










✨:MYSQL入门阶段三
MYSQL
前言
提供给正在学习的伙伴们
背景:随着大数据时代的到来,很多时候都需要我们对数据有更多的收集和处理方法。而MYSQL能够满足我们大多数时候针对海量数据的处理,打破了仅会excel来处理数据的局限性
提示:以下是本篇文章正文内容,健康“食品”,放心食用
一、MYSQL进阶查询
查询的排序、聚合、分组、多表查询、合并查询以及子查询
1.1 排序查询
排序:order by 查询子句,且默认是 升序 排序
select 列名 from 表名 [where 字段 = 值] order by 列名 [asc / desc]
| 字符 | 说明 |
|---|---|
| Asc | 升序 |
| Desc | 降序 |
select
tid as 'ID',
tname as '姓名',
salary as '薪资'
from test_emp
where tid < 09
order by tid desc;
当进行多字段进行排序时:先是 salary进行排序,后根据tid排序;如果salary相同,则根据tid排先后
select
tid as 'ID',
tname as '姓名',
salary as '薪资'
from test_emp
where tid < 09
order by salary desc,tid desc;
1.2 聚合函数查询
聚合:聚合函数
select 聚合函数(列名) from 表名
| 函数 | 说明 |
|---|---|
| count(字段) | 计数 |
| sum(字段) | 求和 |
| max(字段) | 最大值 |
| min(字段) | 最小值 |
| avg(字段) | 均值 |
# 统计有多少人
select count(tname) from test_emp;
# 统计有多少人的薪资大于8000
select count(tname) from test_emp where salary > 8000;
# 计数薪资
select
sum(salary) as '薪资总和',
max(salary) as '薪资最大值',
min(salary) as '薪资最小值',
avg(salary) as '平均薪资'
from test_emp;
1.3 分组查询
分组:分组子句,group by
select 聚合函数(列名1) from 表名 group by 列名1 [HAVING 条件]
分组通常会与聚合函数同时出现;对分组后各组内的数据进行统计聚合
| 条件 | 说明 |
|---|---|
| where | where是分组前进行过滤,并且where不能写聚合函数 |
| having | having是分组后进行过滤,且having后面可以写聚合函数 |
# 分别查看男女的薪资总和
select
tsex,
sum(salary)
from test_emp
gruop by tsex;
# 姓'张'的男女平均薪资
select
tsex as '性别',
avg(salary) as '平均薪资'
from test_emp
where tname like '%张%'
group by tsex;
# 平均薪资大于5000的男女是谁
select
tname as '姓名',
tsex as '性别',
avg(salary) as '平均薪资'
from test_emp
group by tsex, tname
having avg(salary) > 5000;
1.3 limit限制子句
limit限制子句
select 字段1,字段2… from 表名 limit offset , length
offset:是起始行数, 从0开始记数, 如果省略 则默认为 0
length:是返回的行数
select * from test_emp limit 0,10;
二、MYSQL的建表约束
2.1 建表约束
约束的作用:
对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性。违反约束的不正确数据,将无法插入到表中
注意:约束是针对字段的
常见约束:
| 名称 | 说明 |
|---|---|
| 主键 | primary key |
| 外键 | foreign key |
| 唯一 | unique |
| 非空 | not null |
创建一个 test_emp_new表:
create table test_emp_new
(
tid int primary key,
tname varchar(32) not null,
tdate date,
tsex varchar(32),
salary decimal(5,2)
);
创建一个 test_new表:
create table test_new
(
eid int foreign key,
manager varchar(32),
brand varchar(32)
);
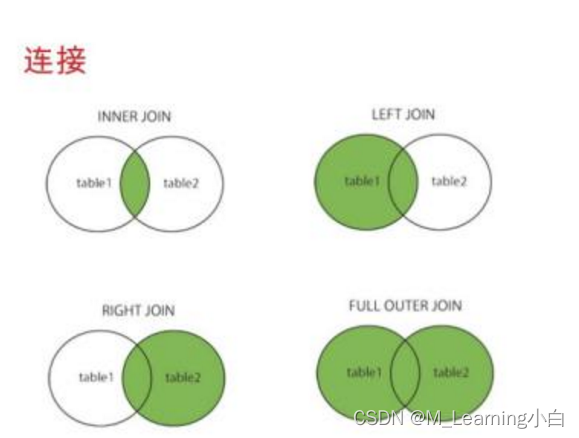
三、多表查询
内连接:隐式内连接、显示内连接
外连接:左连接、右连接
3.1 内连接查询
3.1.1 隐式内连接
select 字段名 from 左表, 右表 where 连接条件;
# 方式一:
select * from test_emp_new, test_new where tid = eid;
# 方式二:
select
t.tname,
t.salary,
te.manager
from test_emp_new as t, test_new as te
where t.tid = te.eid;
3.1.2 显示内连接
select 字段 from 左表 [ inner ] join 右表 on 条件
# 方式一:
select * from test_emp_new join test_new on tid = eid;
# 方式二:查询 '张某'的薪资、管理员
select
t.tname,
t.salary,
te.manager
