







Hdfs笔记
1、 分布式文件系统
主节点:数据目录(元数据)服务
从节点:具体完成数据的存储任务
HDFS:兼容廉价的硬件设备,实现流数据读写,支持大数据集,支持简单的文件模型,强大的跨平台兼容性
HDFS局限性:不适合低延迟数据访问,无法高效存储大量小文件,不支持多用户写入以及任意修改文件。
2、 HDFS相关概念
快:
1、为了分摊磁盘读写开销,也就是在大量数据间分摊磁盘寻址开销
2、HDFS的一个快要比普通文件系统的快大很多,默认64MB,也可配置
三级寻址:
元数据目录,数据节点,从数据节点取数据
快的优点:
1、支持大规模文件存储
2、简化系统设计
3、适合数据备份
名称节点:
主节点就是名称节点,管理HDFS集群(记录快信息,提供数据目录)
元数据:
文件是什么,文件被分成多少块,每个块文件是怎么映射的,每个块被存储在哪个服务器上边 。
元数据(核心数据结构结构)
FsImage(保存系统文件树),EditLog(记录对数据进行的诸如创建,删除,重命名等操作)。
FsImage:(存储的是文件历史信息)
文件的复制等级,修改和访问时间,访问权限,快大小及组成文件的块
EditLog:(存储对文件的操作信息)
在每次启动名称节点的时候将FsImage和EditLog信息加载到内存合并才可得到最新元数据,然后保存新的FsImage,和创建一个空的EditLog
第二名称节点:
1、名称节点的冷备份,
2、对EditLog的处理,定期和名称节点通信,当EditLog不断增大,在某个阶段会请求名称节点停止使用EditLog,名称节点收到信息后会立刻停止,生成一个新的edits.new==EditLog,老的EditLog和FsImage会被第二名称节点通过hdfs get下载到本地,然后合并,将新的FsImage发送给名称节点,名称节点将edits.new命名为EditLog。
数据节点:
实际存储数据
HDFS命名空间:
目录,文件,快,Tcp/IP通信协议,RPC协议(远程调用)
局限性:
命名空间限制,名称节点是保存在内存中的,因此名称节点能够容纳的数据会受到空间大小的限制。
性能瓶颈,这个分布式文件的吞吐量,受限于单个名称节点的吞吐量。
