







先说下DataNode为啥会处于Stale状态
默认情况下,DataNode每3s向NameNode发送一次心跳,如果NameNode持续30s没有收到心跳,就把DataNode标记为Stale状态;再过10分钟还没收到心跳,就标记为dead状态
NameNode有个jmx指标hadoop_namenode_numstaledatanodes,进入statle状态的DataNode数量,正常情况这个值应该是0,如果不是0则应该触发告警
DataNode有个jmx指标hadoop_datanode_heartbeatstotalnumops,表示心跳发送次数,通过prometheus函数increase(hadoop_datanode_heartbeatstotalnumops[1m]),可以得出1分钟内的心跳发送次数
监控发现有个节点存在心跳次数为0的情况:
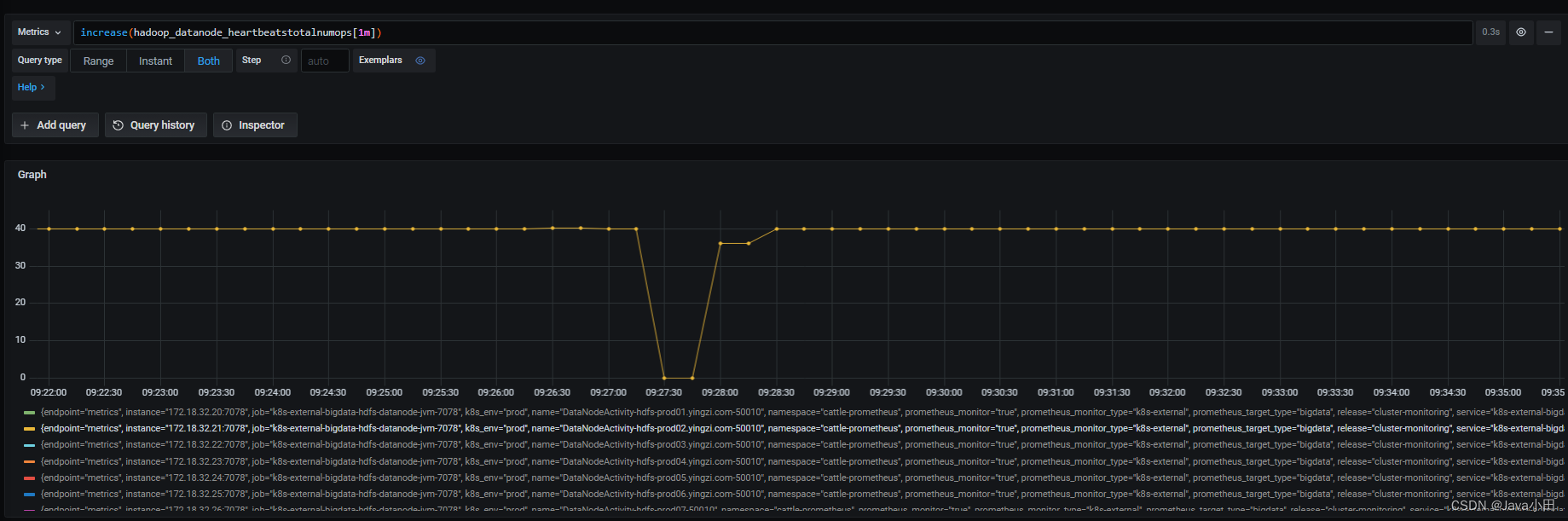
观察这段时间DataNode的JVM状态,发现GC非常频繁,1分钟高达90次:
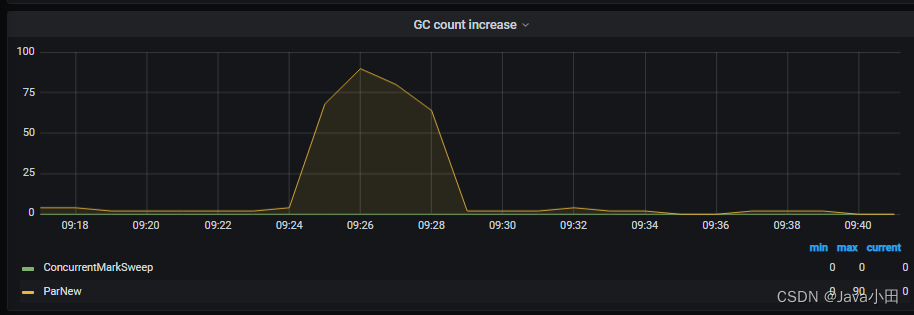
再查看这个节点的日志,发现有一条警告日志:
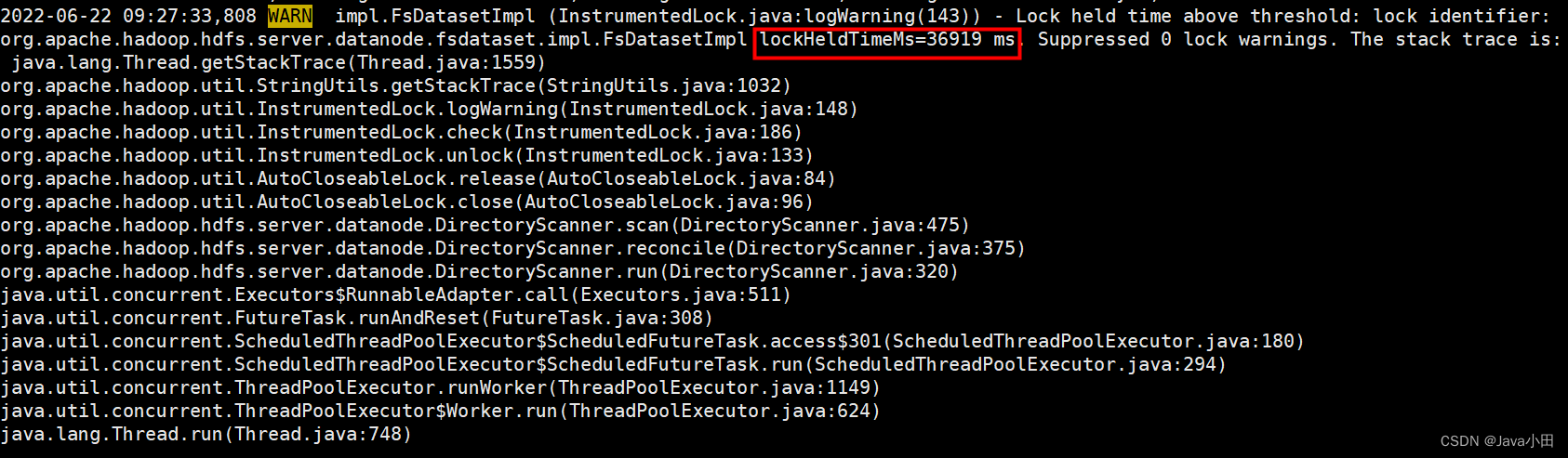
主要代码在org.apache.hadoop.hdfs.server.datanode.DirectoryScanner.scan()
大致是DataNode会定期扫描磁盘上的数据块,检查是否和内存中的数据块信息一致。开始对比前要先获取锁,完成后释放锁时会进行一个检查,如果持有锁的时间超过阈值(300ms),就会打印警告日志
这里锁持有时间为36s,有点太长了,猜测原因是DataNode存储配置不合理,只配置了一块磁盘,且数据量较大,数据块非常多,导致对比耗时比较久
而这个时间和DataNode心跳缺失的时间也正好相符
抽查了几次出现心跳发送异常的时间点,都有发现这个警告日志
大概率就是因为这个影响到心跳发送
官方也有对应的issue:
https://www.mail-archive.com/hdfs-dev@hadoop.apache.org/msg43698.html
https://issues.apache.org/jira/browse/HDFS-16013
https://issues.apache.org/jira/browse/HDFS-15415
在3.2.2, 3.3.1, 3.4.0版本中解决了这个问题,除了优化性能,最关键是把锁去掉了,及时耗时再久,也不会因为长时间持有锁而影响DataNode健康状态
升级版本对我们来说难度比较大
先继续观察,看这个情况会不会造成其他更大的影响
除了升级版本,把DataNode改为多个目录,每个目录一块较小的磁盘,应该也能起到优化效果
参考文章:
如何识别datanode stale
谈一谈 DataNode 如何向 NameNode 发送心跳的
DataNode之DirectoryScanner分析
HDFS核心源码解析(三)——DataNode的心跳机制















 5601
5601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









