parameters(), lr=args.lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
scaler = GradScaler()
# 8. Set some parameters to control loop
# epoch
iter = 0
t0 = time.time()
for epoch in range(args.epochs):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(epoch))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
optim.zero_grad()
if args.cuda == cuda:
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
with autocast():
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
if args.tensorboard:
writer.add_scalar("train_loss", loss_train.item(), iter)
scaler.scale(loss_train).backward()
scaler.step(optim)
scaler.update()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(epoch, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
if args.tensorboard:
writer.add_scalar("lr", optim.param_groups[0]['lr'], epoch)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(epoch, int(h), int(m), int(s)))
if epoch % 1 == 0:
print("Save state, iter: {} ".format(epoch))
torch.save(model.state_dict(), "{}/AlexNet_{}.pth".format(args.checkpoint, epoch))
torch.save(model.state_dict(), "{}/AlexNet.pth".format(args.checkpoint))
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
if args.tensorboard:
writer.close()
if __name__ == "__main__":
local_size = torch.cuda.device_count()
print("local_size: ".format(local_size))
train()运行结果:
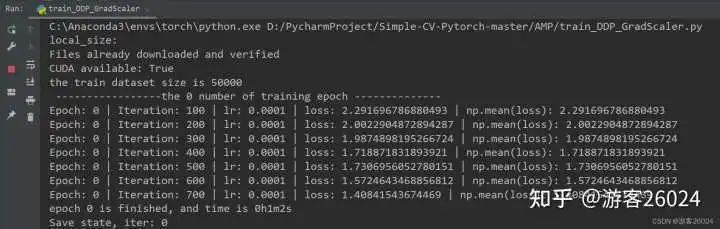
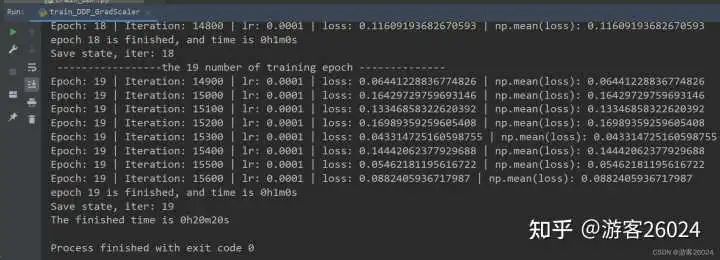
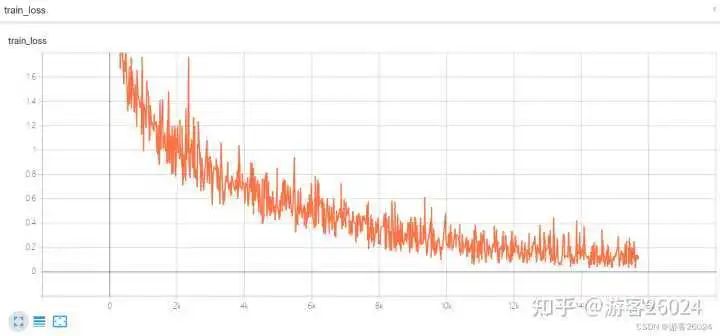
Tensorboard观察:
评估源码:
eval_DDP.py 与3. (2) 一样,导入自己的alexnet.py
运行结果:
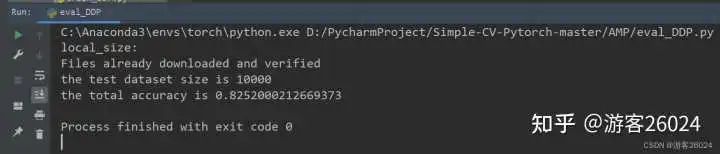
分析:
运行起来了,速度也比DDP未使用amp(用时21分21秒)快了不少(用时20分20秒),之前DDP未使用amp准确率到达0.8224,现在DDP使用了autocast与GradScaler的准确率达到0.8252,提升了
参考:
1.Pytorch自动混合精度(AMP)训练:https://blog.csdn.net/ytusdc/article/details/122152244
2.PyTorch分布式训练基础--DDP使用:https://zhuanlan.zhihu.com/p/358974461














 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









