






常见算法
1基本查找
2二分查找
前提条件:数组中的数据必须是有序的
核心逻辑:每次排除一半的查找范围


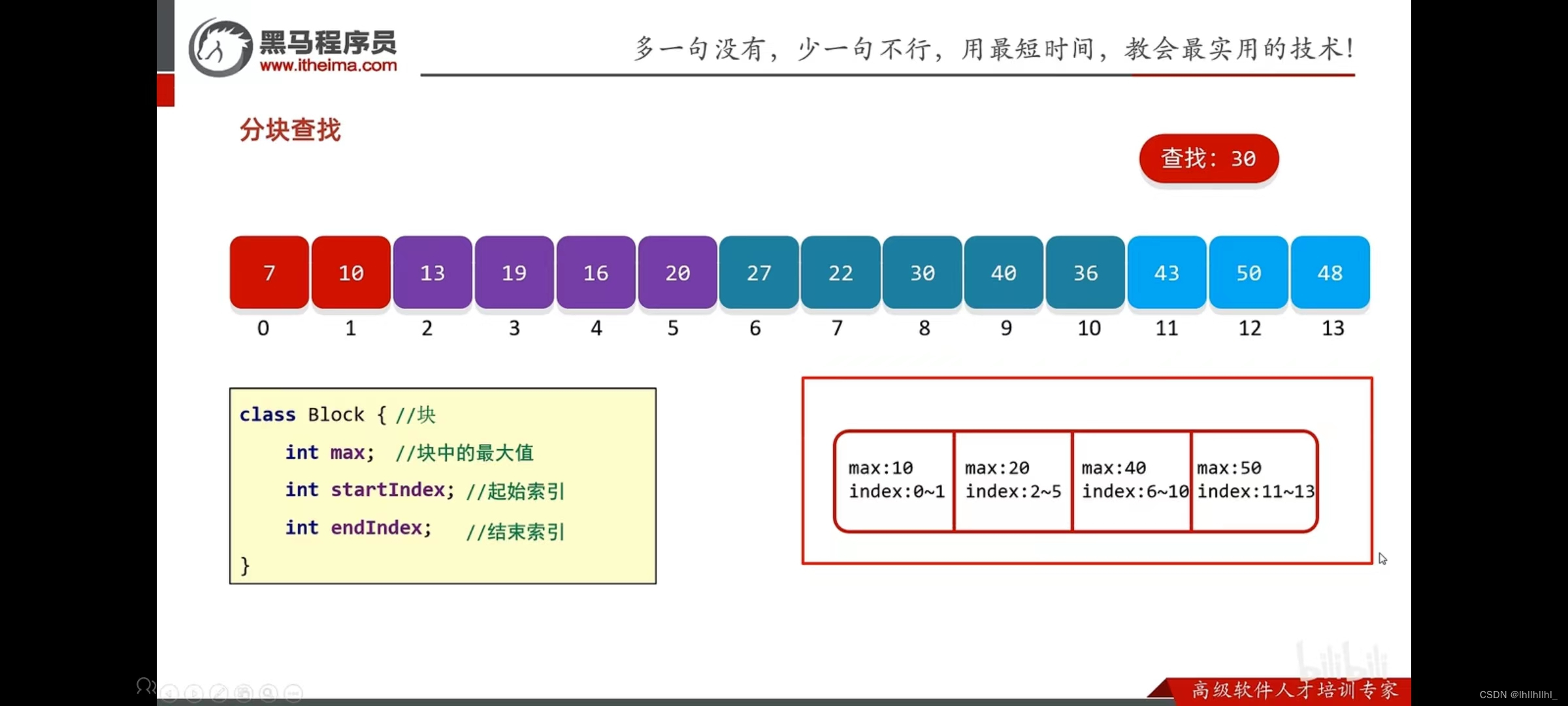
3分块查找


4递归算法

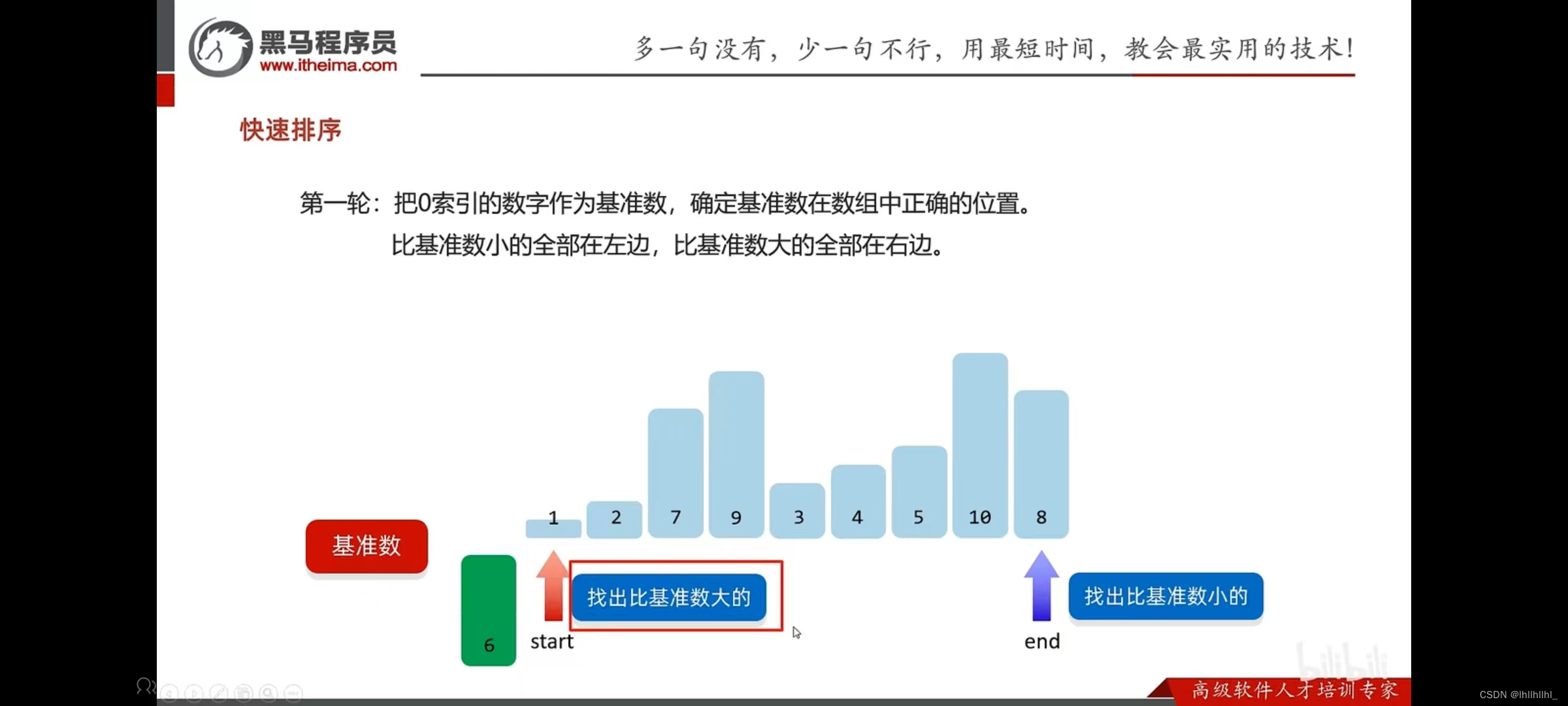
5快速排序
6总结

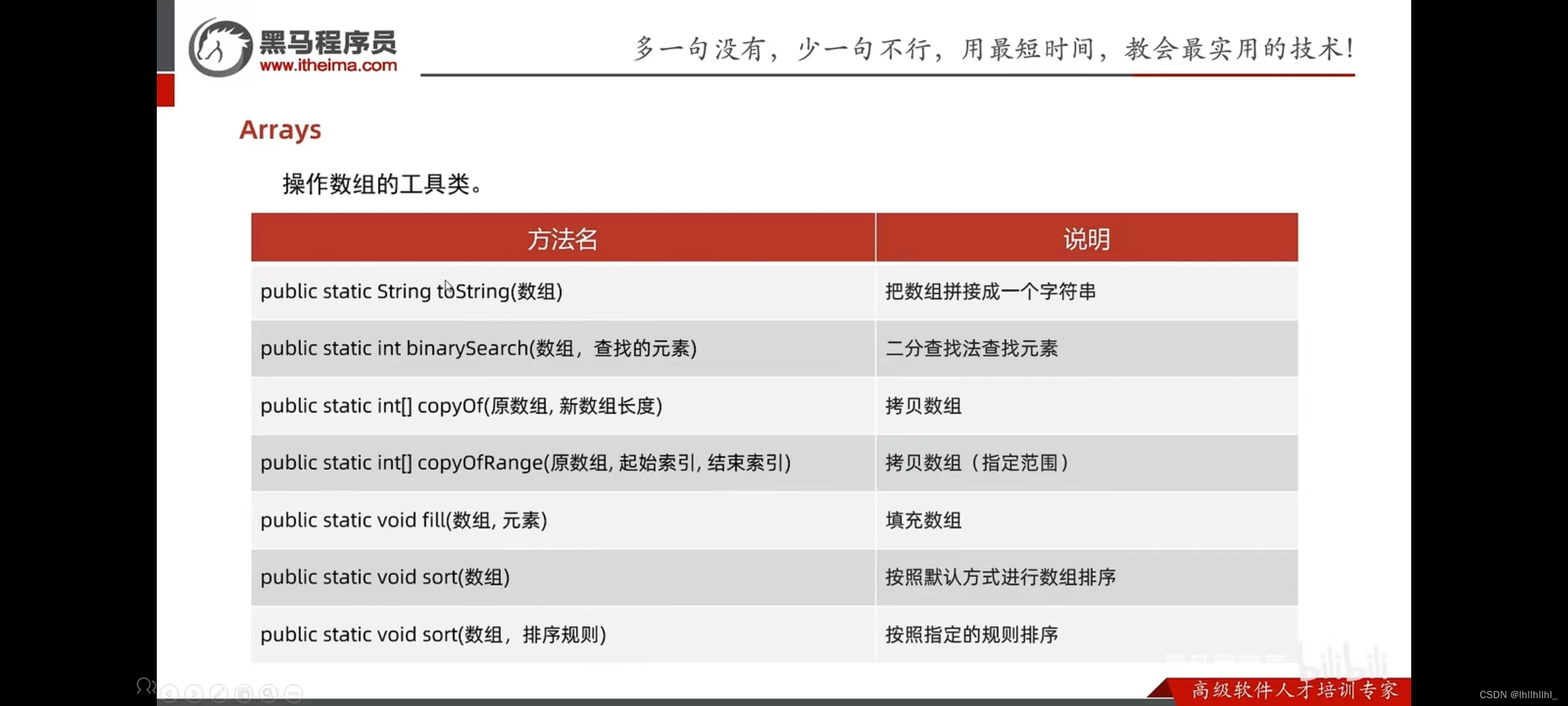
