






A SubMatrix××
题目链接:
http://acm.buaa.edu.cn/problem/879/
本题的分析可以从诸多方面入手,描述方法也有许多不同的视角(诸如集合的容斥原理、二维离散概率分布的概率计算等),为了方便理解,这里以最简明易懂的方式来解释:
首先如下如所示,现假设现在我们拥有矩阵S(如下图右所示),其中可以进一步分隔为如下图左所示的四个子矩阵,我们要求的是S4矩阵的元素和。

然后在考虑解决方案的过程中,不难发现,求从(1,1)到(i,j)的这样一个子矩阵的元素和是可以通过预处理实现的。由于输入的顺序为从左上到右下的依次输入,我们很容易得到一个递推公式:

其中S[i][j]为从(1,1)到(i,j)的这样一个子矩阵的元素和。由上图左可以得到该公式的解释,大家可以尝试理解一下。
以上就是预处理部分的全部原理。
计算中公式仍然从上图左那个有如codeblock一样的图中得出:

由于原理与上面的公式基本一致,这里不作阐述,请大家根据前式的推导,自行推导该式。
参考代码
//by trashLHC
#include<iostream>
#include<cstdio>
#include<cstring>
#defineMAXN 1001
usingnamespace std;
longlong S[MAXN][MAXN];
intmain(){
int m,n,k;
while(~scanf("%d%d%d",&m,&n,&k)){
memset(S,0,sizeof(S));
for(int i=1;i<=m;i++)//下标特点
for(int j=1;j<=n;j++){
scanf("%lld",&S[i][j]);
S[i][j]+=S[i-1][j]+S[i][j-1]-S[i-1][j-1];
}//考虑为什么这样的预处理是可以的
while(k--){
int c1,c2,r1,r2;
scanf("%d%d%d%d",&c1,&c2,&r1,&r2);
printf("%lld\n",S[r2][c2]-S[r1-1][c2]-S[r2][c1-1]+S[r1-1][c1-1]);
}//计算公式
}
return 0;
}B SubMatrix×××××
题目链接:
http://acm.buaa.edu.cn/problem/880/
解题分析
本题与A题预处理和计算部分稍稍差了一些,但是原理基本一致。
考虑到A[i][j]是一个不超过10的正整数,因此我们不妨将S[i][j]改写为S[i][j][k],用来表示从(1,1)到(i,j)这样一个子矩阵中数字k的个数,计算S[i][j][k]的方式与A题相同,由于k仅仅为从0到9的数,因此添加一层循环不会增加时间复杂度的数量级。
为什么要进行上面的预处理呢?因为我们可以将本题转化一下思路,从计算不同元素的个数,来判断从0-9的每一个Unique的数字是否在子矩阵中出现,只要出现,便是一个不同的元素。
于是再一次考察下面这个矩阵,若我们想求S4矩阵中不同元素的个数,那么对于任意k,我们再次运用A题中得到的公式:
这个公式的目的是判断S4中是否存在k这个数字(公式计算的是数字k在S4中的个数),因为一旦存在数字k,那么它必然为一个Unique的元素,于是计数器加一。

于是本题得解,具体见参考代码。
//by trashLHC
#include <cstdio>
#include <cstring>
#define MAXN 521
#define MAX 10
short rec[MAXN][MAXN][MAX];
short data;
int main() {
int m,n,q;
while(~scanf("%d%d%d",&m,&n,&q)){
memset(rec,0,sizeof(rec));
for(int i=1;i<=m;i++)
for(int j=1;j<=n;j++){
scanf("%d",&data);
rec[i][j][data]++;
for(int k=0;k<MAX;k++)//预处理部分
rec[i][j][k]+=rec[i-1][j][k]+rec[i][j-1][k]-rec[i-1][j-1][k];
}
while(q--){
int x1,y1,x2,y2,ans=0;
scanf("%d%d%d%d",&x1,&y1,&x2,&y2);
for(int i=0;i<MAX;i++)//计算每个Unique的数字是否出现在子矩阵中
ans+=rec[x2][y2][i]-rec[x1-1][y2][i]-rec[x2][y1-1][i]+rec[x1-1][y1-1][i]>0;
printf("%d\n",ans);
}
}
return 0;
}
C 微软( ⊙ o ⊙ )啊!
