






1.何为索引?有什么作用?
- 索引是一种用于快速查询和检索数据的数据结构。索引就相当于目录。为了方便查找书中的内容,通过对内容建立索引形成目录。索引是一个文件,它是要占据物理空间的。
2.索引的优缺点
优点——使用索引可以大大加快 数据的检索速度(大大减少检索的数据量)性。降低数据库的IO成本。
缺点——创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改+索引需要使用物理文件存储,也会耗费一定空间。
3.索引的类型
主键索引+二级索引(起辅助的作用)(包括以下四个)
- 1.唯一索引(Unique Key) :唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
2.普通索引(Index) :普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
3.前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。
4.全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
4.索引的底层数据结构*
哈希表和B+树
1.原理——哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据
缺点——Hash 索引不支持顺序和范围查询
2.B+树
实则为多路平衡查找树
B 树& B+树两者有何异同呢?
- 树的所有节点既存放键(key) 也存放 数据(data),而 B+树只有叶子节点存放 key 和 data
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
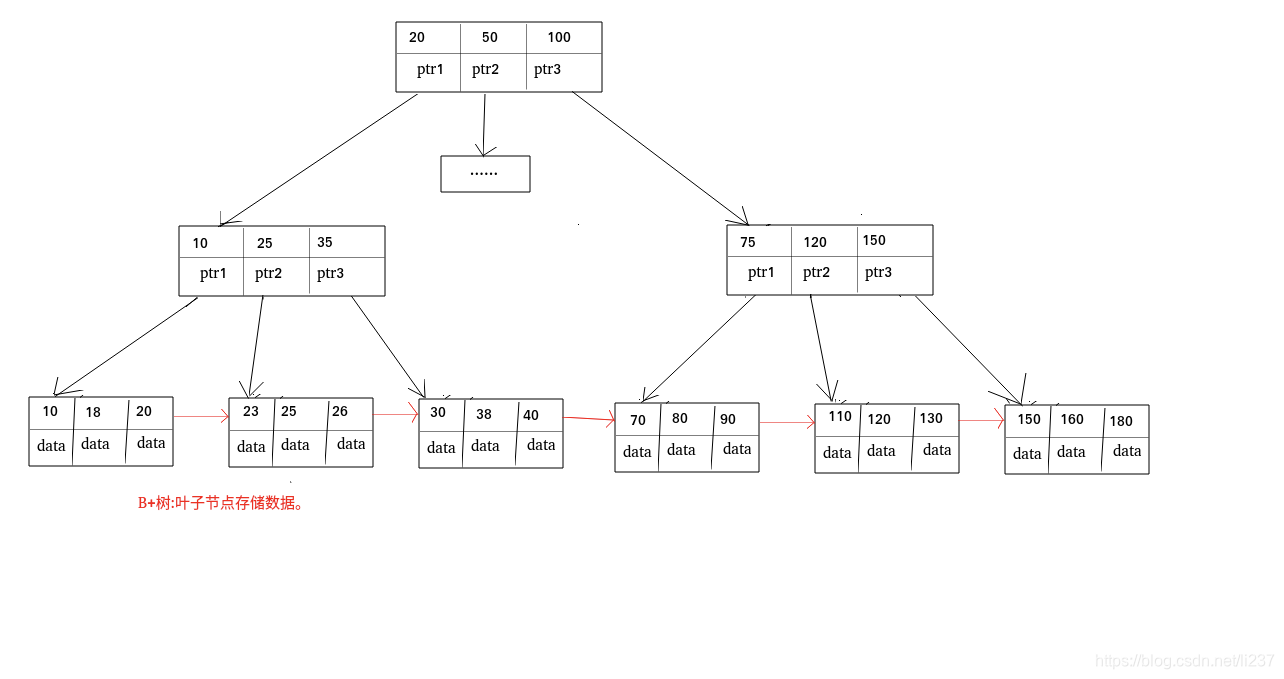
B+树可以保证等值和范围查询的快速查找
聚集索引与非聚集索引
聚集索引
聚集索引即索引结构和数据一起存放的索引。数据表的主键列使用的就是主键索引。主键索引属于聚集索引。
在 Mysql 中,InnoDB 引擎的表的 .ibd文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,**叶子节点存储索引和索引对应的数据**。
非聚集索引
非聚集索引即索引结构和数据分开存放的索引。二级索引属于非聚集索引。
每个叶子非叶子节点存储索引, 叶子节点存储索引和索引对应数据的指针
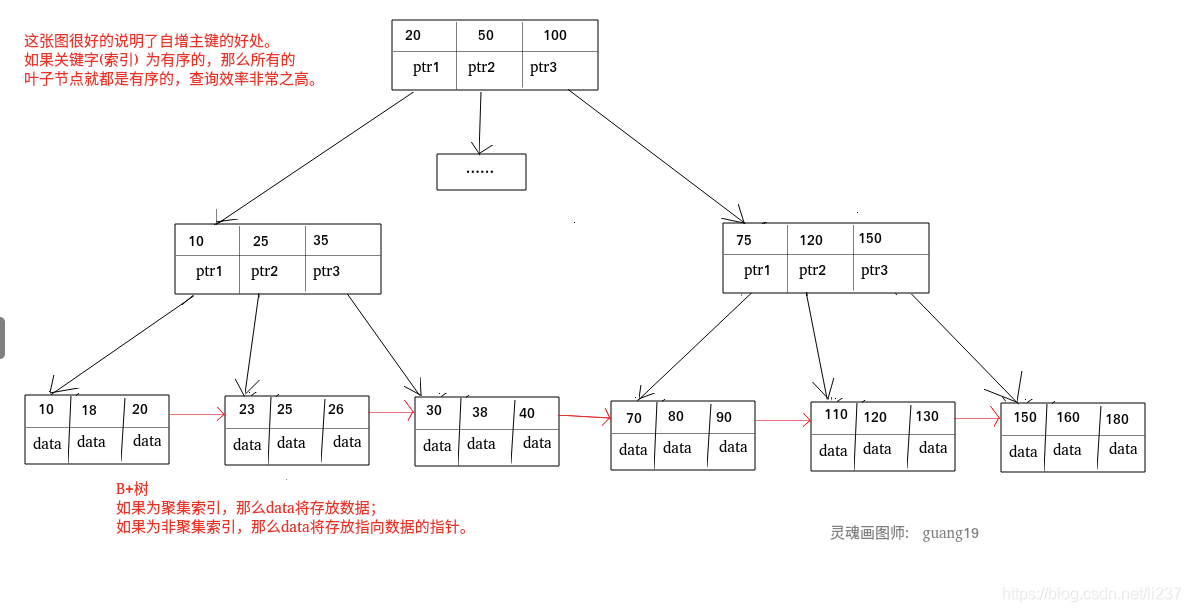
很好地说明了问题
索引具体实现
使用B+树构建索引树时,叶子节点中存储的键值为索引列的值,数据为索引所在行的磁盘地址。