二Arrays
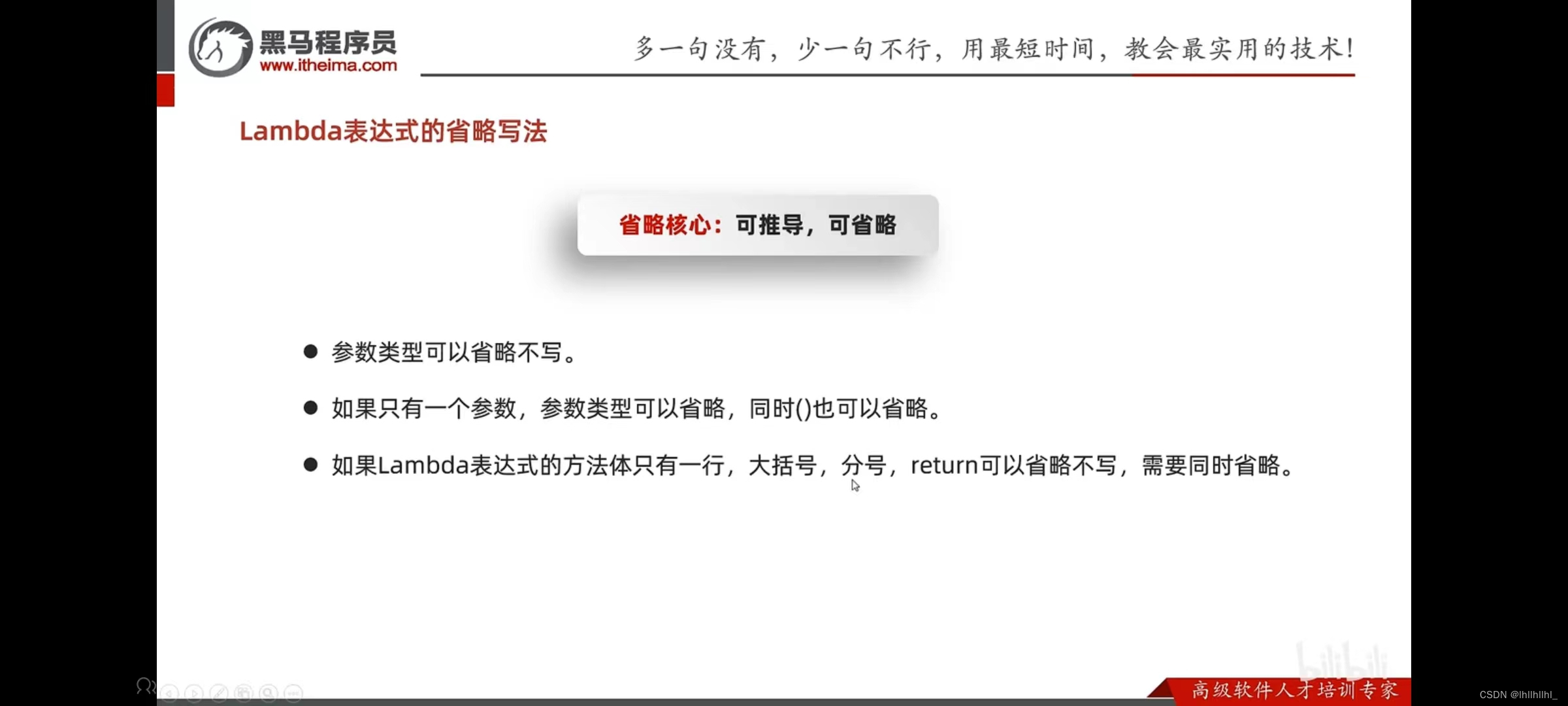
Lambd表达式



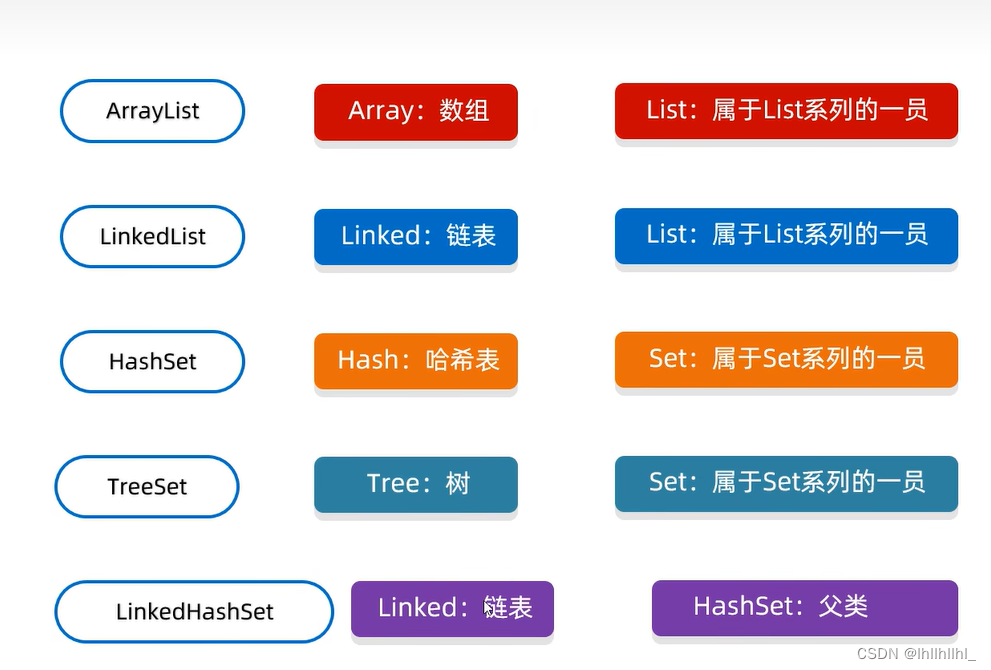
集合进阶
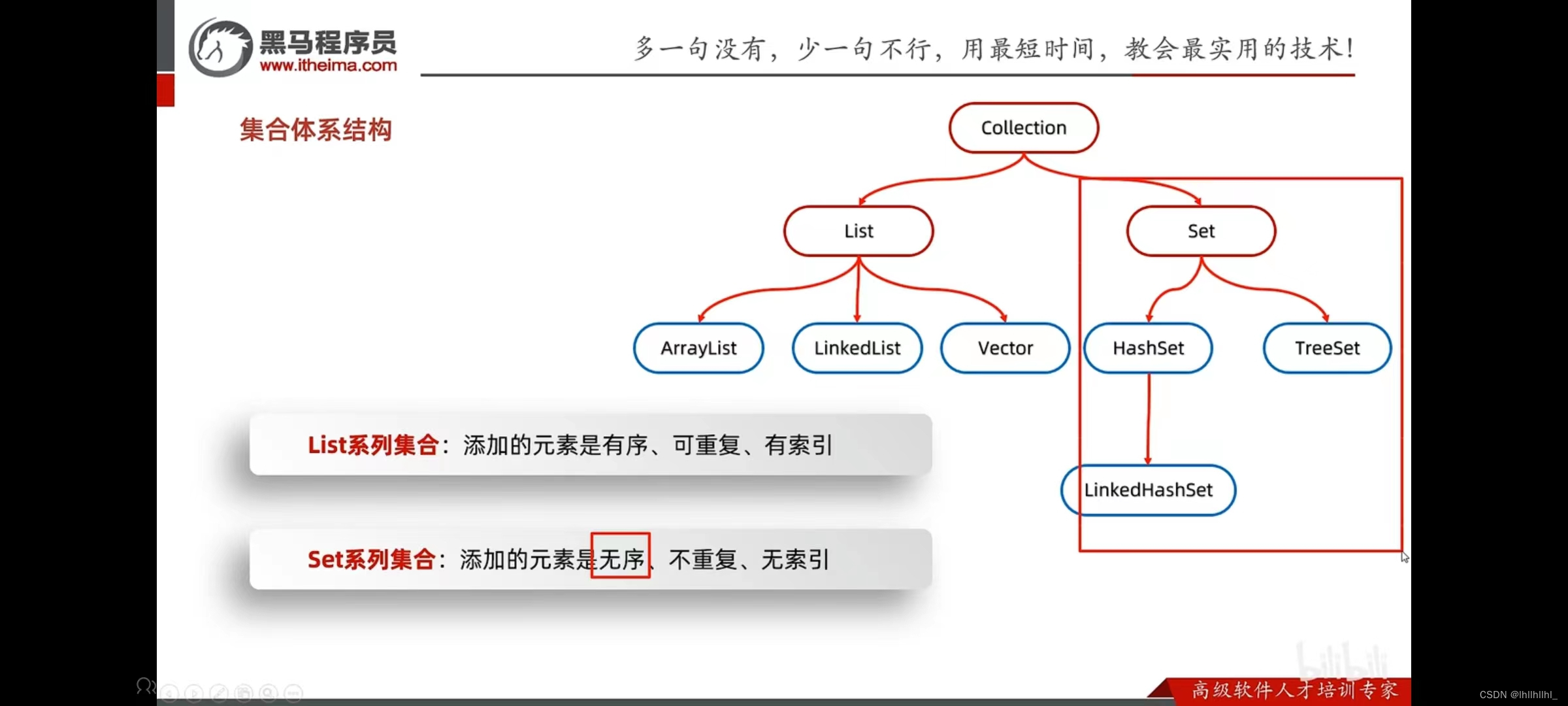
集合体系结构
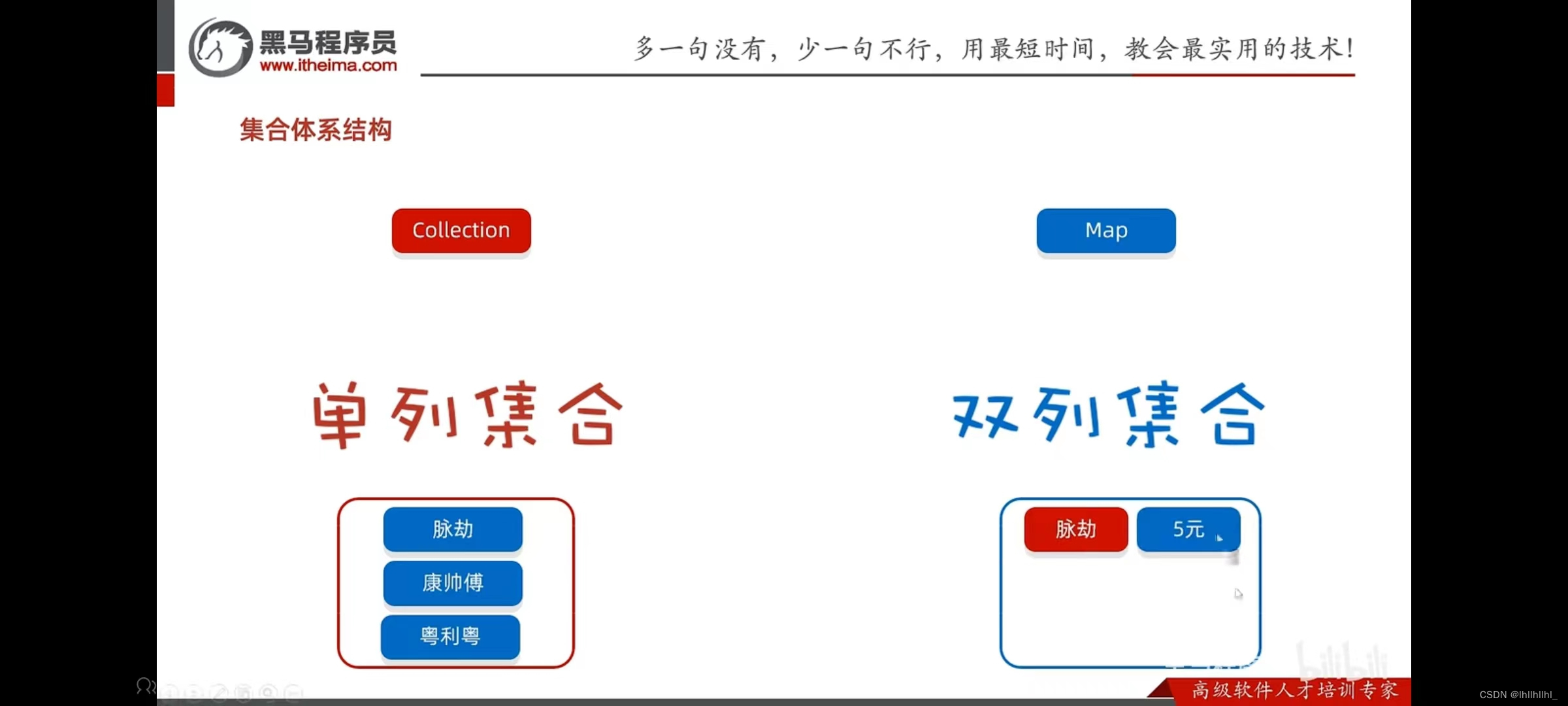
Collection集合