题目链接:
http://acm.buaa.edu.cn/problem/203/
解题分析
首先表明,由于本题未对线性表进行插入与删除操作,因此此题无论是顺序表还是链表均可实现。
但是本题既然已经明确要求用链表解决,那就不妨来用链表吧……首先刚入手看到这题的第一反应很容易变为对整个表的一个大规模元素挪动,然而这样的处理需要很大的计算量,以本题的数据量来说,是不合适的。
于是重新审视本题,请注意题目之中多次强调一个词——移动。于是不妨考虑,如果不去修改表,而仅仅是使用一个指向链表节点的指针,移动指针,来实现本题要求的模拟,则何如?
干得漂亮——
于是我们使用循环链表外带指针的移动来实现本题。在模拟的过程之中,指针的移动无论是向左还是向右都是可行的。假设链表的长度为n,移动次数为t,那么如果指针向左平移,那么就是t%n,且需要双链表;如果向右,就是n-t%n,且仅需要单链表。
这里我们取了一个模,因为什么?
因为地球是圆的!
//by trashLHC
//单链表版
#include<iostream>
#include<cstdio>
#include<cstdlib>
using namespace std;
typedef char ElemType;
typedef struct Node
{
ElemType data;
struct Node *next;
}LinkList;
void CreateListR(LinkList * &L,int n)
{
LinkList *s,*r;
L=new LinkList;
r=L;
for(int i=0;i<n;i++)
{
s=new LinkList;
scanf("%c",&s->data);
r->next=s;
r=s;
}
r->next=L->next;
}
void DispList(LinkList *r,int n)
{
for(int s=0;s<n;s++)
{
printf("%c",r->data);
r=r->next;
}
printf("\n");
}
void ShiftDList(LinkList *L,int n,int ShiftTime)
{
LinkList *r=L->next;
for(int i=0;i<ShiftTime;i++)
r=r->next;
DispList(r,n);
}
void DestroyDList(LinkList *&L,int n)
{
LinkList *pre=L->next,*p;
for(int i=0;i<n;i++){
p=pre->next;
free(pre);
pre=p;
}
free(L);
}
int main()
{
int t,num,time;
scanf("%d",&t);
while(t--)
{
scanf("%d%d",&num,&time);
getchar();
LinkList *LA;
CreateListR(LA,num);
ShiftDList(LA,num,num-time%num);
DestroyDList(LA,num);
}
}//by trashLHC
//双链表版
#include<iostream>
#include<cstdio>
#include<cstdlib>
using namespace std;
typedef char ElemType;
typedef struct DNode
{
ElemType data;
struct DNode *next;
struct DNode *prior;
}DLinkList;
void CreateListR(DLinkList * &L,int n)
{
DLinkList *s,*r;
int i;
L=(DLinkList *)malloc(sizeof(DLinkList));
r=L;
for(i=0;i<n;i++)
{
s=(DLinkList *)malloc(sizeof(DLinkList));
scanf("%c",&s->data);
r->next=s;
s->prior=r;
r=s;
}
r->next=L->next;
(L->next)->prior=r;
}
void DispList(DLinkList *r,int n)
{
for(int s=0;s<n;s++)
{
printf("%c",r->data);
r=r->next;
}
printf("\n");
}
void ShiftDList(DLinkList *L,int n,int ShiftTime)
{
DLinkList *r=L->next;
for(int i=0;i<ShiftTime;i++)
r=r->prior;
DispList(r,n);
}
void DestroyDList(DLinkList *&L,int n)
{
DLinkList *pre=L->next,*p;
for(int i=0;i<n;i++){
p=pre->next;
free(pre);
pre=p;
}
free(L);
}
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
int num;
long long time;
scanf("%d%lld",&num,&time);
getchar();
DLinkList *LA;
CreateListR(LA,num);
ShiftDList(LA,num,time%num);
DestroyDList(LA,num);
}
}D Who Should I Accompany?(Ⅰ)
题目链接:
http://acm.buaa.edu.cn/contest/133/problem/D/
解题分析
基础约瑟夫问题,在熟练掌握链表的情况下实际上为一道经典的简单题目。考察循环链表的掌握以及一些链表上的基础操作。
实现没什么可说的,纯粹的模拟,这里参见下面提供的代码。
但是值得注意的是,本题涉及了两个十分有趣的问题:
① 表的头结点(L)是否可以存储数据?
② 如果①的答案为可以,那么在这种情况下,循环链表应该如何写?