隔离问题:由于集群中只有一个名称几点,只有一个命名空间,因此无法对不同应用程序进行隔离
集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用,虽然有第二名称节点,但它是冷备份。
3、HDFS存储原理
冗余数据保存问题
底层是非常廉价的机器,出故障是常态
以快为单位进行冗余保存备份,默认是3块,但是也可以个性化配置,在伪分布式中冗余因子只能为一,因为名称节点和数据节点都在一台机器上,不存在冗余
优点:
- 加快数据传输速度
- 很容易检测数据错误
- 保证数据可靠性
数据保存策略问题
第一个快到达复制三个副本第一块放在上传文件的节点(如果不是集群中的节点提交的数据,HDFS会随机挑选一台磁盘不太满,CPU又不忙的一台节点存放)第二副本,将它放在与第一块不同的机架上,第三个副本放在同一机架的不同节点上。(个人感觉不太合适,在Hadoop权威指南上有比较严密的解释)
数据读取:
就近原则。
HDFS提供了一个API,可以确定一个数据节点所属机架ID,客户端可以调用
数据恢复的问题
名称节点出错
FsImage和EditLog,整个HDFS实例将失效,启动备份,Hadoop2.x有热备份数据节点出错
数据节点定期向名称节点发送心跳,如果隔一个周期收不到数据节点的心跳信息,名称节点就认为该数据节点宕机,标记为不可用。将该节点上的数据重新复制(冗余备份)到其他正常可用的机器上。数据本身出错
校验码,客户端读取数据之后进行校验码校验,校验码是在整个文件被创建的时候,客户端每次往里写一个文件的时候都会为这个数据块生成一个校验码,并保存在同一个目录下面去。
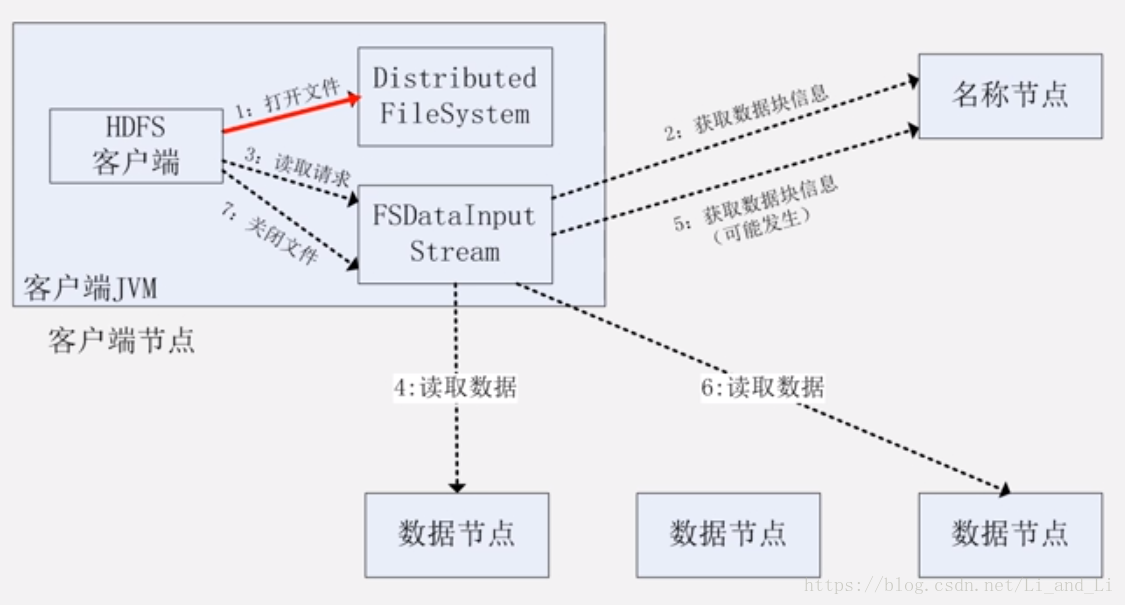
4、 数据读写过程
读取:
hdfs-site.xml
core-site.xml
–>获取一个fs.defaultFShdfs:/ip:port
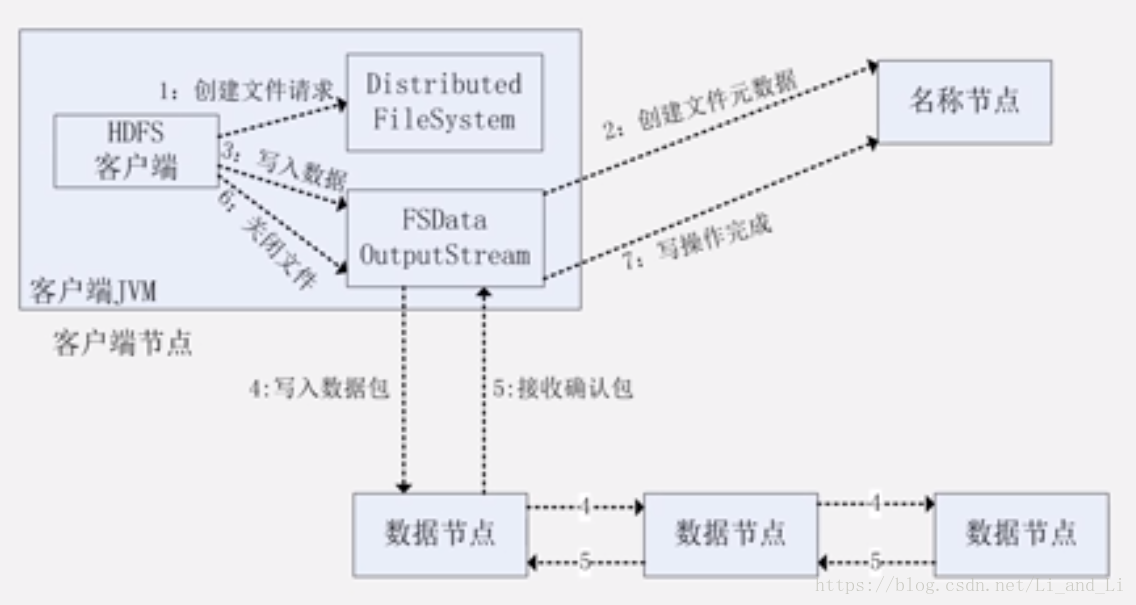
写入:














 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