collection遍历方式
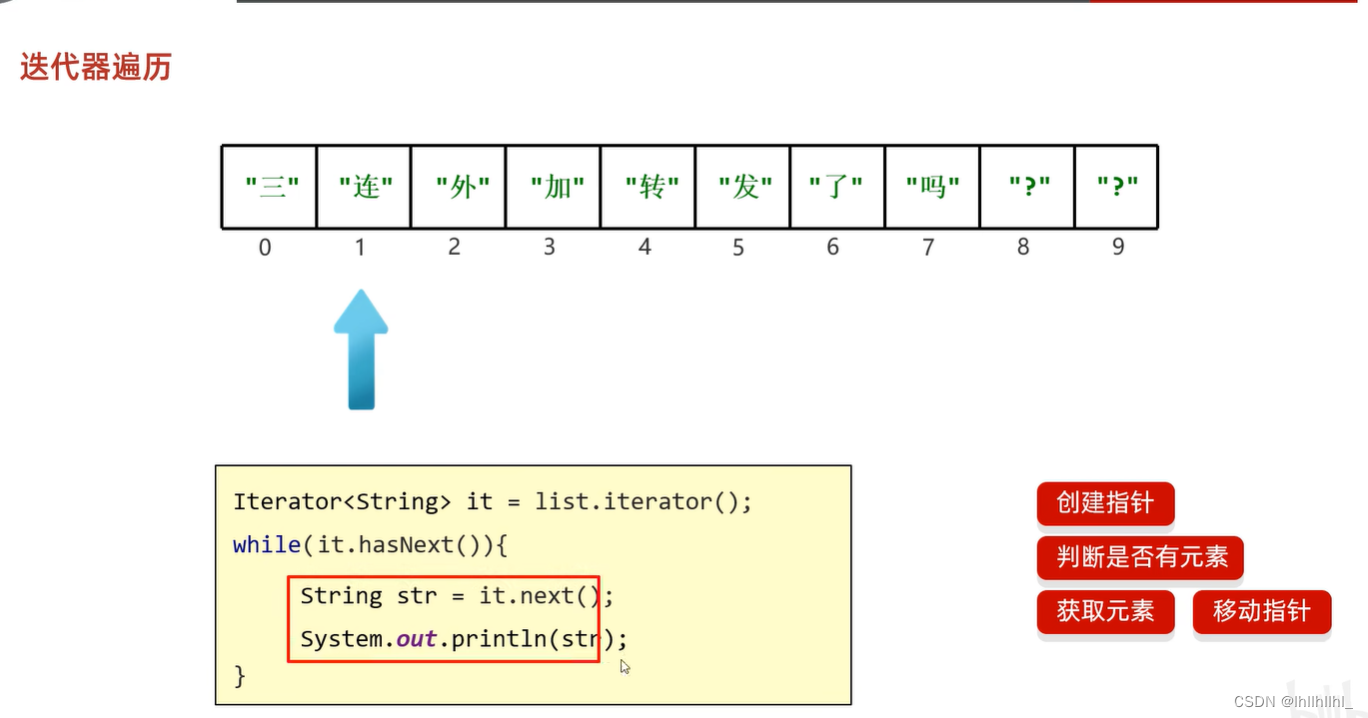
1 迭代器遍历

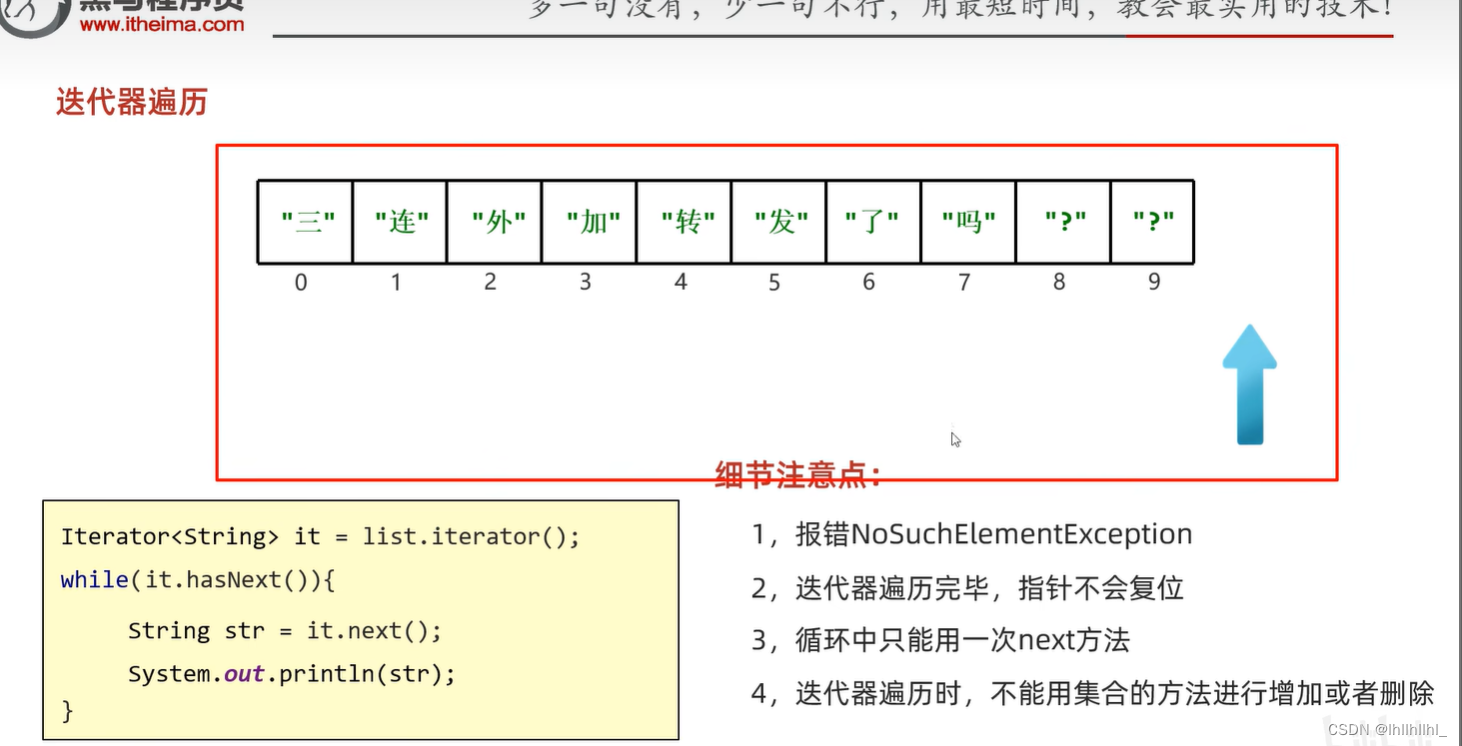
2 增强for遍历

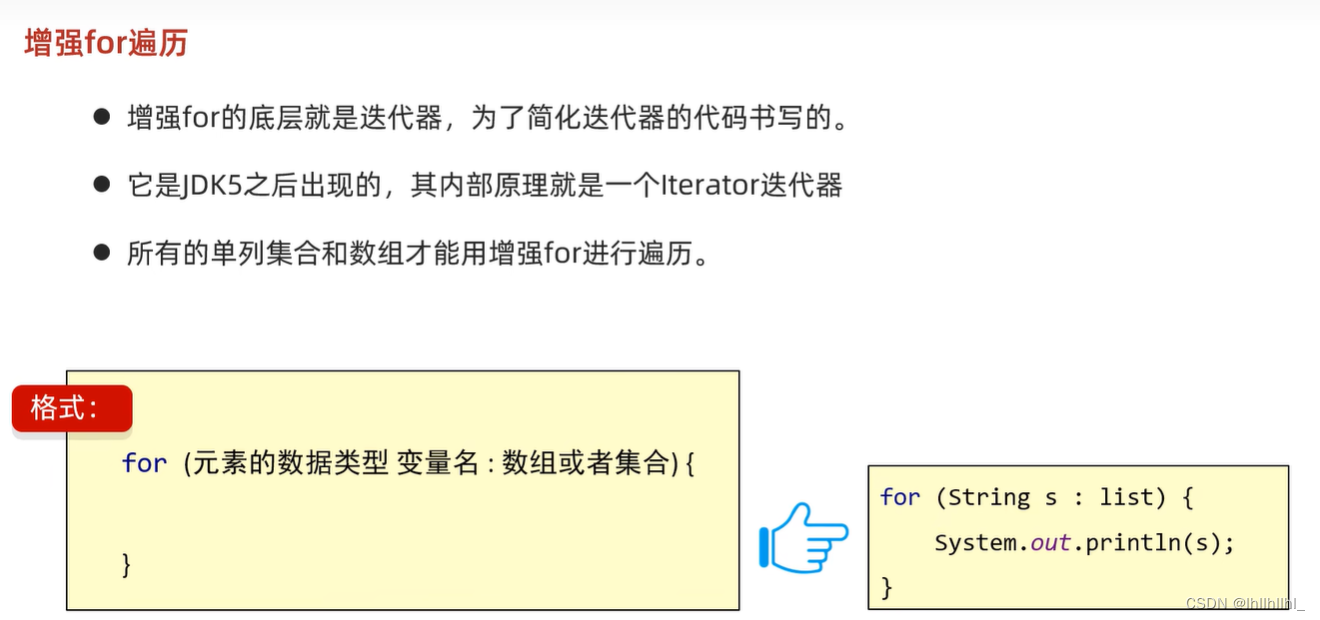
修改增强for中的变量,不会改变集合中原本的数据
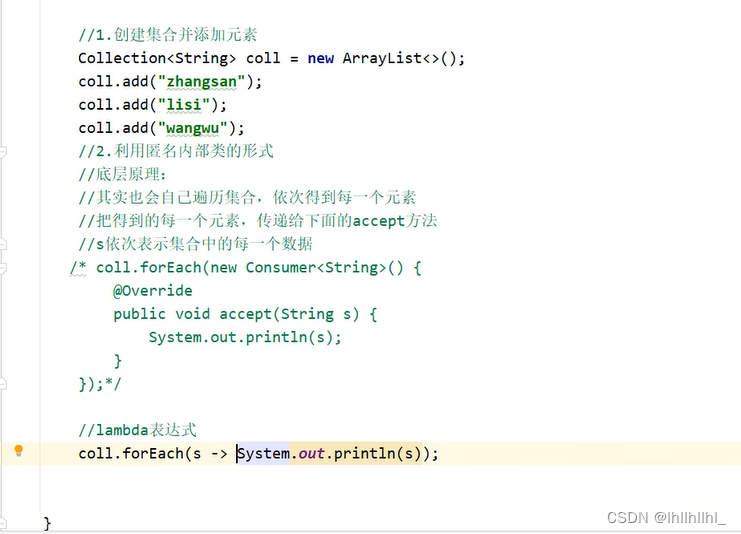
3 lambda表达式遍历

List集合

List系列集合的五种遍历方式
1迭代器
2列表迭代器
ListIterator继承于Itertor

3增强for
4Lambda表达式
5普通for循环(利用了索引)