为什么会提出这样两个问题?这里不作解释,但是下面向大家展示几种基于这两个问题的链表逻辑结构,其中会出现一个很明显的问题,请大家尝试通过程序模拟,从其中发掘问题。
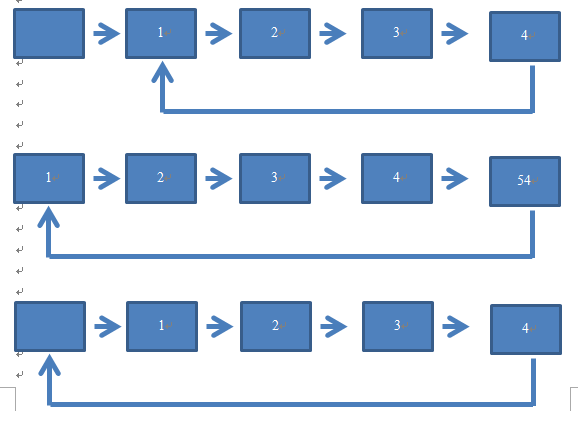
P.S.
约瑟夫问题变种花样极多,此后或许重出江湖,请诸君正视。//A piece of trash by trashLHC
#include<cstdio>
#include<cstdlib>
using namespace std;
typedef int ElemType;
typedef struct DNode
{
ElemType data;
DNode *next;
DNode *prior;
}DLinkList;
void CreateListR(DLinkList * &L,int n)
{
DLinkList *s,*r;
int i;
L=(DLinkList *)malloc(sizeof(DLinkList));
L->prior=NULL;
L->next=NULL;
r=L;
for(i=0;i<n;i++)
{
s=(DLinkList *)malloc(sizeof(DLinkList));
s->data=i+1;
r->next=s;
s->prior=r;
r=s;
}
r->next=L->next;
(L->next)->prior=r;
}
void CountDownDList(DLinkList *L,int n,int DeathNumber)
{
DLinkList *r=L->next;
DLinkList *s;
int DeathCounter=0;
while(n!=1)
{
DeathCounter++;
s=r->next;
if(DeathCounter==DeathNumber)
{
(r->prior)->next=s;
s->prior=r->prior;
free(r);
DeathCounter=0;
n--;
}
r=s;
}
printf("%d\n",r->data);
}
int main()
{
int num,time;
while(~scanf("%d%d",&num,&time)){
DLinkList *LA;
CreateListR(LA,num);
CountDownDList(LA,num,time);
//这里为什么不销毁表?
}
}
E 线性表操作
题目链接:
http://acm.buaa.edu.cn/contest/133/problem/E/
解题分析
似乎……没什么可说的……这题考的就是书上线性表基础操作的使用,大家看书吧……
(为了帮助理解,下面的代码提供了相对较为明了的算法......虽然被一些同学指出不符合面向对象的风格.....嘛>.<)
//by trashLHC
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<string>
#include<iostream>
using namespace std;
#define MaxSize 3000
typedef int ElemType;
typedef struct
{
ElemType data[MaxSize];
int length;
}SqList;
void InitList(SqList *L)
{
L=(SqList *)malloc(sizeof(SqList));
L->length=0;
}
void CreateList(SqList * &L,int n)
{
int i;
L=(SqList *)malloc(sizeof(SqList));
for(i=0;i<n;i++)
cin>>L->data[i];
L->length=n;
}
void DestroyList(SqList *L)
{
free(L);
}
void DispList(SqList *L)
{
int i;
for(i=0;i<L->length;i++)
{
if(i!=L->length-1)
cout<<L->data[i]<<" ";
else
cout<<L->data[i]<<endl;
}
}
void ListInsert(SqList * &L,int i,ElemType e)
{
int j;
if(i<1||i>L->length+1)
cout<<"Wrong Input!\n";
else
{
i--;
for(j=L->length;j>i;j--)
L->data[j]=L->data[j-1];
L->data[i]=e;
L->length++;
DispList(L);
}
}
void ListDelete(SqList * &L,int i)
{
int j;
if(i<1||i>L->length)
cout<<"Wrong Input!\n";
else
{
i--;
for(j=i;j<L->length-1;j++)
L->data[j]=L->data[j+1];
L->length--;
DispList(L);
}
}
int LocateElem(SqList *L,ElemType e)
{
int i=0;
while(i<L->length&&L->data[i]!=e)
i++;
if(i>=L->length)
return 0;
else
return i+1;
}
void GetElem(SqList *L,int i)
{
if(i<1||i>L->length)
cout<<"Wrong Input!\n";
else
cout<<L->data[i-1]<<endl;
}
int main()
{
int n,m;
while(cin>>n>>m)
{
SqList *LA;
CreateList(LA,n);
while(m--)
{
string mal;
cin>>mal;
if(mal=="Insert")
{
int x,y;
cin>>x>>y;
ListInsert(LA,x,y);
}
else if(mal=="Delete")
{
int num0;
cin>>num0;
ListDelete(LA,LocateElem(LA,num0));
}
else if(mal=="Locate")
{
int number;
cin>>number;
if(LocateElem(LA,number)==0)
cout<<"Wrong Input!\n";
else
cout<<LocateElem(LA,number)<<endl;
}
else if(mal=="GetElem")
{
int place2;
cin>>place2;
GetElem(LA,place2);
}
}
DestroyList(LA);
}
return 0;
}
F Plague Inc.
