







参考https://redis.io/topics/cluster-tutorial
redis官网 版本6.2.6
主从复制
先查看内网ip
ifconfig

本文采用一台服务器,多个端口来实现
主 172.20.196.147 1234 文件夹/usr/local/redis/redis_master
从 172.20.196.147 1235 文件夹/usr/local/redis/redis_replicaof_1
从 172.20.196.147 1236 文件夹/usr/local/redis/redis_replicaof_2
下载并解压
mkdir -p /software
cd /software/
wget http://download.redis.io/releases/redis-6.2.6.tar.gz
tar -zxvf redis-6.2.6.tar.gz
移动并改名字
mkdir -p /usr/local/redis
mv redis-6.2.6 /usr/local/redis/redis_master
# 再次解压并移动
tar -zxvf redis-6.2.6.tar.gz
mv redis-6.2.6 /usr/local/redis/redis_replicaof_1
tar -zxvf redis-6.2.6.tar.gz
mv redis-6.2.6 /usr/local/redis/redis_replicaof_2
文件目录如下
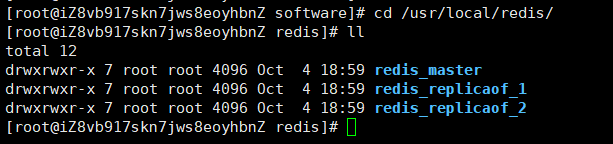
预编译并安装
cd /usr/local/redis/redis_master/
make && make install
cd /usr/local/redis/redis_replicaof_1/
make && make install
cd /usr/local/redis/redis_replicaof_2/
make && make install
master安装完的截图,其他类似
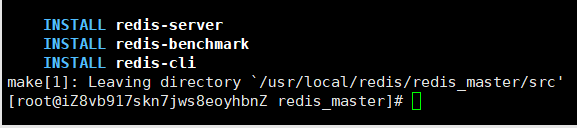
建立rdb和aof文件存放目录(假如有三台服务器,每个服务器建立一个目录即可)
mkdir -p /data/redis
cd /data/redis
mkdir master
mkdir replicaof_1
mkdir replicaof_2
改配置文件
密码一定要复杂,不然很容易被攻击
主redis
vim /usr/local/redis/redis_master/redis.conf
bind 172.20.196.147 #监听ip,多个ip用空格分隔
port 1234 #端口
daemonize yes #允许后台启动,默认no
dir /data/redis/master #数据文件存放目录
masterauth abc123 #repliacof连接master密码,master可省略
requirepass abc123 #设置master连接密码,slave可省略
appendonly yes #开启aof持久化,默认no
从1
vim /usr/local/redis/redis_replicaof_1/redis.conf
bind 172.20.196.147 #监听ip,多个ip用空格分隔
port 1235 #端口
daemonize yes #允许后台启动,默认no
dir /data/redis/replicaof_1 #数据文件存放目录
masterauth abc123 #repliacof连接master密码,master可省略
requirepass abc123 #设置master连接密码,slave可省略
appendonly yes #开启aof持久化,默认no
replicaof 172.20.196.147 1234 # 主redis的ip和端口
从2
vim /usr/local/redis/redis_replicaof_2/redis.conf
bind 172.20.196.147 #监听ip,多个ip用空格分隔
port 1236 #端口
daemonize yes #允许后台启动,默认no
dir /data/redis/replicaof_2 #数据文件存放目录
masterauth abc123 #repliacof连接master密码,master可省略
requirepass abc123 #设置master连接密码,slave可省略
appendonly yes #开启aof持久化,默认no
replicaof 172.20.196.147 1234 # 主redis的ip和端口
严格来讲应该是多台服务器,即ip不同
那么需要修改的配置主要是dir,不用建立多个文件夹了
设置密码masterauth和requirepass属性可以不一样,也可以不保留两个属性。
但是强烈建议两个密码一致,两个属性都保留,这样可以降低运维成本,并且在其他模式主redis挂了后,重新选取节点也需要密码才能连接
redis的日志文件默认在/dev/null目录下
启动
cd /usr/local/redis/redis_master/src/
./redis-server ../redis.conf
cd /usr/local/redis/redis_replicaof_1/src/
./redis-server ../redis.conf
cd /usr/local/redis/redis_replicaof_2/src/
./redis-server ../redis.conf
查看进程

