







转载自:https://blog.csdn.net/tic_yx/article/details/21991891
转载自:https://blog.csdn.net/u014211079/article/details/40584721
1. Linux的哈希查找算法
这是Linux操作系统的经典的路由查找算法,直到现在还是默认的路由查找算法。然而它很简单。由于它的简单性,内核(kernel)开发组一直很推崇它,虽然它有这样那样的局限性,但由于Linux内核的哲学就是“够用即可”,因为Linux几乎从来不被用于专业的核心网络路由系统,因此哈希查找法一直都是默认的选择。
1.1. 查找过程
查找结构如下图所示:
查找顺序如下图所示:
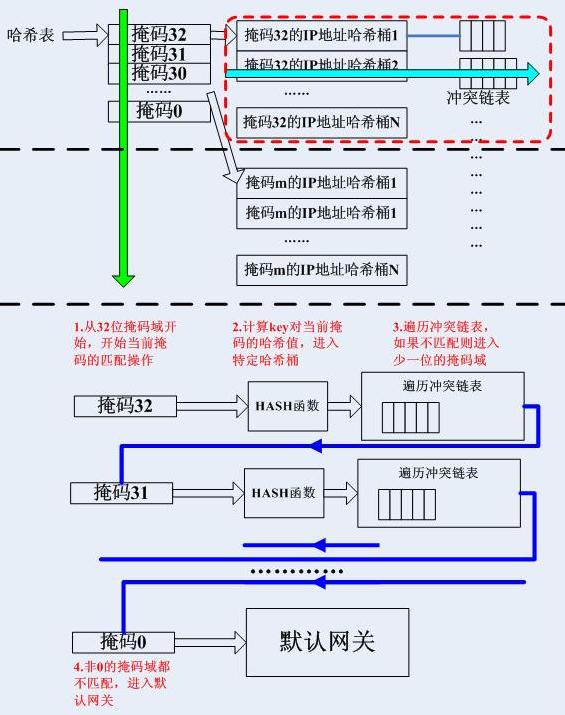
为了实现最长前缀匹配,从最长的掩码开始匹配,每一个掩码都有一个哈希表,目的IP地址哈希到这些哈希表的特定的桶中,然后遍历其冲突链表得到最终结果。
注意,哈希查找算法是基于掩码的遍历来实现严格的最长前缀匹配的,也就是说如果一条最终将要通过默认网关发出的数据报,它起码要匹配32次才能得到结果。这种方式十分类似于传统的Netfilter的filter表的过滤方式-一个一个尝试匹配,而不像HiPac的过滤方式,是基于查找的。接下来我们会看到,高性能的路由器在查找路由的时候使用的都是基于查找型数据结构的方式,最常用的就是查找树了。
2. Trie树
IP地址为32位,当报文在网络上传输时,要在路由表中进行查找。IP地址的对应位如果能与路由表中保存的进行匹配,这些报文就会发送到路由指向的地址。如下面是一个路由表(列出的是网络前缀,掩码对应的主机部分省去了):
Entry
--------
0 0000
1 0001
2 00101
3 010
4 0110
5 0111
6 100
7 101000
8 101001
9 10101
10 10110
11 10111
12 110
13 11101000
14 11101001
目标地址和路由表中的各项比较,如果有多个都能匹配,选择最长的那个,如果没有一个能匹配,使用默认路由。
在内核中,这个路由表由trie来表示:

左孩子表示0,右孩子表示1。这样比如010就会到达节点3的位置。trie数的最大深度理论上可以达到32。
从图中看,有很多空的节点,并且高度太深,为提高效率,可使用路径压缩,这样就变成如下的形状:

每一个空节点都被移除了,在每个节点新增一个变量skip,保存被移除的空节点的个数。这样11101001从根节点开始,先到右边一个节点,再到右边一个节点,再到右边一个节点,这时要跳过4位,最后一位是1,到右边的节点,就到达14的位置。这种方式其实就是谢希仁计算机网络教材中提到的对每个ip地址取出唯一的前缀。
再进行优化,对trie的层级进行压缩,就成为LC-tries,最后变成下面的形状:

一个节点,如果它只有两个节点且左右节点都存在,用两个子节点代替这个节点,如果节点的两个节点都为叶子节点,则停止替换。这个替换可在子树中进行重复。















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