题目链接:
http://acm.buaa.edu.cn/contest/133/problem/F/
解题分析
都说了要用链表,结果好多人都不用,urusai,urusai——
就算用链表也没什么难的嘛,某渣的做法首先是对现有的单链表进行了一个扩张,附加了一个叫end的指针域,用于指向链表表尾。接下来就很简单了,由于我们已经可以在建表的过程中获得一个链表的表头和表尾,那么我们需要做的,仅仅是将一个链表的表头和另外一个链表的表尾链接起来就可以了,但是注意,这样链接的话,在最后销毁的时候,如果将表A销毁,那么表B也会被销毁,因为在链接时并没有增添新的节点。
P.S.其实后来回想了一下发现自己写残了......end指针完全不需要扩张数据结构.......算法依旧,诸君可以自行改写一下
//a piece of trash by trashLHC
#include<iostream>
#include<cmath>
#include<cstdio>
#include<ctime>
#include<cstdlib>
#define MaxSize 1001
using namespace std;
typedef int ElemType;
typedef struct node{
ElemType data;
struct node *next;
struct node *end; //扩展的end指针域
}LinkList;
void InitList(LinkList *&L){
L=(LinkList*)malloc(sizeof(LinkList));
L->end=L;
L->next=NULL;
} //建空表
void BuildList(LinkList *&L,ElemType *a,int n){//普通建表
LinkList *p,*q;
L=(LinkList*)malloc(sizeof(LinkList));
p=L->next;
q=L;
for(int i=0;i<n;i++){
p=(LinkList*)malloc(sizeof(LinkList));
p->data=a[i];
q->next=p;
q=p;
}
p->next=NULL;
L->end=p; //表尾确定
}
int CountList(LinkList *L){ //计算表中元素个数
LinkList *p = L->next;
int num=0;
while(p!=NULL){
num++;
p=p->next;
}
return num;
}
void DispList(LinkList *L){//输出表中元素
LinkList *p = L->next;
while(p!=NULL){
printf("%d ",p->data);
p=p->next;
}
printf("\n");
}
void JoinList(LinkList *&L1,LinkList *&L2){ //链接两个表
L1->end->next = L2->next;
L1->end = L2 ->end;
free(L2); //注意要将L2销毁,因为它的存在已经没有意义
}
void DestroyList(LinkList *&L){ //销毁表
LinkList *pre=L,*p;
while(pre!=NULL){
p=pre->next;
free(pre);
pre=p;
}
}
int main(){
int n,m;
while(~scanf("%d",&n)&&n){
LinkList *L1,*L2;
InitList(L1); //建立空表L1
for(int i=0;i<n;i++){
scanf("%d",&m);
ElemType a[MaxSize];
for(int j=0;j<m;j++)
scanf("%d",&a[j]);
BuildList(L2,a,m);//建立表2
JoinList(L1,L2); //将表2与表1链接
}
printf("%d\n",CountList(L1));//计算表1中元素个数
DispList(L1); //输出表1
DestroyList(L1);//DestroyList(L2); //销毁表,仅销毁表1。考虑为什么。
}
}
G Thor’s Necklace
题目链接:
http://acm.buaa.edu.cn/problem/883/
解题分析
表的去重工作,原题忘了是在课本上还是学习指导上,难度与这个完全不一样……
由于附加了一个升序假设,此题瞬间难度掉下一个档次来,无论是顺序表还是链表,只需要再输入的时候判断表尾的元素是否与输入元素相同即可,不同则将元素加入表中,否则忽略该元素
(忽然感觉…..这他喵的不是栈么 = =!)
//by trashLHC
//the informal one
#include<cstdio>
int x[1000001];
int main(){
int n;
while(~scanf("%d",&n)&&n){
int cnt=0;
for(int i=0;i<n;i++){
int temp;scanf("%d",&temp);
if(i==0||temp!=x[cnt-1])
x[cnt++]=temp;
}
printf("%d\n",cnt);
for(int i=0;i<cnt;i++)
printf("%d ",x[i]);
printf("\n");
}
}
普通版:
链表——数据结构第四版课本P60-例2.14
顺序表:稍后放出















 2993
2993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