连接redis
开两个窗口,都需要密码
cd /usr/local/redis/redis_master/src/
./redis-cli -h 172.20.196.147 -p 1234 -a abc123
info replication
keys *
查看从服务,connected_slaves 等于2表示有两个从服务

也没有任何键

再看从服务,没有任何键
cd /usr/local/redis/redis_replicaof_1/src/
./redis-cli -h 172.20.196.147 -p 1235 -a abc123
keys *

再看主服务,set一个键
set hello world
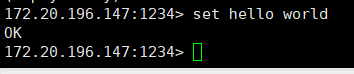
最后再看从服务
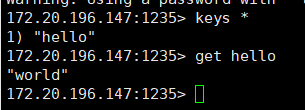
另一台1236的服务也一样
172.20.196.147:1236> set b2 jiucai
(error) READONLY You can't write against a read only replica.
172.20.196.147:1236>
从redis是不能写入的
假如有三台服务器,连不同的服务器其实改端口即可
哨兵(Sentinel)模式
哨兵模式提供了一下四种方式功能
- 监控(Monitoring):Sentinel不断的去检查你的主从实例是否按照预期在工作。
- 通知(Notification):Sentinel可以通过一个api来通知系统管理员或者另外的应用程序,被监控的Redis实例有一些问题。
- 自动故障转移Automatic failover):如果一个主节点没有按照预期工作,Sentinel会开始故障转移过程,把一个从节点提升为主节点,并重新配置其他的从节点使用新的主节点,使用Redis服务的应用程序在连接的时候也被通知新的地址。
- 配置提供者(Configuration provider):Sentinel给客户端的服务发现提供来源:对于一个给定的服务,客户端连接到Sentinels来寻找当前主节点的地址。当故障转移发生的时候,Sentinels将报告新的地址。
改配置
主节点21234
vim /usr/local/redis/redis_master/sentinel.conf
port 21234
# 后台启动
daemonize yes
# 日志
logfile "/usr/local/redis/redis_master/sentinel.log"
# sentinel工作目录
dir "/usr/local/redis/redis_master"
#判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数
sentinel monitor mymaster 172.20.196.147 1234 2
# 连接master的密码 即master的requirepass属性
sentinel auth-pass mymaster abc123
# 判断master主观下线时间,默认30s
sentinel down-after-milliseconds mymaster 30000
从节点21235
vim /usr/local/redis/redis_master/sentinel.conf
port 21235
# 后台启动
daemonize yes
# 日志
logfile "/usr/local/redis/redis_replicaof_1/sentinel.log"
# sentinel工作目录
dir "/usr/local/redis/redis_replicaof_1"
#判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数
sentinel monitor mymaster 172.20.196.147 1235 2
# 连接master的密码 即master的requirepass属性
sentinel auth-pass mymaster abc123
# 判断master主观下线时间,默认30s
sentinel down-after-milliseconds mymaster 30000
从节点21236
vim /usr/local/redis/redis_replicaof_2/sentinel.conf
port 21236
# 后台启动
daemonize yes
# 日志
logfile "/usr/local/redis/redis_replicaof_2/sentinel.log"
# sentinel工作目录
dir "/usr/local/redis/redis_replicaof_2"
#判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数
sentinel monitor mymaster 172.20.196.147 1234 2
# 连接master的密码 即master的requirepass属性
sentinel auth-pass mymaster abc123
# 判断master主观下线时间,默认30s
sentinel down-after-milliseconds mymaster 30000
启动
/usr/local/bin/redis-sentinel /usr/local/redis/redis_master/sentinel.conf
/usr/local/bin/redis-sentinel /usr/local/redis/redis_replicaof_1/sentinel.conf
/usr/local/bin/redis-sentinel /usr/local/redis/redis_replicaof_2/sentinel.conf
询问Sentinel关于主节点的状态
Sentinel开始启动的时候,要做的事情是检查主节点的监控是否正常:
我们通过redis客户端连接sentinel
[root@iZ8vb917skn7jws8eoyhbnZ ~]# cd /usr/local/redis/redis_master/src/
[root@iZ8vb917skn7jws8eoyhbnZ src]# ./redis-cli -p 21234
127.0.0.1:21234> sentinel master mymaster
1) "name"
2) "mymaster"
3) "ip"
4) "172.20.196.147"
5) "port"
6) "1234"
7) "runid"
8) "4f0ee6768a2c445629aa519dde82f526ce2a9273"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "774"
19) "last-ping-reply"
20) "774"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "6235"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "61982664"