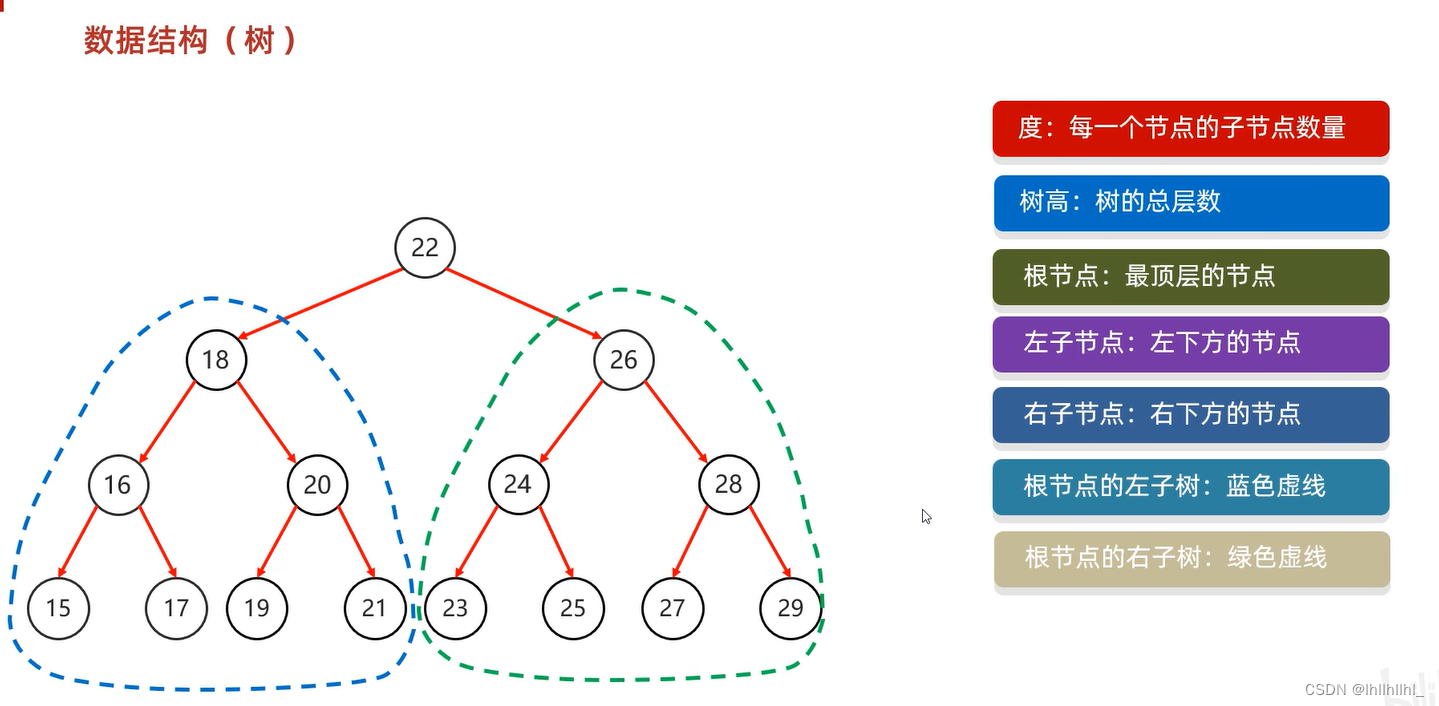
数据结构



Arraylist集合

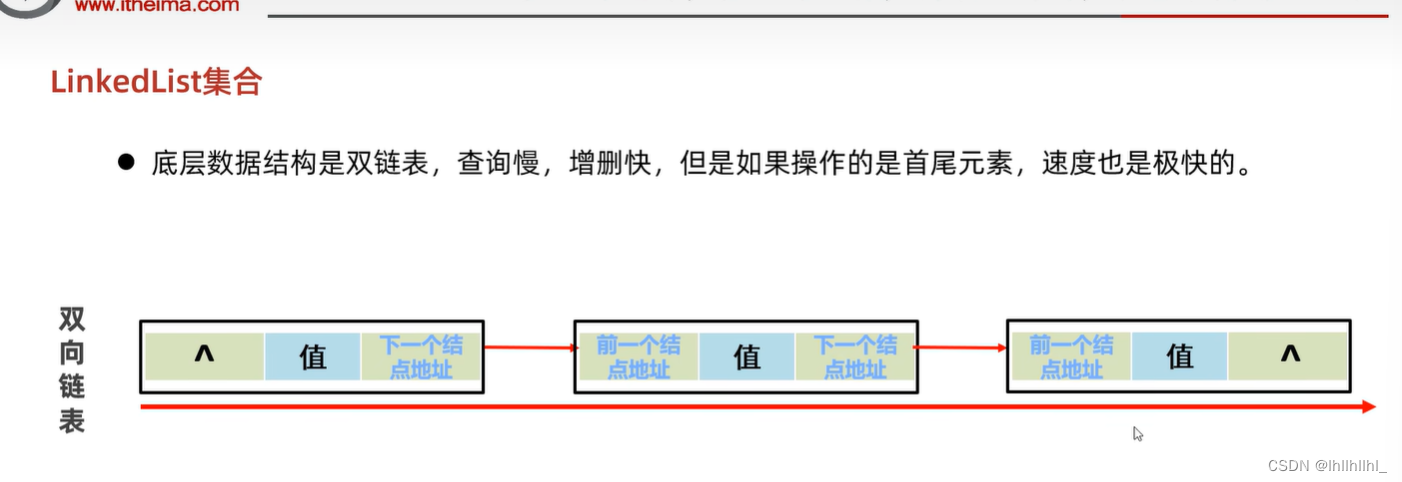
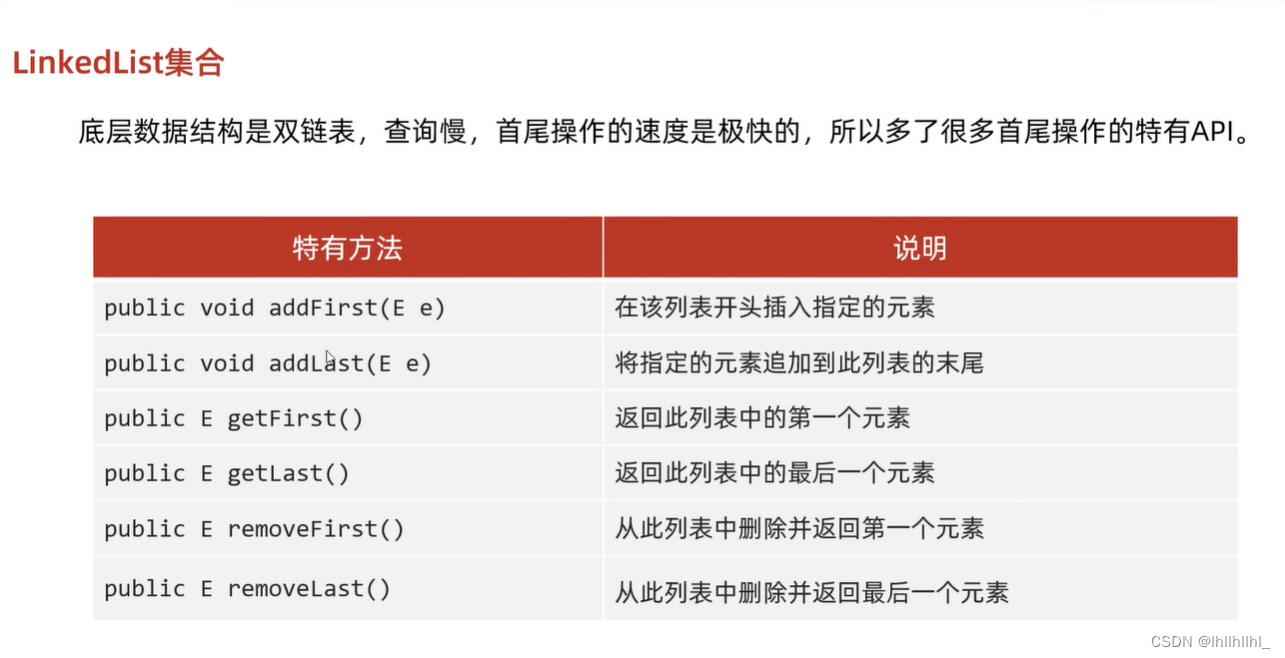
LinkdeList集合
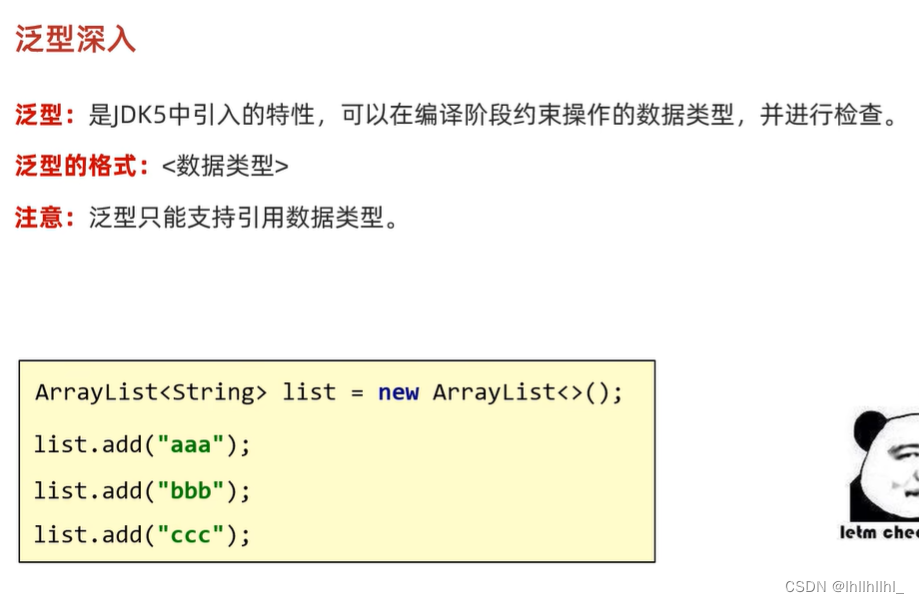
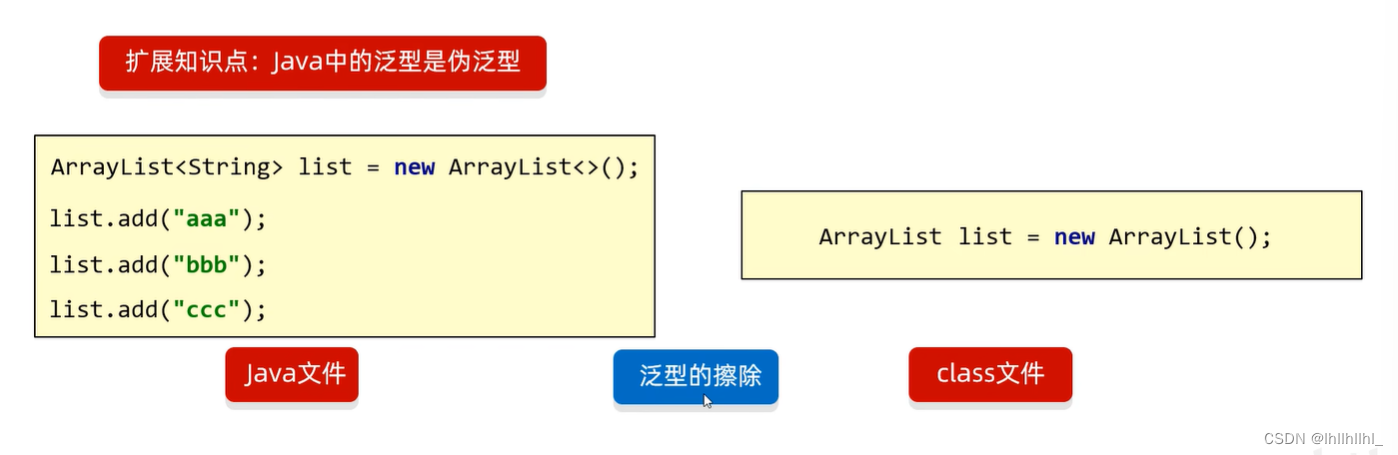
泛型深入