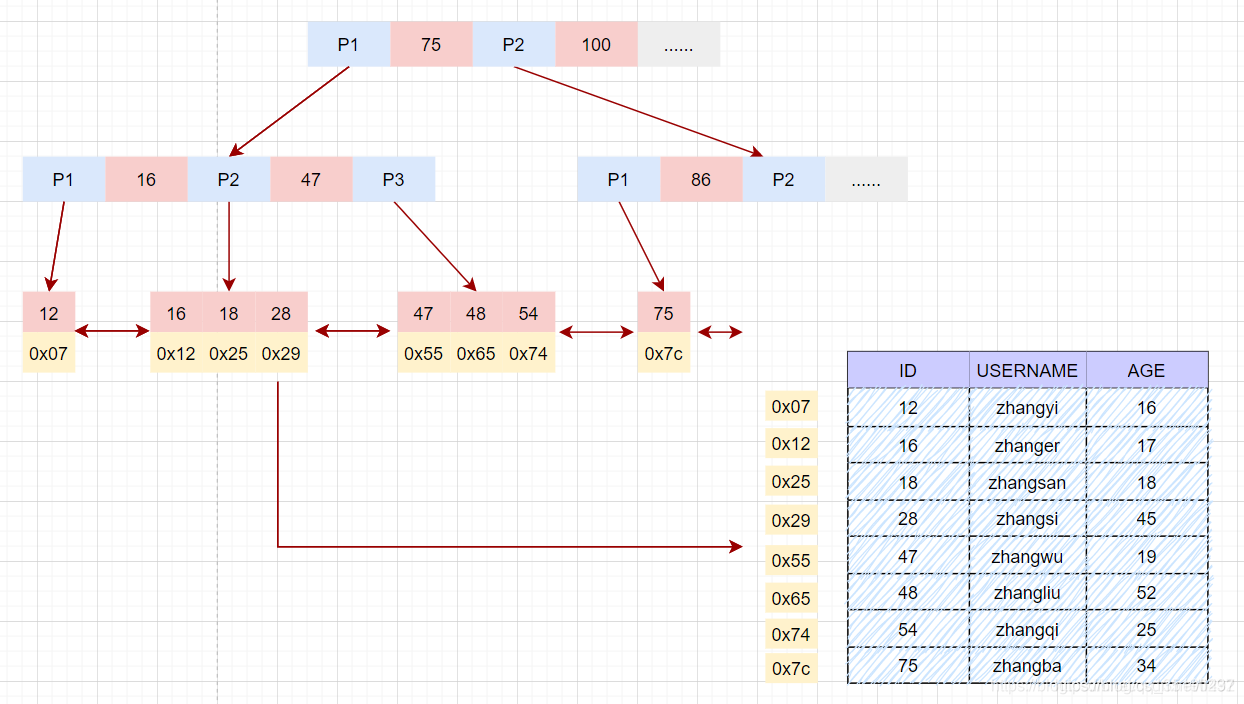
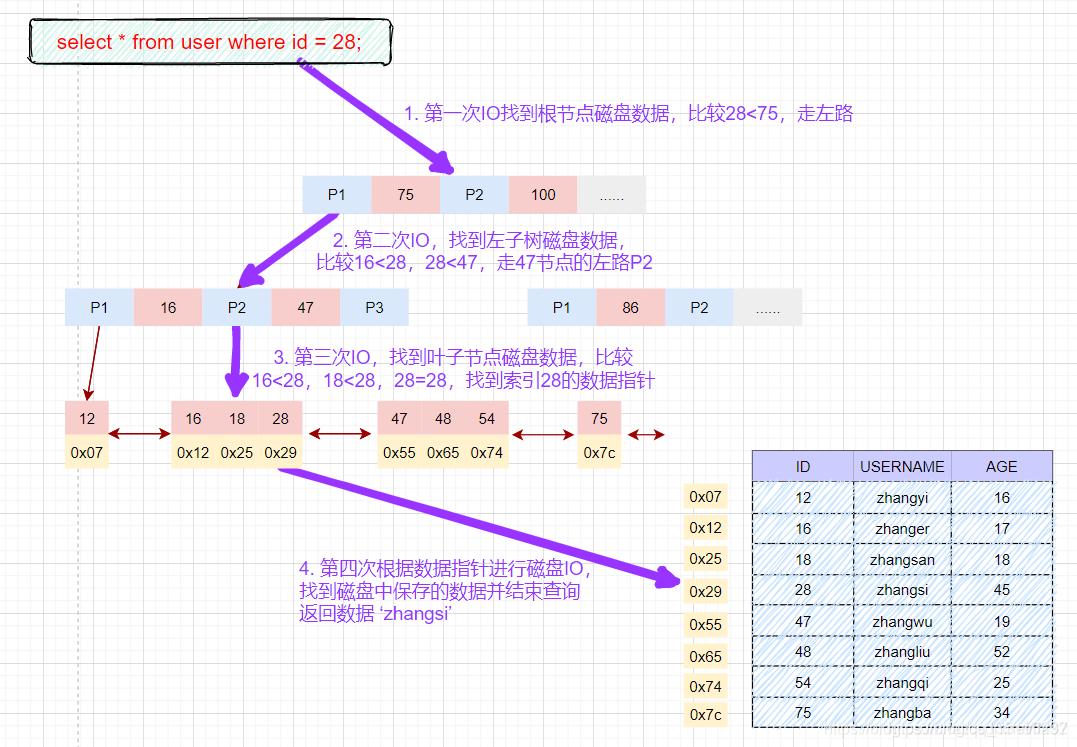
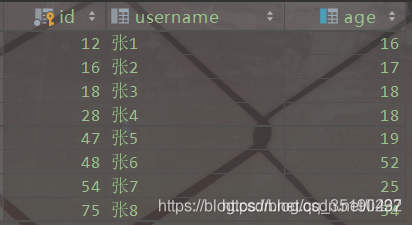
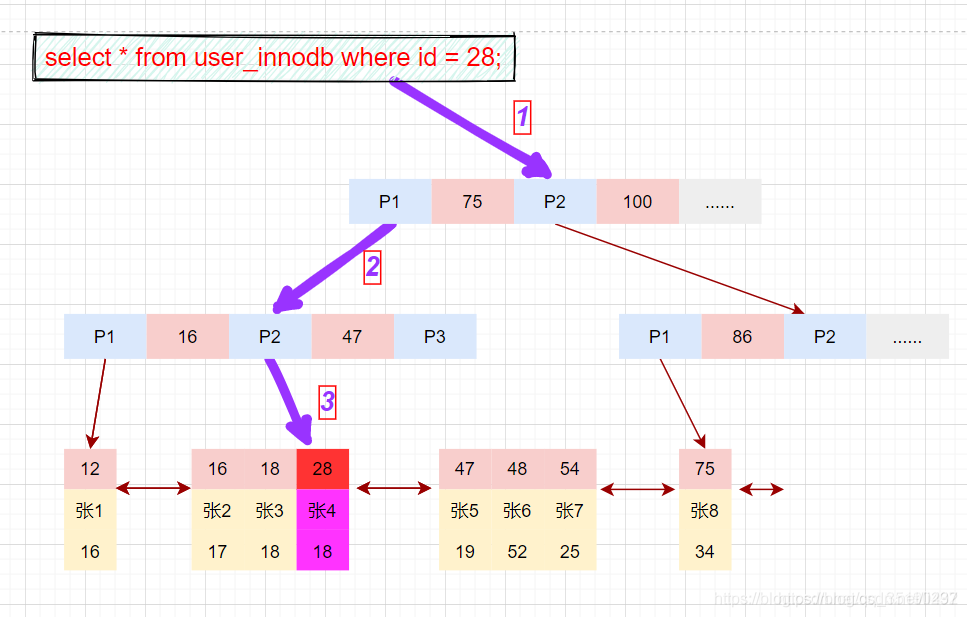
根据主键等值查询数据:
select * from user where id = 28;
具体的过程
聚集索引与非聚集索引
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值,再根据主键值获取整行的数据。
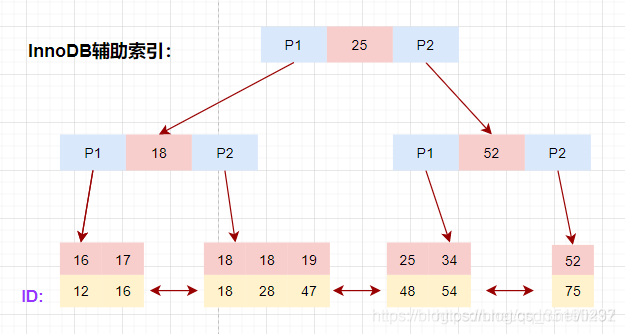
辅助索引
以表user_innodb的age列为例,age索引的索引结果如下图。(这里也可以说明辅助索引的作用就是帮助找到主键的)
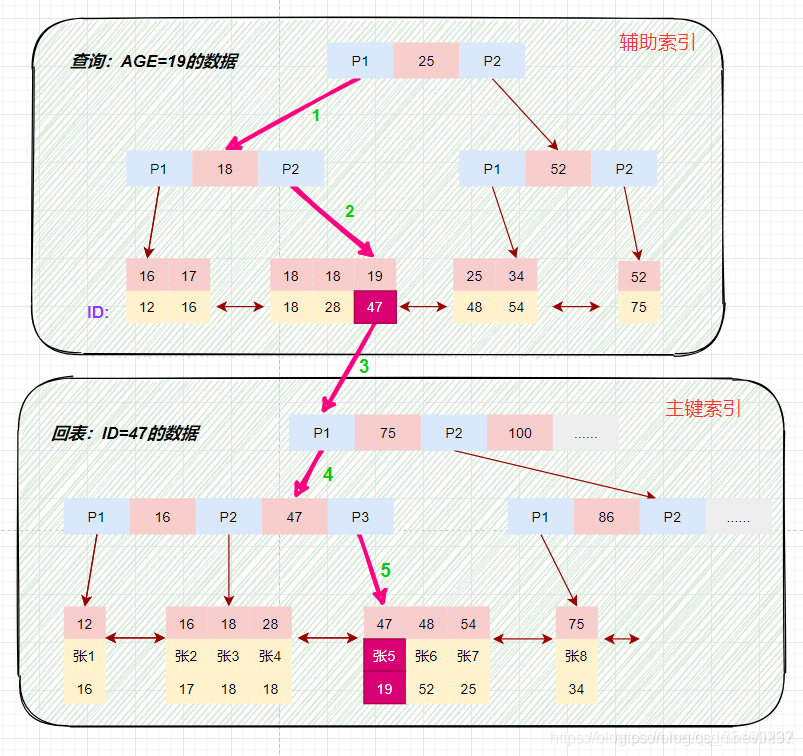
根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
[最左匹配原则:](看这里)
出现的背景——再组合索引中
例如,建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。
使用组合索引查询时,mysql会一直向右匹配(先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。b列相同再比较c列)直至遇到范围查询(>、<、between、like)就停止匹配。
覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
例如 select a,b,c from table 选中了abc这三个字段,而他们恰巧是组合索引idx_abc(a,b,c),则就是这个索引就是覆盖索引了
PS;被频繁更新的字段应该慎重建立索引。
尽可能的考虑建立联合索引而不是单列索引。
注意避免冗余索引 。
虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
此外
- 对于组合索引,where条件如果只包含组合索引的个别字段时,必须是从前往后,否则查询语句不会走索引。比如有一个组合索引是订单ID+用户ID,如果以用户ID为查询条件,无法使用这个索引;而用订单ID查询,可以使用该索引,这是索引的存储数据结构决定的。














 5476
5476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