29) "config-epoch"
30) "0"
31) "num-slaves"
32) "2"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "180000"
39) "parallel-syncs"
40) "1"
127.0.0.1:21234>
- num-other-sentinels 是2,所以我们知道对于这个主节点Sentinel已经发现了两个以上的Sentinels。如果你检查日志,你可以看到+sentinel事件发生。
- flags是master。如果主节点挂掉了,我们可以看到sdown或者odown标志。
- num-slaves现在是2,所以Sentinel发现有两个从节点。
更多信息尝试以下两个命令(信息太多不展示了)
sentinel slaves mymaster # 提供关于从节点类似的信息
sentinel sentinels mymaster # 关于另外的Sentinels。
查看主节点
127.0.0.1:21234> sentinel get-master-addr-by-name mymaster
1) "172.20.196.147"
2) "1234"
127.0.0.1:21234>
当然,也可以通过查看日志方式来看sentinel(不推荐,太复杂了)
查看哨兵的日志文件
cat /usr/local/redis/redis_master/sentinel.log
cat /usr/local/redis/redis_replicaof_1/sentinel.log
cat /usr/local/redis/redis_replicaof_2/sentinel.log
17640:X 08 Nov 2021 11:16:20.180 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
17640:X 08 Nov 2021 11:16:20.180 # Redis version=6.2.6, bits=64, commit=00000000, modified=0, pid=17640, just started
17640:X 08 Nov 2021 11:16:20.180 # Configuration loaded
17640:X 08 Nov 2021 11:16:20.181 * monotonic clock: POSIX clock_gettime
17640:X 08 Nov 2021 11:16:20.182 * Running mode=sentinel, port=26379.
17640:X 08 Nov 2021 11:16:20.182 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
17640:X 08 Nov 2021 11:16:20.185 # Sentinel ID is 6cf20b9ce6d5afb13b9747afa6e36e2c67fdd881
17640:X 08 Nov 2021 11:16:20.185 # +monitor master mymaster 172.20.196.147 1234 quorum 2
17640:X 08 Nov 2021 11:16:20.186 * +slave slave 172.20.196.147:1235 172.20.196.147 1235 @ mymaster 172.20.196.147 1234
17640:X 08 Nov 2021 11:16:20.189 * +slave slave 172.20.196.147:1236 172.20.196.147 1236 @ mymaster 172.20.196.147 1234
日志文件各参数详解
| 关键字 | 详解 |
|---|---|
| +reset-master | 主服务器已被重置 |
| +slave | 一个新的从服务器已经被 Sentinel 识别并关联 |
| +failover-state-reconf-slaves | 故障转移状态切换到了 reconf-slaves 状态 |
| +failover-detected | 另一个 Sentinel 开始了一次故障转移操作,或者一个从服务器转换成了主服务器 |
| +slave-reconf-sent | 领头(leader)的 Sentinel 向实例发送了 SLAVEOF 命令,为实例设置新的主服务器 |
| +slave-reconf-inprog | 实例正在将自己设置为指定主服务器的从服务器,但相应的同步过程仍未完成 |
| +slave-reconf-done | 从服务器已经成功完成对新主服务器的同步 |
| -dup-sentinel | 对给定主服务器进行监视的一个或多个 Sentinel 已经因为重复出现而被移除 —— 当 Sentinel 实例重启的时候,就会出现这种情况 |
| +sentinel | 一个监视给定主服务器的新 Sentinel 已经被识别并添加 |
| +sdown | 给定的实例现在处于主观下线状态 |
| -sdown | 给定的实例已经不再处于主观下线状态 |
| +odown | 给定的实例现在处于客观下线状态 |
| -odown | 给定的实例已经不再处于客观下线状态 |
| +new-epoch | 当前的纪元(epoch)已经被更新 |
| +try-failover | 一个新的故障迁移操作正在执行中,等待被大多数 Sentinel 选中(waiting to be elected by the majority) |
| +elected-leader | 赢得指定纪元的选举,可以进行故障迁移操作了 |
| +failover-state-select-slave | 故障转移操作现在处于 select-slave 状态 —— Sentinel 正在寻找可以升级为主服务器的从服务器 |
| no-good-slave | Sentinel 操作未能找到适合进行升级的从服务器 |
| selected-slave | Sentinel 顺利找到适合进行升级的从服务器 |
| failover-state-send-slaveof-noone | Sentinel 正在将指定的从服务器升级为主服务器,等待升级功能完成 |
| failover-end-for-timeout | 故障转移因为超时而中止,不过最终所有从服务器都会开始复制新的主服务器(slaves will eventually be configured to replicate with the new master anyway) |
| failover-end | 故障转移操作顺利完成 |
| +switch-master | 配置变更,主服务器的 IP 和地址已经改变 |
| +tilt | 进入 tilt 模式 |
| -tilt | 退出 tilt 模式 |
故障转移测试
查看进程,结束进程