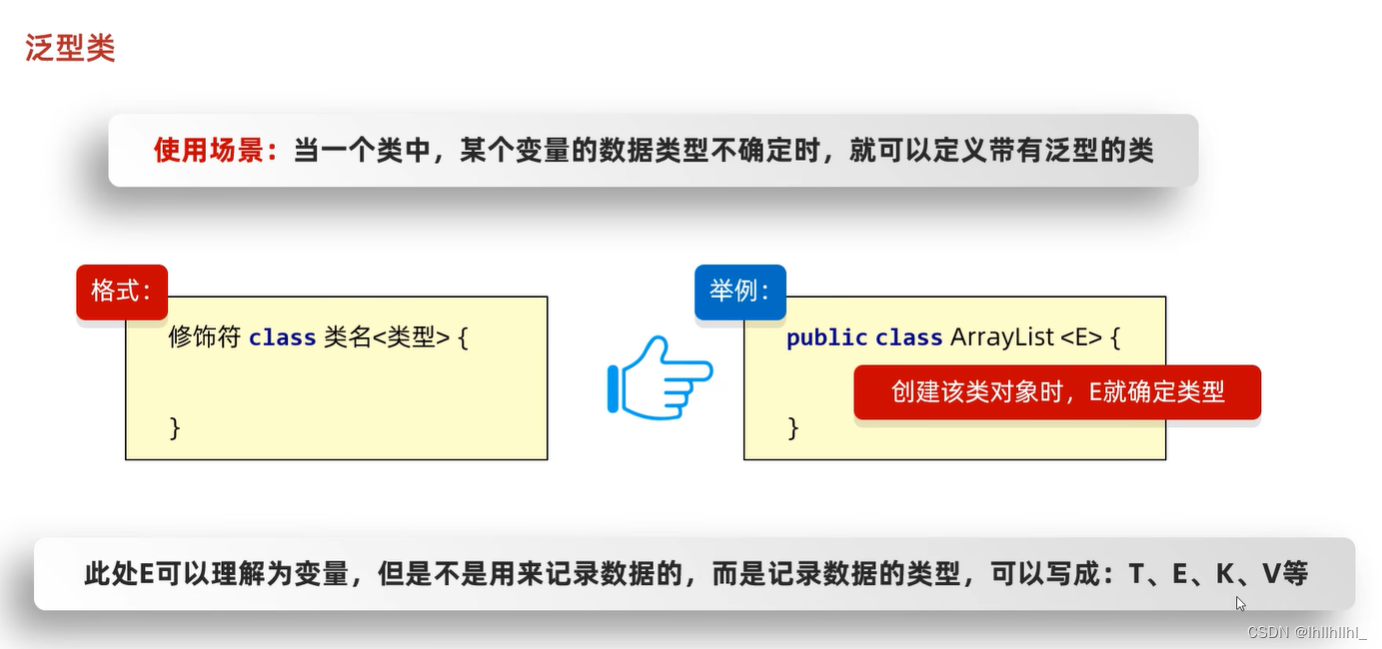
泛型类
泛型方法


泛型接口

泛型的继承和通配符
泛型的继承
泛型不具备继承性,但是数据具备继承性
泛型的通配符

数据结构
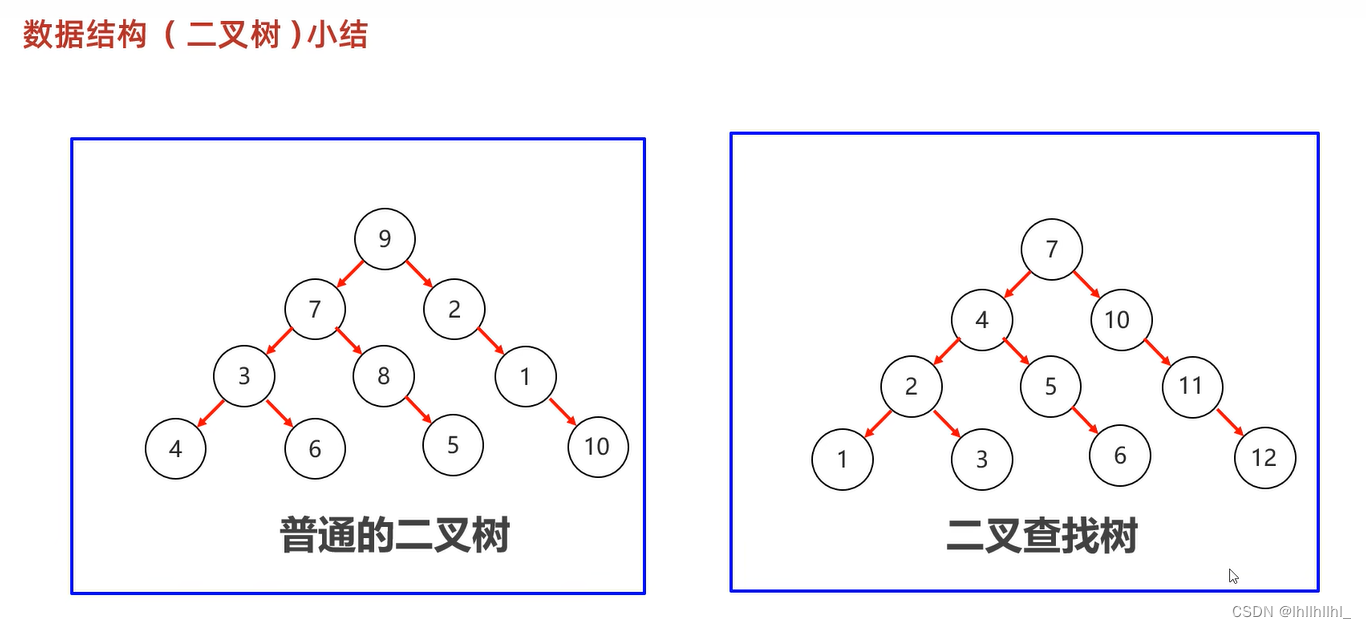
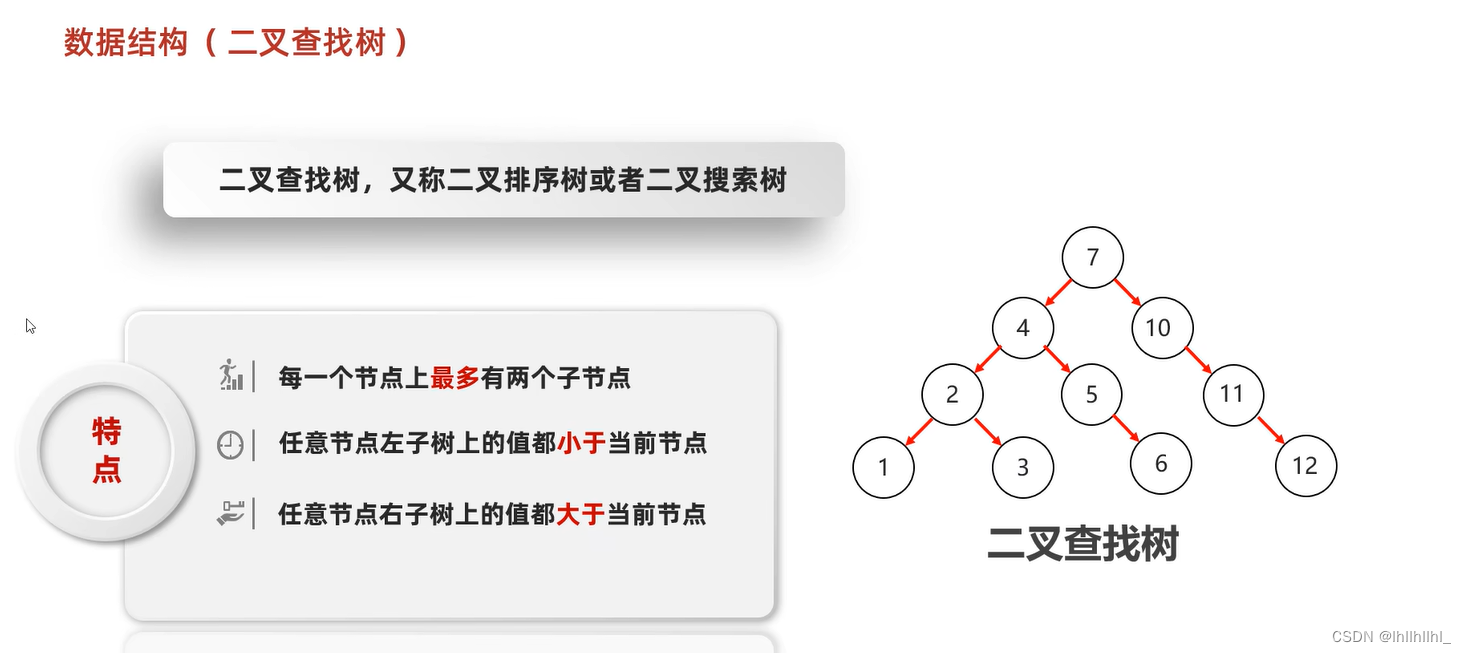
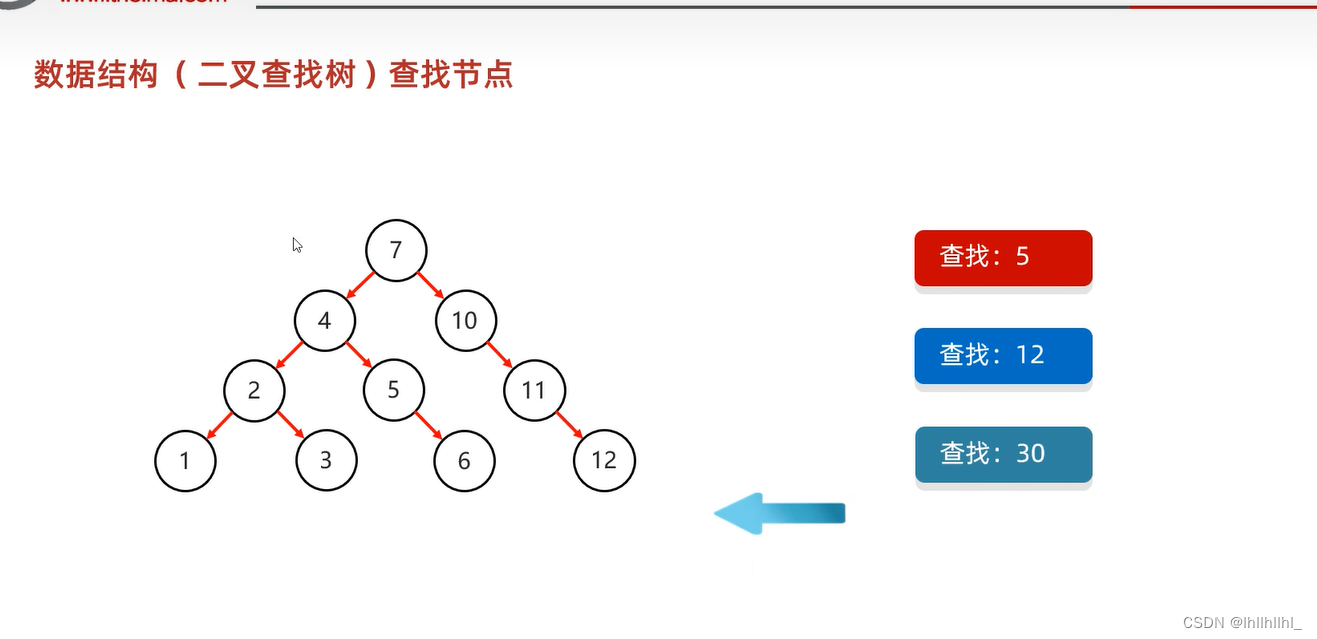
二叉查找树
数据结构(二叉树)遍历方式
①前序遍历