from test_emp_new as t inner join test_new as te
on t.tid = te.eid
where t.tname like '张_';
3.2 外连接查询
3.2.1 左连接
以左表为基准, 匹配右边表中的数据,如果匹配的上,就展示匹配到的数据。如果匹配不到,左表中的数据正常展示,右边的展示为null。
select 字段名 from 左表left [ outer ] join 右表 on 条件
select
t.tname,
te.manager
from test_emp_new as t left join test_new as te
on t.tid = te.eid
3.2.2 右连接
与左连接相似
select 字段名 from 左表right [ outer ] join 右表 on 条件
select
t.tname,
te.manager
from test_new as te left join test_emp_new as t
on te.eid = t.tid
3.3 合并查询
3.3.1 union
union 操作符用于合并两个或多个 select 语句的结果,并自动消除重复行。
但是,union 连接的两个 select 语句必须拥有相同数量的列。且列也必须拥有相似的数据类型。同时, select 语句中的列的顺序必须相同。
select
字段a,字段b
from 表A
union
select 字段a,字段b
from 表B
# 若 A、B 两个表有相同字段 id,city;合并A、B表的id、city
select
id as '编号',
city as '城市'
from A
union
select
id as '编号',
city as '城市'
from B
# 若 A表字段 id,city;B表字段city,province ;合并A、B表
select
id as '编号',
city as '城市'
from A
union
select
city as '城市',
province as '省份'
from B
注意:
- 列数必须相同;
- 相同的列数据类型必须在相同
- 列的名称不必相同
- NULL值不会被忽略
3.3.2 union all
union all 运算符用于将两个 select 语句的结果组合在一起,重复行也包含在内
select
字段a,字段b
from 表A
union all
select 字段a,字段b
from 表B
总结:
1、重复值:UNION在进行表连接后会筛选掉重复的记录,而Union All不会去除重复记录。
2、在执行效率上,UNION ALL 要比UNION快很多。因此,合并的两个结果不包含重复数据,那么就使用UNION ALL。
四、子查询
4.1 子查询类别
1、where 型子查询:把子查询的结果,作为父查询的比较条件
select 字段 from 表 where 字段 =(子查询);
select
tid as 'ID',
tname as '姓名'
from test_temp_new
where salary = (select avg(salary) from test_emp_new);
2、from 型子查询:把子查询的结果,作为 一张表,提供给父层查询使用
select 字段 from (子查询)表别名 where 条件 ;
select
t.tid as 'ID',
t.tname as '姓名'
from test_temp_new as t
left join
(select eid, manager from test_new) as p
on t.tid = p.eid;
3、exists 型子查询:子查询的结果类似一个数组, 父层查询使用 IN 函数
select 字段 from 表名 where 字段 in(子查询);
select
t.tid as 'ID',
t.tname as '姓名'
from test_temp_new
where salary in (select salary from test_emp_new where salary > 9000)
五、MYSQL函数
5.1 数学函数
| 函数 | 说明 |
|---|---|
| ABS(x) | 返回 x 的绝对值 |
| FLOOR(x) | 向下取整 |
| CEIL(x) | 向上取整 |
| RAND(x) | 0~10 的随机数 |
| PI(x) | x 的圆周率 |
| MOD(x, y) | 返回x 除以y 以后的余数 |
5.2 字符串函数
| 函数 | 说明 |
|---|---|
| CONCAT(x1,x2) | 把 x1,x2 拼接在一起 |
| LEFT(x,n) | 返回 x 的从左侧获取的n 位字符 |
| TRIM(x) | 去除 x 开头或者结尾的空格 |
| REPLACE(x,s1,s2) | 用字符串 s2 替代 s 中的字符串 s1 |
| SUBSTRING(x,n,len) | 截取 x 中第 n 个位置开始,长度为 len 的字符串 |
| MID(x,n,len) | 截取 x 中第 n 个位置开始,长度为 len 的字符串 |
| REVERSE(x) | 将 x 的顺序翻转过来 |
5.3 日期与时间函数
| 函数 | 说明 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| MONTH(t) | 返回月份 |
| YEAR(t) | 返回年份 |
5.4 条件判断函数
| 函数 | 说明 |
|---|---|
| IF(expo,v1,v2) | 如果表达式成立,则执行v1,否则执行v2 |
| CASE WHEN | 用于计算条件列表并返回多个可能结果表达式之一 |
总结
仅仅只是小白的一个学习过程,也望能够帮助大家。会不定期更新~~~















 43万+
43万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