重新询问mymaster的当前主节点的地址,变成1236了
127.0.0.1:21234> sentinel get-master-addr-by-name mymaster
1) "172.20.196.147"
2) "1236"
127.0.0.1:21234>
再看日志文件
[root@iZ8vb917skn7jws8eoyhbnZ redis_replicaof_1]# cat sentinel.log
2510:X 08 Nov 2021 17:05:44.574 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2510:X 08 Nov 2021 17:05:44.574 # Redis version=6.2.6, bits=64, commit=00000000, modified=0, pid=2510, just started
2510:X 08 Nov 2021 17:05:44.574 # Configuration loaded
2510:X 08 Nov 2021 17:05:44.575 * monotonic clock: POSIX clock_gettime
2510:X 08 Nov 2021 17:05:44.576 * Running mode=sentinel, port=21235.
2510:X 08 Nov 2021 17:05:44.576 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
2510:X 08 Nov 2021 17:05:44.579 # Sentinel ID is 4a1f5f58b2766851d410c504375e1a53c51df31b
2510:X 08 Nov 2021 17:05:44.579 # +monitor master mymaster 172.20.196.147 1234 quorum 2
2510:X 08 Nov 2021 17:05:44.579 * +slave slave 172.20.196.147:1236 172.20.196.147 1236 @ mymaster 172.20.196.147 1234
2510:X 08 Nov 2021 17:05:44.582 * +slave slave 172.20.196.147:1235 172.20.196.147 1235 @ mymaster 172.20.196.147 1234
2510:X 08 Nov 2021 17:05:45.147 * +sentinel sentinel 6cf20b9ce6d5afb13b9747afa6e36e2c67fdd881 172.20.196.147 26379 @ mymaster 172.20.196.147 1234
2510:X 08 Nov 2021 17:07:45.469 # +sdown sentinel 6cf20b9ce6d5afb13b9747afa6e36e2c67fdd881 172.20.196.147 26379 @ mymaster 172.20.196.147 1234
2510:X 08 Nov 2021 17:09:36.175 * +sentinel-address-switch master mymaster 172.20.196.147 1234 ip 172.20.196.147 port 21234 for 6cf20b9ce6d5afb13b9747afa6e36e2c67fdd881
2510:X 08 Nov 2021 17:20:04.511 * +sentinel sentinel ca51dfd168a848e19219718abf88c955e4f2b0ba 172.20.196.147 21236 @ mymaster 172.20.196.147 1234
2510:X 09 Nov 2021 14:52:37.375 # +sdown master mymaster 172.20.196.147 1234
2510:X 09 Nov 2021 14:52:37.410 # +new-epoch 1
2510:X 09 Nov 2021 14:52:37.413 # +vote-for-leader 6cf20b9ce6d5afb13b9747afa6e36e2c67fdd881 1
2510:X 09 Nov 2021 14:52:37.447 # +odown master mymaster 172.20.196.147 1234 #quorum 3/2
2510:X 09 Nov 2021 14:52:37.447 # Next failover delay: I will not start a failover before Tue Nov 9 14:58:37 2021
2510:X 09 Nov 2021 14:52:38.420 # +config-update-from sentinel 6cf20b9ce6d5afb13b9747afa6e36e2c67fdd881 172.20.196.147 21234 @ mymaster 172.20.196.147 1234
2510:X 09 Nov 2021 14:52:38.420 # +switch-master mymaster 172.20.196.147 1234 172.20.196.147 1236
2510:X 09 Nov 2021 14:52:38.420 * +slave slave 172.20.196.147:1235 172.20.196.147 1235 @ mymaster 172.20.196.147 1236
2510:X 09 Nov 2021 14:52:38.420 * +slave slave 172.20.196.147:1234 172.20.196.147 1234 @ mymaster 172.20.196.147 1236
2510:X 09 Nov 2021 14:53:08.452 # +sdown slave 172.20.196.147:1234 172.20.196.147 1234 @ mymaster 172.20.196.147 1236
[root@iZ8vb917skn7jws8eoyhbnZ redis_replicaof_1]#