从根节点开始,按照当前节点,左子节点,右子节点的顺序遍历
②中序遍历
从最左边的子节点开始,然后按照左子节点,当前节点,右子节点的顺序遍历
(最后结果为由小到大)
③后序遍历
从最左边的子节点开始,然后按照左子节点,右子节点,当前节点的顺序遍历
④层序遍历
从根节点开始,一层一层的去遍历

平衡二叉树
在二叉查找树的基础上增加了规则
规则:任意节点左右子树高度差不超过1

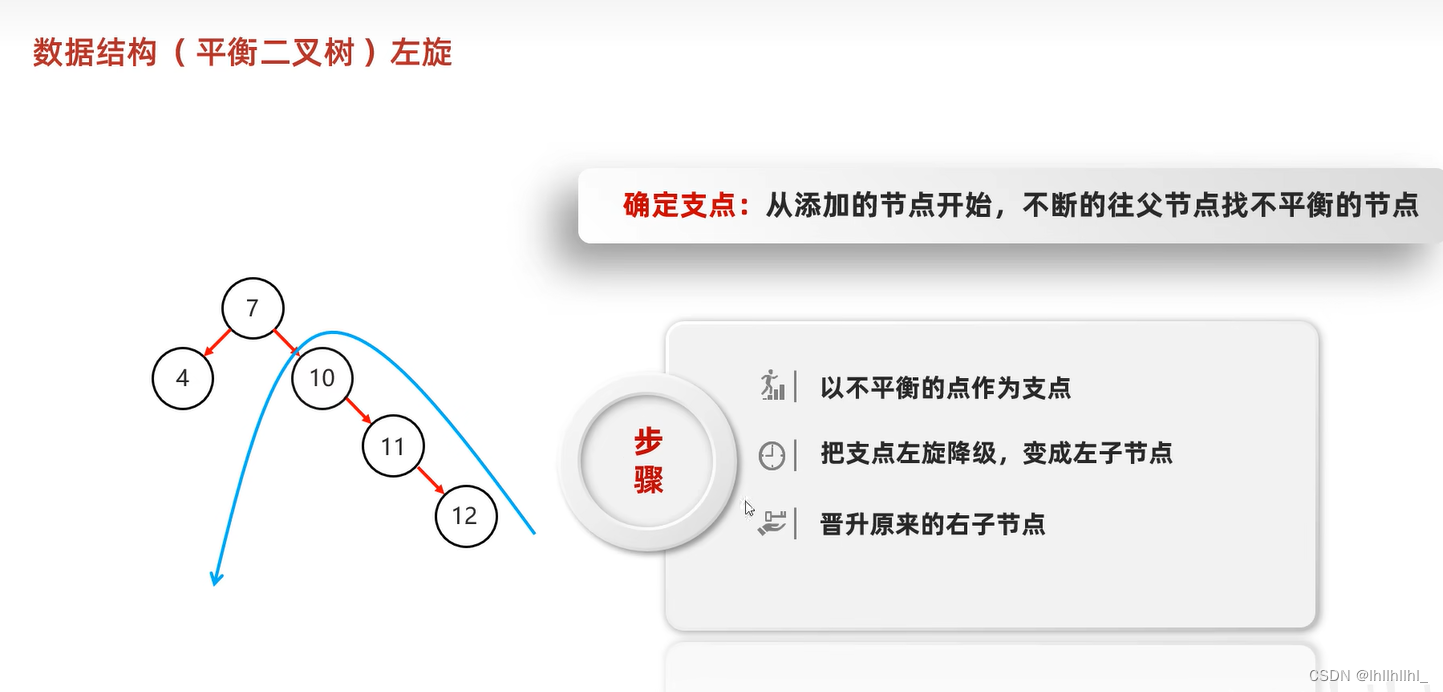
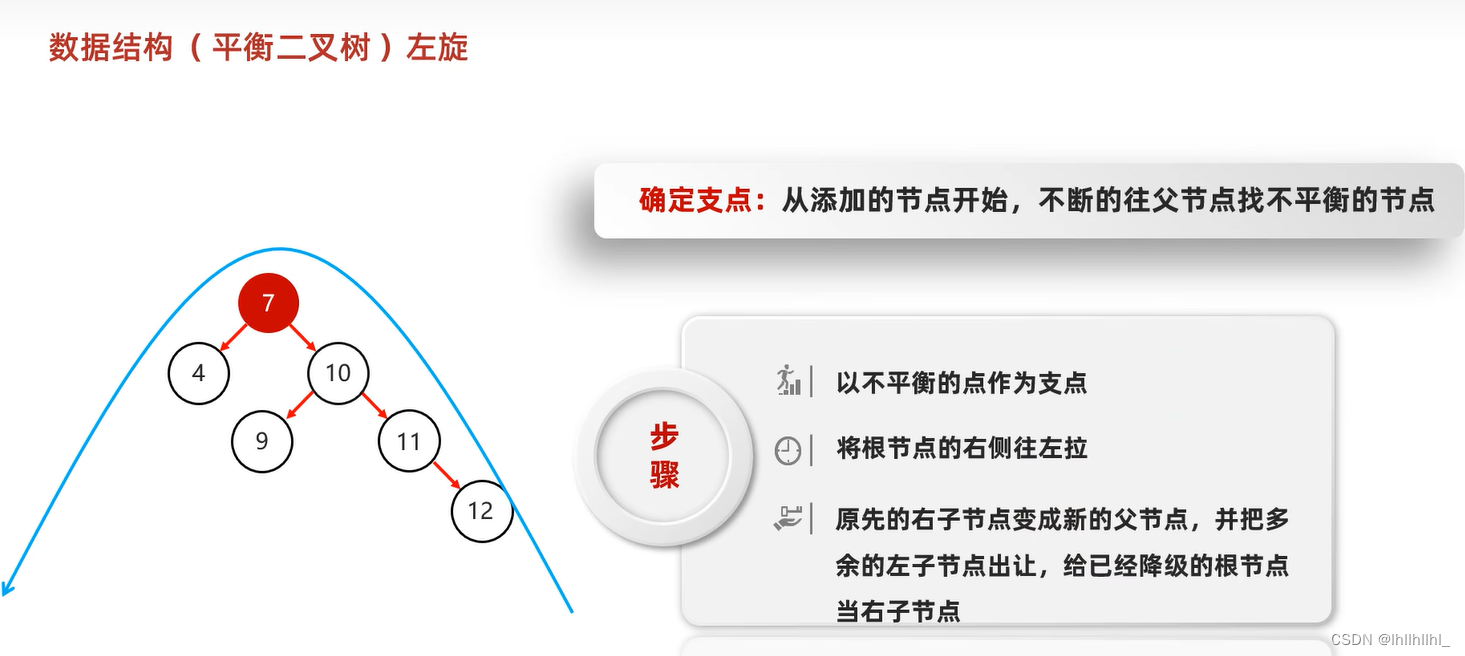
右旋原理同左旋

