









一、Hadoop配置
虚拟机配好连上moba后:
生成秘钥: ssh-keygen -t rsa -P ""
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
开启远程免密登录配置
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@192.168.56.122
远程登录
[ssh -p 22 root@192.168.56.122
往远程服务器拷贝文件 注:没有建立集群的话,下一步不需要执行操作拷贝。
scp /etc/hosts root@192.168.56.124:/etc/
配置完成后重启网卡
重新启动网络:service network restart
配置主机名
vi /etc/hostname
主机名:hadoop101
hostnamectl set-hostname centos77.magedu.com # 使用这个命令会立即生效且重启也生效
hostname # 查看下centos77.magedu.com
vim /etc/hosts # 编辑下hosts文件, 给127.0.0.1添加hostname
cat /etc/hosts # 检查127.0.0.1
localhost localhost.localdomain localhost4 localhost4.localdomain4 centos77.magedu.com
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.91 hadoop101
配置Hadoop
安装软件到opt文件夹下:

将native安装包解压安装到hadoop安装目录的lib目录和lib目录下的native目录即可
tar -xvf hadoop-native-64-2.6.0.tar -C $HADOOP_HOME/lib/native
tar -xvf hadoop-native-64-2.6.0.tar -C $HADOOP_HOME/lib
cd hadoop/ect/hadoop 目录下的文件
打开文件vi hadoop-env.sh

The java implementation to use.
export JAVA_HOME=/opt/greeinstall/jdk18111

core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.137:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/greeinstall/hadoop260/hadoop2</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>

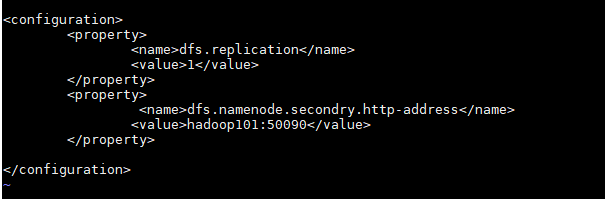
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>lijia1:50090</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>HostName:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>HostName:19888</value>
</property>
</configuration>

yarn-site.xml
<configuration>
<!-- reducer获取数据方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>HostName</value>
</property>
<!-- 日志聚集功能使用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>

vi ./slaves
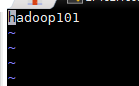
localhost
Hadoop环境变量配置
vi /etc/profile
export HADOOP_HOME=/opt/greeinstall/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
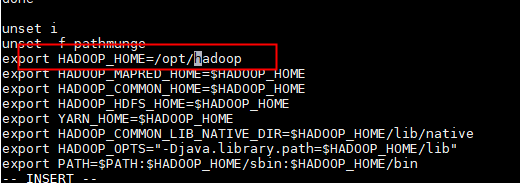
source /etc/profile #重新启动
格式化HDFS
hadoop namenode -format
启动hadoop

start-all.sh
关闭hadoop
stop-all.sh
启动历史服务
[root@qx1 hadoop]# mr-jobhistory-daemon.sh start historyserver
访问Hadoop
http://192.168.56.91:50070 HDFS页面

http://192.168.56.91:8088 YARN的管理界面

http://192.168.56.91:19888/
如果页面打不开,现在moba里面输入jps,查看服务,应该7个。
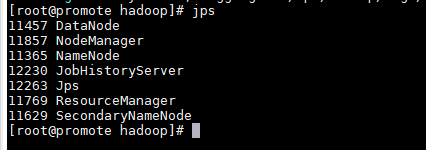
如果没有:12230 JobHistoryServer
输入命令: mr-jobhistory-daemon.sh start historyserver 启动history服务。
二、hadoop集群
由于之前hadoop搭建配置过免登录,需要先删除文件,输入: cd /root/.ssh/,删除私钥文件: rm -rf id_rsa ,然后回到家目录: cd ~
2.生成私钥: ssh-keygen -t rsa -P "" ,输入命令后直接回车
3.输入: cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
4.远程免登录配置: ssh-copy-id -i .ssh/id_rsa.pub -p22 root@192.168.255.22(有n个机器,就要配n-1次)
5.验证免登录: ssh root@192.168.255.22或 ssh root@hadoop01,无需密码验证即当前机器对111机器免登录配置成功(有多少台机器都要验证)
复制虚拟机,启动。
配置Hadoop ./etc/hadoop目录下的文件
hadoop-env.sh
#The java implementation to use.
export JAVA_HOME=/opt/greeinstall/jdk18111
vi core-site.xml
fs.defaultFS
hdfs://gree:9000
hadoop.tmp.dir
/opt/greeinstall/hadoop260/hadoop2
hadoop.proxyuser.root.hosts
hadoop.proxyuser.root.groups
** vi hdfs-site.xml**
dfs.replication
3
dfs.namenode.secondary.http-address
gree:50090
vi mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
gree:10020
mapreduce.jobhistory.webapp.address
gree:19888
vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
gree
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
vi ./slaves
hadoop101
hadoop102
4.2 Hadoop环境变量配置
vi /etc/profile
export HADOOP_HOME=/opt/greeinstall/hadoop260
export HADOOP_MAPRED_HOME=
H
A
D
O
O
P
H
O
M
E
e
x
p
o
r
t
H
A
D
O
O
P
C
O
M
M
O
N
H
O
M
E
=
HADOOP_HOME export HADOOP_COMMON_HOME=
HADOOPHOMEexportHADOOPCOMMONHOME=HADOOP_HOME
export HADOOP_HDFS_HOME=
H
A
D
O
O
P
H
O
M
E
e
x
p
o
r
t
Y
A
R
N
H
O
M
E
=
HADOOP_HOME export YARN_HOME=
HADOOPHOMEexportYARNHOME=HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=
H
A
D
O
O
P
H
O
M
E
/
l
i
b
/
n
a
t
i
v
e
e
x
p
o
r
t
H
A
D
O
O
P
O
P
T
S
=
"
−
D
j
a
v
a
.
l
i
b
r
a
r
y
.
p
a
t
h
=
HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=
HADOOPHOME/lib/nativeexportHADOOPOPTS="−Djava.library.path=HADOOP_HOME/lib"
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/sbin:$HADOOP_HOME/bin
source /etc/profile
4.3 格式化HDFS
hadoop namenode -format
4.4 启动hadoop
[root@qx1 hadoop]# start-dfs.sh
[root@qx1 hadoop]# start-yarn.sh
[root@qx1 hadoop]# mr-jobhistory-daemon.sh start historyserver
start-all.sh
启动历史服务
[root@qx1 hadoop]# mr-jobhistory-daemon.sh start historyserver
[root@qx1 hadoop]# hdfs dfsadmin -report
5. 测试
5.1 HDFS
[root@qx1 ~]# hdfs dfs -mkdir /input2
[root@qx1 ~]# hadoop fs -mkdir /input3
[root@qx1 ~]# hdfs dfs -ls /
[root@qx1 ~]# hadoop fs -ls /
[root@qx1 ~]# hadoop fs -put ./wordcount.csv /input2
[root@qx1 mapreduce2]# hadoop fs -put /root/wordcount.txt /input2
[root@qx1 mapreduce2]# hadoop fs -rm /input2/*.csv
[root@qx1 mapreduce2]# hadoop jar ./hadoop-mapreduce-examples-2.6.0-cdh5.14.2.jar wordcount /input2 /outputcsv
[root@qx1 mapreduce2]# hadoop fs -cat /outputcsv/part-r-00000















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