五个红框
- 每个Sentinel发现了主节点挂掉了并有一个+sdown事件
- 这个事件稍候升级到+odown,意味着大多数Sentinel已经同意了主节点是不可达的。
- Sentinels开始投票一个Sentinel(21234端口的节点)开始并尝试故障转移
- 故障转移开始(端口1236的从节点变为主节点,其他节点的配置文件的replicaof 属性端口改为1236)
- 大概一分钟后1234节点处于主观下线状态
重新启动1234节点
cd /usr/local/redis/redis_master/src/
./redis-server ../redis.conf
再看从节点的信息,1234端口已经变成从节点了

本文使用的一台服务器,生产建议将Sentinel放在不同的服务器,这样不至于一台服务器要挂都挂了
哨兵就到这里,再详细的大家就去官网学习吧
集群(cluster)模式
哨兵模式基本满足普通项目的需求了,并且具备高可用性。但是当数据量过大到一台服务器存放不下的情况时,主从模式或哨兵模式就不能满足需求了,这个时候需要对存储的数据进行分片,将数据存储到多个Redis实例中。集群模式的出现就是为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。
集群之间使用二进制协议(不同于跟客户端通信协议)来进行节点之间数据交换,这个协议更适合节点间使用小的带宽和处理时间来交换数据。
我们采用6个节点,3主3从(最低配置)建议放在不同的6台服务器上
这次启动方式采用一个redis服务,分别配置不同conf文件来启动,配置多个redis服务太繁琐了,工作目录(dir)也配置一个目录了(一般情况是配置再/data目录下的,这样方便扩容加硬盘)
下载、解压、移动、改名字、建多个文件夹
mkdir -p /software
cd /software/
wget http://download.redis.io/releases/redis-6.2.6.tar.gz
tar -zxvf redis-6.2.6.tar.gz
mkdir -p /usr/local/redis
mv redis-6.2.6 /usr/local/redis
cd /usr/local/redis
mkdir conf_7001 conf_7002 conf_7003 conf_7004 conf_7005 conf_7006
然后如下图

预编译安装、复制conf文件并修改配置(演示一个其他类似)
cd /usr/local/redis/redis-6.2.6/
make && make install
cp /usr/local/redis/redis-6.2.6/redis.conf /usr/local/redis/conf_7001
vim /usr/local/redis/conf_7001/redis.conf
bind非常重要默认ip为127.0.0.1 需要改为其他节点机器可访问的ip 严重时创建集群时无法访问对应的端口,无法创建集群,不严重时无法自动分配哈希槽
bind 172.20.196.147
port 7001
daemonize yes
# 以守护进程方式运行时,默认会把pid写入/var/run/redis-_6379.pid,可以通过pidfile指定pid文件
pidfile /usr/local/redis/conf_7001/redis.pid
# 日志文件
logfile "/usr/local/redis/conf_7001/redis.log"
# 工作目录
dir /usr/local/redis/conf_7001
masterauth "123456"
requirepass "123456"
appendonly yes
# 开启集群模式
cluster-enabled yes
# 用于存储此节点的一些配置信息。这个配置文件由redis集群的节点自行创建和更新,不能由人手动地去修改。
cluster-config-file nodes.conf
cluster-node-timeout 5000
redis集群配置文件详解
- cluster-enabled <yes/no>: 如果配置"yes"则开启集群功能,此redis实例作为集群的一个节点,否则,它是一个普通的单一的redis实例。
cluster-config-file : 注意:虽然此配置的名字叫"集群配置文件",但是此配置文件不能人工编辑,它是集群节点自动维护的文件,主要用于记录集群中有哪些节点、他们的状态以及一些持久化参数等,方便在重启时恢复这些状态。通常是在收到请求之后这个文件就会被更新。 - cluster-node-timeout : 这是集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。如果主节点超过这个时间还是不可达,则用它的从节点将启动故障迁移,升级成主节点。注意,任何一个节点在这个时间之内如果还是没有连上大部分的主节点,则此节点将停止接收任何请求。
- cluster-replica-validity-factor : 【从节点多长时间连接主节点】如果设置成0,则无论从节点与主节点失联多久,从节点都会尝试升级成主节点。如果设置成正数,则cluster-node-timeout乘以cluster-replica-validity-factor得到的时间,是从节点与主节点失联后,此从节点数据有效的最长时间,超过这个时间,从节点不会启动故障迁移。假设cluster-node-timeout=5000,cluster-slave-validity-factor=10,则如果从节点跟主节点失联超过50秒,此从节点不能成为主节点。注意,如果此参数配置为非0,将可能出现由于某主节点失联却没有从节点能顶上的情况,从而导致集群不能正常工作,在这种情况下,只有等到原来的主节点重新回归到集群,集群才恢复运作。
- cluster-migration-barrier :主节点需要的最小从节点数,只有达到这个数,主节点失败时,它从节点才会进行迁移。更详细介绍可以看本教程后面关于副本迁移到部分。
cluster-require-full-coverage <yes/no>:在部分key所在的节点不可用时,如果此参数设置为"yes"(默认值), 则整个集群停止接受操作;如果此参数设置为"no",则集群依然为可达节点上的key提供读操作。
分别启动6个节点
cd /usr/local/redis/redis-6.2.6/src/
./redis-server /usr/local/redis/conf_7001/redis.conf
如图所示