数据结构(树)的演变

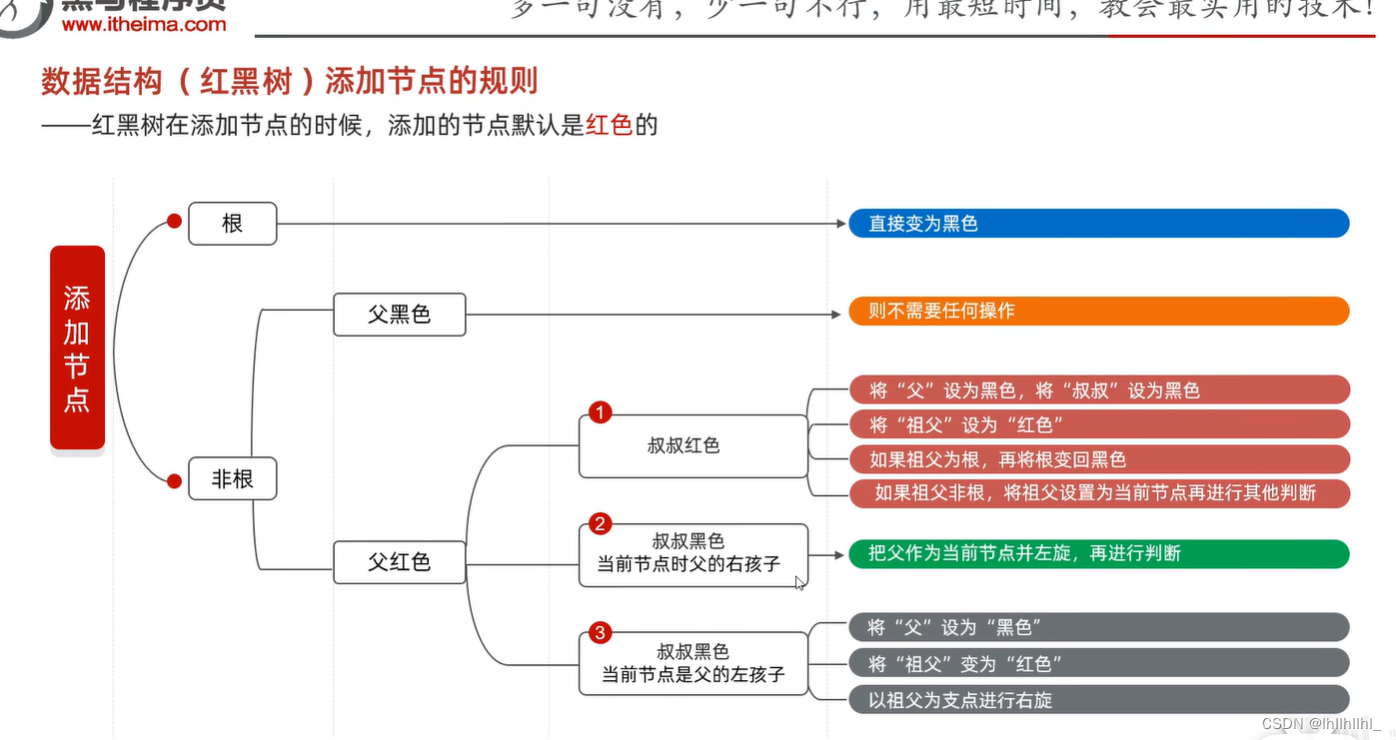
数据结构(红黑树)


