






C# 从需要登录的网站上抓取数据
背景:昨天一个学金融的同学让我帮她从一个网站上抓取数据,然后导出到excel,粗略看了下有1000+条记录,人工统计的话确实不可能。虽说不会,但作为一个学计算机的,我还是厚着脸皮答应了。 。
刚开始想的是直接发送GET请求,然后再解析返回的html不就可以获取需要的信息吗?的确,如果是不需要登录的网站,这样可行,但对于这个网站就行不通。所以首先我们需要做的就是抓包,即分析用户登录时浏览器向服务器发送的POST请求。许多浏览器都自带抓包工具,但我还是更喜欢[httpwatch]
抓包过程:
1.安装httpwatch
2.用IE浏览器进入网站的登录页面
3.打开httpwatch的Record开始跟踪
4.输入账号密码,确认登录,得到下面的数据:
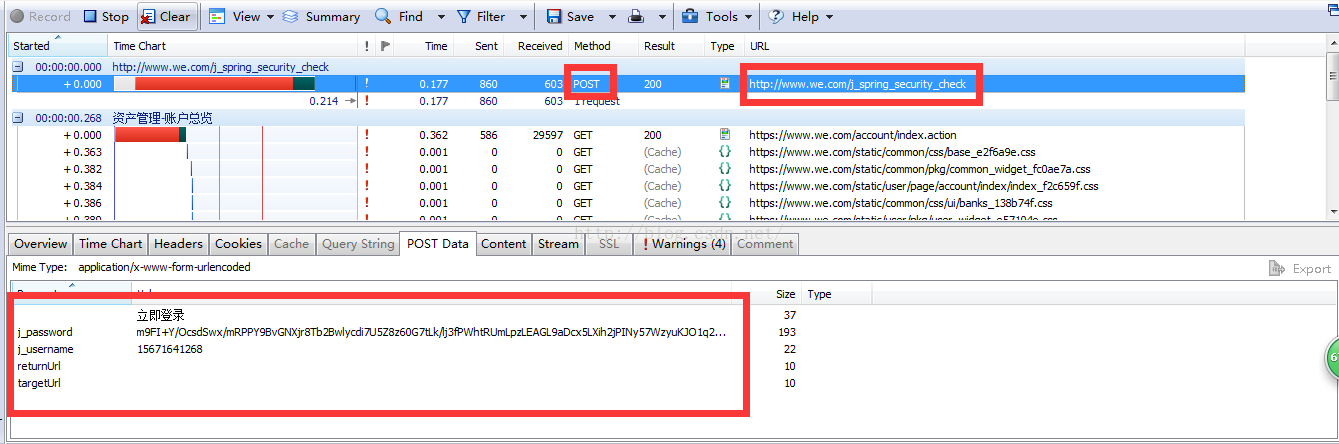
重点看POST请求中的Url和postdata,以及服务器返回的cookies
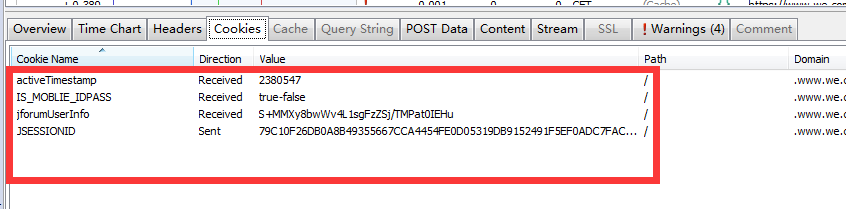
cookie里面包含有登录信息,保险起见,我们可以把这4个cookie值都传给服务器。
首先给出C#发送POST请求的代码:(目的是得到服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie后,就可以从网站上抓取自己需要的数据了,接下来就是通过发送GET请求
private string HttpGet(string Url, string postDataStr, CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url + (postDataStr == "" ? "" : "?") + postDataStr);
request.Method = "GET";
request.ContentType = "text/html;charset=UTF-8";
request.CookieContainer = cookie;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
因为服务器返回的是html,如何快速从大量的html中获取需要的信息呢?此处,我们可以引用一个高效且强大的第三方库NSoup(网上也有人推荐使用htmlparser,但通过我个人比较发现,htmlparser无论是在效率还是简洁性上,都远不如NSoup)
由于网上对于NSoup的教程比较上,大家也可以参考JSoup的教程:http://www.open-open.com/jsoup/
最后给出我从网站上抓取的部分数据:
纸上得来终觉浅,绝知此事要躬行。














 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