现在6个节点是没什么关系的,我们需要创建集群把他们都关联起来
redis-cli -h 172.20.196.147 -a 123456 --cluster create 172.20.196.147:7001 172.20.196.147:7002 172.20.196.147:7003 172.20.196.147:7004 172.20.196.147:7005 172.20.196.147:7006 --cluster-replicas 1
选项 -a是密码
选项 --cluster create参数是要创建的集群中各实例的地址列表
选项 --cluster-replicas 1 表示为每一个主服务器配一个从服务器
也就是有3个主节点和3个从节点。
redis-cli 会给我们一些配置建议,输入yes表示接受。集群会被配置并彼此连接好,意思是各节点实例被引导彼此通话并最终形成集群。
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.20.196.147:7005 to 172.20.196.147:7001
Adding replica 172.20.196.147:7006 to 172.20.196.147:7002
Adding replica 172.20.196.147:7004 to 172.20.196.147:7003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 1c477df255d350d5603124bf3b663f57c70a3354 172.20.196.147:7001
slots:[0-5460] (5461 slots) master
M: 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b 172.20.196.147:7002
slots:[5461-10922] (5462 slots) master
M: caf535d9dd5377277455820ee0a1a14d85989859 172.20.196.147:7003
slots:[10923-16383] (5461 slots) master
S: b29d51e2dfa6b44e9351044666782192f6f88038 172.20.196.147:7004
replicates 1c477df255d350d5603124bf3b663f57c70a3354
S: f63297992b07ab165239bcebb10909aba69e06bf 172.20.196.147:7005
replicates 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b
S: 6bc40e858f3d72df80659fe11dbd7ab2872290d6 172.20.196.147:7006
replicates caf535d9dd5377277455820ee0a1a14d85989859
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing Cluster Check (using node 172.20.196.147:7001)
M: 1c477df255d350d5603124bf3b663f57c70a3354 172.20.196.147:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b 172.20.196.147:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: caf535d9dd5377277455820ee0a1a14d85989859 172.20.196.147:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 6bc40e858f3d72df80659fe11dbd7ab2872290d6 172.20.196.147:7006
slots: (0 slots) slave
replicates caf535d9dd5377277455820ee0a1a14d85989859
S: f63297992b07ab165239bcebb10909aba69e06bf 172.20.196.147:7005
slots: (0 slots) slave
replicates 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b
S: b29d51e2dfa6b44e9351044666782192f6f88038 172.20.196.147:7004
slots: (0 slots) slave
replicates 1c477df255d350d5603124bf3b663f57c70a3354
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@iZ8vb917skn7jws8eoyhbnZ src]#