默认颜色:添加节点默认是红色的,效率高。
set系列结构



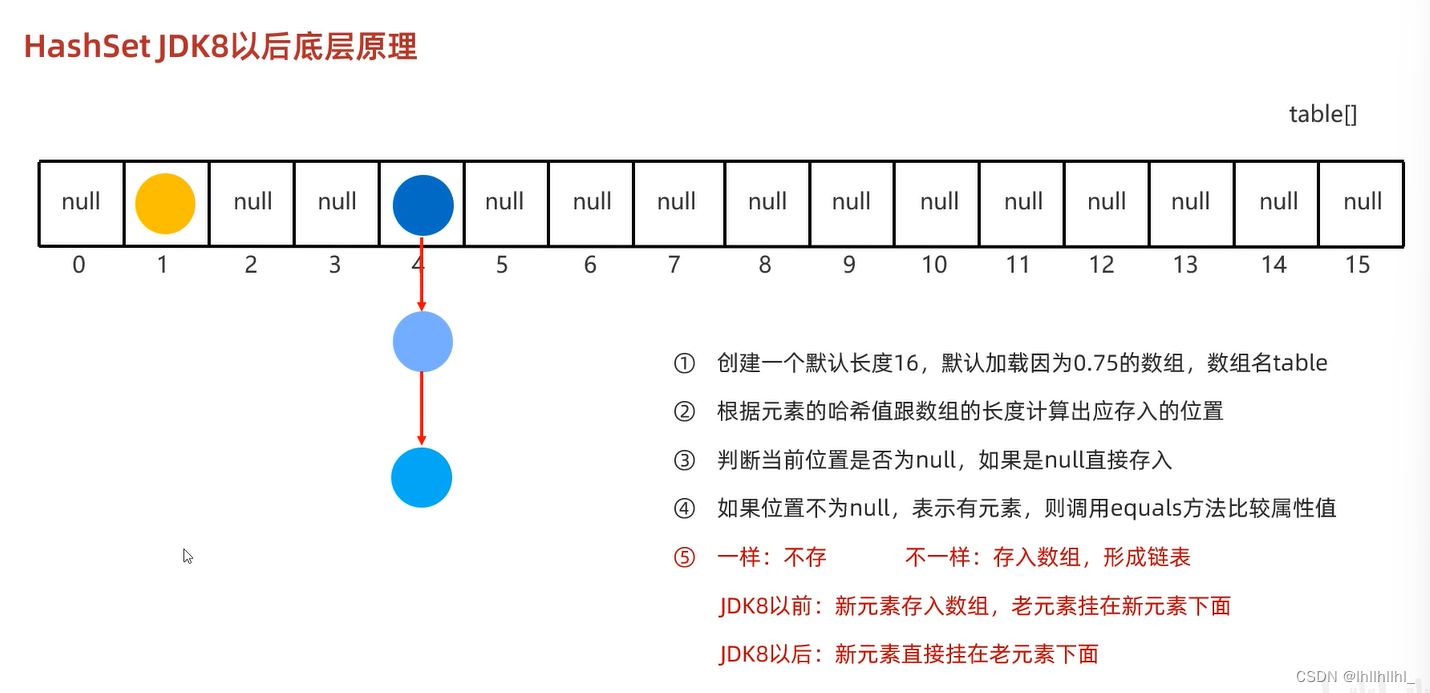








双列集合

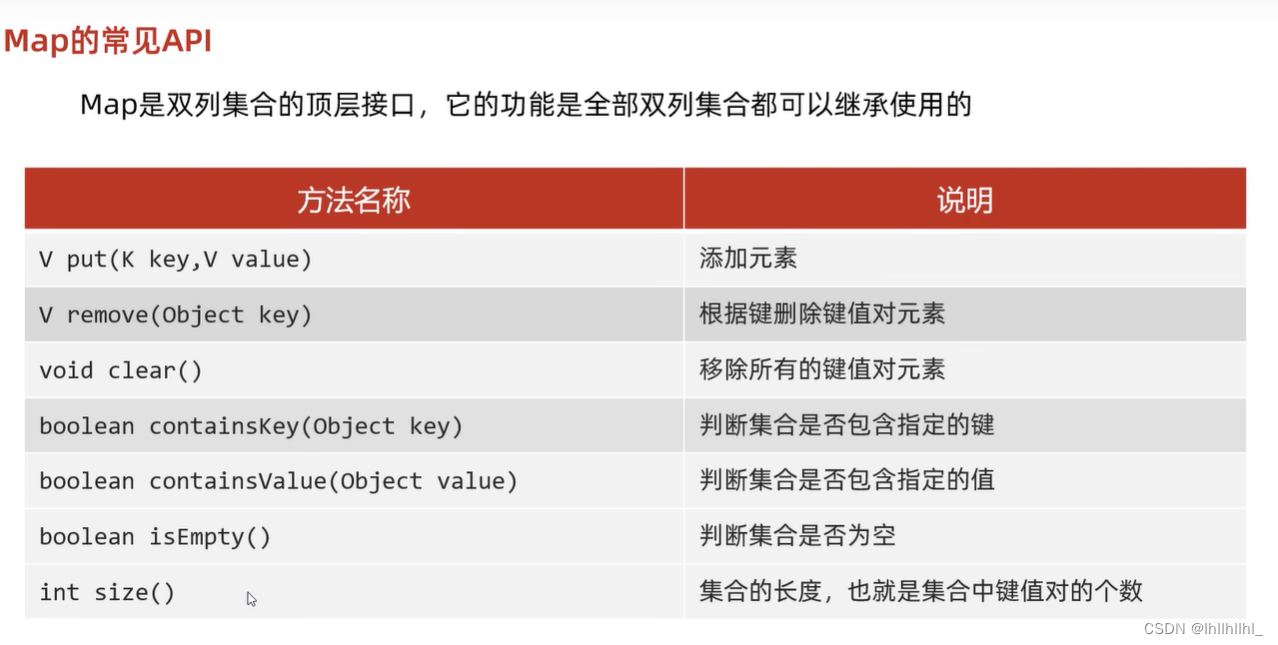
双列集合常见API

Map集合的第一种遍历方式(通过键找值)

Map集合中的第二种遍历方式(键值对)

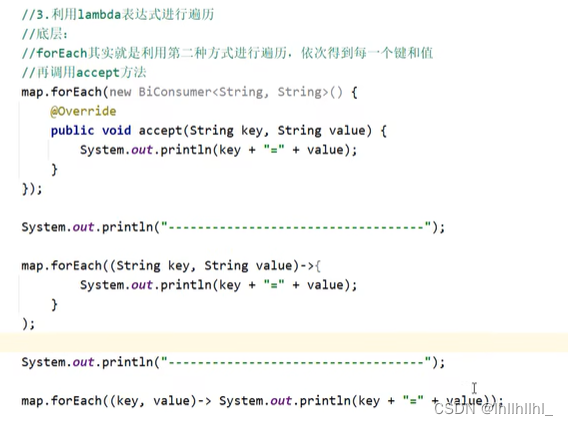
Map集合的第三种遍历方式(lanbda表达式)
HashMap
HashMap的特点

HashMap例题
例题1
**第一个类**
/*创建一个HashMap集合,键是学生对象Student,值是籍贯String
存储三个键值对元素,并遍历
要求:同姓名,同年龄认为是同一个学生*/
package Test3;
import java.security.PrivateKey;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.function.BiConsumer;
public class Test41 {
public static void main(String[] args) {
//1创建HashMap对象
HashMap<Test41student,String> hm=new HashMap<>();
//2创建三个学生对象
Test41student s1= new Test41student("zhangsan",23);
Test41student s2= new Test41student("lisi",24);
Test41student s3= new Test41student("wangwu",25);
Test41student s4= new Test41student("wangwu",25);
//3添加元素
hm.put(s1,"江苏");
hm.put(s2,"浙江");
hm.put(s3,"福建");
hm.put(s4,"gangxi");
//4遍历集合
//1通过键找值
Set<Test41student> keys = hm.keySet();
for (Test41student key:keys){
String value = hm.get(key);
System.out.println(key+"="+value);
}
System.out.println("-----------------------------------");
//2获取键加值整体
Set<Map.Entry<Test41student, String>> entries = hm.entrySet();
for (Map.Entry<Test41student, String> entry : entries) {
Test41student key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value);
}
System.out.println("------------------------------------");
//3lanbad表达式
hm.forEach((test41student, s)-> System.out.println(test41student+"="+s));
}
}
**第二个类**
package Test3;
import java.util.Objects;
public class Test41student {
private String name;
private int age;
public Test41student() {
}
public Test41student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Test41student{name = " + name + ", age = " + age + "}";
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Test41student that = (Test41student) o;
return age == that.age && Objects.equals(name, that.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
}
例题2
**统计投票人数**
/*需求
某个班级80名学生,现在需要组成秋游活动,班长提供了四个景点,依次是(A,B,C,D),
每个学生只能选择一个景点,请统计出最终那个景点想去的人数最多*/
package Test3;
import javax.naming.Name;
import java.util.*;
public class Test41 {
public static void main(String[] args) {
//1需要先让同学们投票
//定义一个数组,存储四个景点
String[] arr={"A","B","C","D"};
//利用随机数模拟80个同学的投票,并把投票的结果存储起来
ArrayList<String> list=new ArrayList<>();
Random r=new Random();
for (int i = 0; i < 80; i++) {
int index = r.nextInt(arr.length);
list.add(arr[index]);
}
//2如果要统计的东西比较多,不方便使用计数器思想,我么可以定义map集合,利用集合进行统计。
HashMap<String,Integer> hm=new HashMap<>();
for (String name : list) {
//判断当前的景点在map集合当中是否存在
if (hm.containsKey(name)){
//存在
//先获取当前景点已经被投票的次数
Integer count = hm.get(name);
//表示当前集合又被投了一次
count++;
//把新的次数再次添加到集合当中
hm.put(name,count);
}else{
//不存在
hm.put(name,1);
}
}
System.out.println(hm);
//3求最大值
//让谁作最大值都不合适,因为可能这些景点可能没人投,从而没有这个集合
int max=0;
//景点遍历
Set<Map.Entry<String, Integer>> entries = hm.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
Integer count = entry.getValue();
if(count>max){
max=count;
}
}
System.out.println(max);
//4判断哪个景点的次数和最大值一样
for (Map.Entry<String, Integer> entry : entries) {
Integer count = entry.getValue();
if(count==max){
System.out.println(entry.getKey());
}
}
}
}
LinkedHashMap
特点
1)由键决定:有序、不重复、无索引
2)原理:底层数据结构依然是哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序
TreeMap
特点
1)底层是红黑树结构
2)由键决定特性:不重复、无索引、可排序
3)可排序:对键进行排序
4)注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则
代码书写两种排序规则
1)实现Comparable接口,制定比较规则
2)创建集合时传递Comparator比较器对象,制定比较规则
例题
例一
/*需求一
键:整数表示id
值:字符串表示商品名称
要求:按照id的升序排列、按照id的降序排列
*/
package Test3;
import java.util.Comparator;
import java.util.TreeMap;
public class Test41 {
public static void main(String[] args) {
//1创建集合对象
//Integer Double 默认情况都是按照升序排列的
//String按照字母在ASCII码表中对应的数字升序排列的
//abcdefg...
//换成降序排列
TreeMap<Integer,String> tm=new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//o1表示当前要添加的元素
//o2表示已经在红黑树中存在的元素
return o2-o1;
}
});
//2添加元素
tm.put(2,"康师傅");
tm.put(3,"九个核桃");
tm.put(1,"阅历月");
tm.put(4,"leibi");
tm.put(5,"kekoukele");
//3打印集合
System.out.println(tm);
}
}
例二
/*
需求二
键:学生对象
值:籍贯
要求:按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名年龄视为同一个人
*/
**第一个类**
package Test3;
import java.util.Comparator;
import java.util.TreeMap;
public class Test41 {
public static void main(String[] args) {
//1创建集合
TreeMap<Test42,String> tm=new TreeMap<>();
//2创建三个学生对象
Test42 s1=new Test42("zhangsan",23);
Test42 s2=new Test42("lisi",24);
Test42 s3=new Test42("wangwu",25);
//3添加元素
//键是自定义对象,所以必须指定排序规则
tm.put(s1,"jiangsu");
tm.put(s2,"tianjin");
tm.put(s3,"shanghai");
//打印集合
System.out.println(tm);
}
}
**第二个类**
package Test3;
import javax.sql.rowset.serial.SerialStruct;
import java.util.Objects;
public class Test42 implements Comparable<Test42> {
private String name;
private int age;
public Test42() {
}
public Test42(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Test42{name = " + name + ", age = " + age + "}";
}
@Override
public int compareTo(Test42 o) {
//按照学生的年龄进行升序排列,年龄一样按照姓名的字母排列,同姓同名视为同一个人
//this:表示当前要添加的元素
//o:表示已经在红黑树中存在的元素
//返回值:
//负数:表示当前要添加的元素是小的,存左边
//正数:表示当前要添加的元素是大的,存右边
//0:表示当前要添加的元素已经存在,舍弃
int i = this.getAge() - o.getAge();
i = i == 0 ? this.getName().compareTo(o.getName()) : i;
return i;
}
}
例三
/*需求
字符串“aababcabcdabcde”
请统计字符串中每个字符出现的次数,并按照以下格式输出
输出结果:
a(5)b(4)c(3)d(2)e(1)*/
package Test3;
import java.util.StringJoiner;
import java.util.TreeMap;
import java.util.function.BiConsumer;
public class Test41 {
public static void main(String[] args) {
/*
//计数器的弊端:统计的东西比较多,非常不方便/
//新的统计思想:利用Map集合进行统计
//HashMap
//TreeMap
//如果题目中没有要求对结果进行排序,默认使用HashMap
//如果题目中要求对结果进行排序,请使用TreeMap
//键:表示要统计的内容
//值:表示次数
*/
//1.定义一个字符串
String s="aababcabcdabcde";
//2创建集合
TreeMap<Character,Integer> tm=new TreeMap<>();
//2遍历字符串得到里面的每一个字符
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
//拿着c到集合中判断是否存在
//存在,表示当前字符又出现了一次
//不存在,表示当前字符是第一次出现的
if(tm.containsKey(c)){
int count =tm.get(c);
count++;
tm.put(c,count);
}else{
tm.put(c,1);
}
}
//4遍历集合,并按照指定格式进行拼接
//a(5)b(4)c(3)d(2)e(1)
//StringBuilder
//法一
StringBuilder sb=new StringBuilder();
tm.forEach((key,value)-> sb.append(key).append("(").append(value).append(")"));
System.out.println(sb);
//法二
//StringJoiner
StringJoiner sj=new StringJoiner("","","");
tm.forEach((key,value)->sj.add(key+"").add("(").add(value).add(")"));
System.out.println(sj);
}
}















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









