







 本文介绍了SPPF模块,它是SPP(空间金字塔池化)的改进版,通过串行结构降低计算量,主要作用在于融合不同尺度下的特征,增强特征图语义。在Yolov5中,SPPF保持输入和输出特征图维度不变,用于特征融合而非固定特征向量生成。
本文介绍了SPPF模块,它是SPP(空间金字塔池化)的改进版,通过串行结构降低计算量,主要作用在于融合不同尺度下的特征,增强特征图语义。在Yolov5中,SPPF保持输入和输出特征图维度不变,用于特征融合而非固定特征向量生成。
上两篇讲完了conv和c3模块,本篇来介绍一下sppf模块
spp和sppf
spp的全称是Spatial Pyramid Pooling,意思是空间金字塔池化,是一种用于图像识别和目标检测的技术,其作用是在不同尺度下对图像进行特征提取和编码,它可以将任意大小的输入图像重新缩放到固定大小,并生成固定长度的特征向量。而sppf,就是把spp原来并行的结构改成了串行结构,减少了计算量(速度更快,f即fast),而且发挥spp相同的作用
结构图:
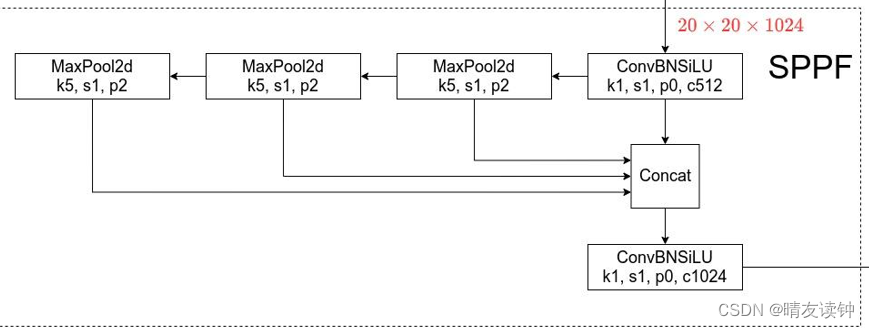
在本结构中,maxPool2d是max pooling操作的一种实现方式
max pooling是一种常用的池化操作,用于减少卷积神经网络中特征图的维度。它通过在不重叠的小区域内选择最大值来实现。
其作用主要有以下几个方面:
1.特征压缩:max pooling将每个小区域内的最大值作为该区域的代表,
因此可以减少特征图的尺寸和参数数量,从而降低计算复杂度,并且可以有效地抽取主要的特征信息。
2.位置不变性:由于max pooling只保留了每个小区域内的最大值,
因此对输入特征的微小偏移或变形不敏感,使得神经网络具有一定的平移不变性和旋转不变性。
3.特征提取:max pooling通过选择每个小区域内的最大值,
可帮助提取图像中最显著的特征,如边缘、纹理等,从而更好地捕捉有用的信息,提高模型的判别能力。max pooling用于减少特征图的维度,在sppf模块中,首先经过一次conv模块完成对输入特征图的一次压缩操作,然后进行3次串行的一模一样的MaxPool2d,spp则是经过3个kernel_size分别为5,9,13的MaxPool2d,也就是说
两次串行的MaxPool2d等效于kernel_size为5和9的两个并行MaxPool2d,三次串行的MaxPool2d等效于kernel_size为5,9,13的三个并行MaxPool2d,当然这好像并不是什么重点,反正本人目前认为sppf就是不仅能更快地完成spp的所有工作,还没有什么副作用,那何必还去细究spp?
sppf的concat模块会针对3次池化操作后及池化前的4个维度的特征图进行融合,融合完特征再进行一次conv模块升维,所以我们惊奇的发现,在backbone部分中,输入sppf模块的特征图是20*20*1024,最后输出结果仍然是20*20*1024,似乎并没有完成所谓的“输出固定特征向量”的操作,所以个人理解,sppf在yolov5中的主要作用是融合多尺度特征。将同一特征图不同尺度下的特征融合到一起,丰富特征图的语义特征。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