最后,如果一切顺利,会看到类似下面的信息:[OK] All 16384 slots covered这表示,16384个哈希槽都被主节点正常服务着

可以看出主从对应的端口
| 主 | 从 |
|---|---|
| 7001 | 7004 |
| 7002 | 7005 |
| 7003 | 7006 |
| 随便看一个目录,节点相关的文件都在这里了 | |
 |
操作集群
./redis-cli -c -h 172.20.196.147 -a 123456 -p 7001
选项-c集群支持开关
查看集群信息cluster info
查看节点信息cluster nodes
- 节点参数信息如下
节点编号
ip:端口
标志:主人,奴隶,我自己,失败,…
如果是slave,则master的Node ID
最后一个等待回复的 PING 的时间。
最后一次收到 PONG 的时间。
此节点的配置时期(请参阅集群规范)。
此节点的链接状态。
插槽服务…
设置一个值
[root@iZ8vb917skn7jws8eoyhbnZ src]# ./redis-cli -c -h 172.20.196.147 -a 123456 -p 7001
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
172.20.196.147:7001> set aba txtgif
-> Redirected to slot [15764] located at 172.20.196.147:7003
OK
172.20.196.147:7003> set hello world
-> Redirected to slot [866] located at 172.20.196.147:7001
OK
172.20.196.147:7001> get hello
"world"
172.20.196.147:7001> get aba
-> Redirected to slot [15764] located at 172.20.196.147:7003
"txtgif"
172.20.196.147:7003>
7003跳到7001
7001又跳到7003
这里的都是主节点,从节点不提供服务,只是用来备份的
增加一个master节点
复制需要的配置文件,启动
cd /usr/local/redis/
cp -r conf_7001/ conf_7007
vim /usr/local/redis/conf_7007/redis.conf
# 把所有7001改成7007
# 删除没有用的文件
cd /usr/local/redis/conf_7007
rm -rf appendonly.aof
rm -rf dump.rdb
rm -rf nodes.conf
# 启动
cd /usr/local/redis/redis-6.2.6/src/
./redis-server /usr/local/redis/conf_7007/redis.conf
将新节点添加到集群
redis-cli --cluster add-node 172.20.196.147:7007 172.20.196.147:7007 --cluster-slave
这样直接添加节点是不行的,因为我增加了密码验证,包括上面那个也是

所以要改
- add-node 前面的参数是我开启了密码验证,需要连接一个节点才能操作
- add-node 后面第一个参数是要添加的节点信息,第二个是谁便一个节点信息
./redis-cli -c -h 172.20.196.147 -a 123456 -p 7001 --cluster add-node 172.20.196.147:7007 172.20.196.147:7001
执行后如图所示

再看一下节点信息, 7007是没有哈希槽的,所以当slave想成为master时它不参与选举过程。所以需要重新分片,后面说

增加一个slave节点
按上面复制一份端口为7008文件启动
cluster-master-id 是要添加的主节点id,可以通过cluster nodes命令来看,其他信息和上面的一样
redis-cli -c -h 172.20.196.147 -a 123456 -p 7001 --cluster add-node 172.20.196.147:7008 172.20.196.147:7001 --cluster-slave --cluster-master-id 09076535b22ad170a8ca5aae62f03b7248afd4d7


重新分片
命令格式
redis-cli --cluster reshard <host>:<port> --cluster-from <node-id> --cluster-to <node-id> --cluster-slots <number of slots> --cluster-yes
要执行的命令
./redis-cli -c -h 172.20.196.147 -a 123456 -p 7001 --cluster reshard 172.20.196.147:7001 --cluster-from all --cluster-to 09076535b22ad170a8ca5aae62f03b7248afd4d7 --cluster-slots 12 --cluster-yes
我们吧从新分配的哈希槽分到刚才建立的7007和7008节点上
| 命令 | 意思 |
|---|---|
| host:port | 这个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口。 |
| –cluster-from | 需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递–cluster-from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入。all代表所有节点 |
| –cluster-to | slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入。 |
| –cluster-slots | 需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。 |
| –cluster-yes | 设置该参数,可以在打印执行reshard计划的时候,提示用户输入yes确认后再执行reshard。 |
| –timeout | 设置migrate命令的超时时间。 |
| –cluster-pipeline | 定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10。 |
执行信息如下
[root@iZ8vb917skn7jws8eoyhbnZ src]# ./redis-cli -c -h 172.20.196.147 -a 123456 -p 7001 --cluster reshard 172.20.196.147:7001 --cluster-from all --cluster-to 09076535b22ad170a8ca5aae62f03b7248afd4d7 --cluster-slots 12 --cluster-yes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 172.20.196.147:7001)
M: 1c477df255d350d5603124bf3b663f57c70a3354 172.20.196.147:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b 172.20.196.147:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 4f7d009c0bc0b54f8ca48df7459055a2bbdc8d2b 172.20.196.147:7008
slots: (0 slots) slave
replicates 09076535b22ad170a8ca5aae62f03b7248afd4d7
M: caf535d9dd5377277455820ee0a1a14d85989859 172.20.196.147:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 09076535b22ad170a8ca5aae62f03b7248afd4d7 172.20.196.147:7007
slots: (0 slots) master
1 additional replica(s)
S: 6bc40e858f3d72df80659fe11dbd7ab2872290d6 172.20.196.147:7006
slots: (0 slots) slave
replicates caf535d9dd5377277455820ee0a1a14d85989859
S: f63297992b07ab165239bcebb10909aba69e06bf 172.20.196.147:7005
slots: (0 slots) slave
replicates 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b
S: b29d51e2dfa6b44e9351044666782192f6f88038 172.20.196.147:7004
slots: (0 slots) slave
replicates 1c477df255d350d5603124bf3b663f57c70a3354
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
Ready to move 12 slots.
Source nodes:
M: 1c477df255d350d5603124bf3b663f57c70a3354 172.20.196.147:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b 172.20.196.147:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: caf535d9dd5377277455820ee0a1a14d85989859 172.20.196.147:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
Destination node:
M: 09076535b22ad170a8ca5aae62f03b7248afd4d7 172.20.196.147:7007
slots: (0 slots) master
1 additional replica(s)
Resharding plan:
Moving slot 5461 from 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b
Moving slot 5462 from 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b
Moving slot 5463 from 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b
Moving slot 5464 from 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b
Moving slot 5465 from 9b2eaa5d91f3cad662c35c8d33d1c1d7de04ec9b
Moving slot 0 from 1c477df255d350d5603124bf3b663f57c70a3354
Moving slot 1 from 1c477df255d350d5603124bf3b663f57c70a3354
Moving slot 2 from 1c477df255d350d5603124bf3b663f57c70a3354
Moving slot 10923 from caf535d9dd5377277455820ee0a1a14d85989859
Moving slot 10924 from caf535d9dd5377277455820ee0a1a14d85989859
Moving slot 10925 from caf535d9dd5377277455820ee0a1a14d85989859
Moving slot 5461 from 172.20.196.147:7002 to 172.20.196.147:7007:
Moving slot 5462 from 172.20.196.147:7002 to 172.20.196.147:7007:
Moving slot 5463 from 172.20.196.147:7002 to 172.20.196.147:7007:
Moving slot 5464 from 172.20.196.147:7002 to 172.20.196.147:7007:
Moving slot 5465 from 172.20.196.147:7002 to 172.20.196.147:7007:
Moving slot 0 from 172.20.196.147:7001 to 172.20.196.147:7007:
Moving slot 1 from 172.20.196.147:7001 to 172.20.196.147:7007:
Moving slot 2 from 172.20.196.147:7001 to 172.20.196.147:7007:
Moving slot 10923 from 172.20.196.147:7003 to 172.20.196.147:7007:
Moving slot 10924 from 172.20.196.147:7003 to 172.20.196.147:7007:
Moving slot 10925 from 172.20.196.147:7003 to 172.20.196.147:7007:
[root@iZ8vb917skn7jws8eoyhbnZ src]#
再次查看节点信息,0-2 5461-5465 10923-10925是重新分配的哈希槽

检查集群健康
redis-cli -c -h 172.20.196.147 -a 123456 -p 7001 --cluster check 172.20.196.147:7001
模拟故障转移
先看下节点信息

杀死一个进程7003master节点

再看信息,7003fail了,7006变为了master节点,没有从节点

重新启动
cd /usr/local/redis/redis-6.2.6/src/
./redis-server /usr/local/redis/conf_7003/redis.conf

再看集群节点信息,发现7003变为了7006的从节点

删除一个节点
redis-cli --cluster del-node 127.0.0.1:7000 <node-id>















 7231
7231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









