







上一篇我们讲解了TIMIT的训练步骤,现在利用训练好的模型,进行在线语音识别。
在kaldi 的工具集里有好几个程序可以用于在线识别。这些程序都位在src/onlinebin文件夹里,他们是由src/online文件夹里的文件编译而成(你现在可以用make ext 命令进行编译).这些程序大多还需要tools文件夹中的portaudio 库文件支持,portaudio 库文件可以使用tools文件夹中的相应脚本文件下载安装。注:online官方不再维护,新版本为online2,不过先从简单的online开始。
这些程序罗列如下:
online-gmm-decode-faster: 从麦克风中读取语音,并将识别结果输出到控制台
online-wav-gmm-decode-faster:读取wav文件列表中的语音,并将识别结果以指定格式输出。
online-server-gmm-decode-faster:从UDP连接数据中获取语音MFCC向量,并将识别结果打印到控制台。
online-net-client :从麦克风录音,并将它转换成特征向量,并通过UDP连接发送给online-server-gmm-decode-faster
online-audio-server-decode-faster :从tcp连接中读取原始语音数据,并且将识别结果返回给客户端
online-audio-client :读出wav文件列表,并将他们通过tcp 发送到online-audio-server-decode-fater,得到返回的识别结果后,将他存成指定的文件格式
代码中还有一个java版的online-audio-client ,他包含更多的功能,并且有一个界面。另外,还有一个与GStreamer 1.0兼容的插件,他可以对输入的语音进行识别,并输出的文字结果。这个插件基于onlinefasterDecoder,也可以做为在线识别程序
1、安装portaudio
首先我们cd到tools下面,执行:sudo ./install_portaudio.sh,然后在cd到src下面,执行:sudo make ext
(我第一次在线live识别的时候portaudio报错,解决方法是:先进入tools/portaudio,用./configure查看依赖,通常情况alsa显示no,通过sudo apt-get install libasound-dev可以解决。然后进入/tools,执行:./install_portaudio.sh。回到/src目录,编译扩展程序:make ext 。可以用arecord测试一下Ubuntu录音机是否正常:arecord -f cd -r 16000 -d 5 test.wav )
2、接下来跑tri1。去egs下,打开voxforge,里面有个online_demo,直接拷贝到timit下,和s5同级。在online_demo里面建2个文件夹online-data work,在online-data下建两个文件夹audio和models,audio下放你要回放的wav,models建个文件夹tri1,把s5下的exp下的tri1下的final.mdl和35.mdl拷贝过去。把s5下的exp下的tri1下的graph_word里面的words.txt,和HCLG.fst,拷贝到models的tri1下。
3、修改修改tri1地址online_demo下的run.sh
1) 修改tri1位置
#ac_model_type=tri2b_mmi
ac_model_type=tri1
2)注释掉如下代码(这段是voxforge例子中下载现网的测试语料和识别模型的。我们测试语料自己准备,模型就是tri1了)
#if [ ! -s ${data_file}.tar.bz2 ]; then
# echo "Downloading test models and data ..."
# wget -T 10 -t 3 $data_url;
#
# if [ ! -s ${data_file}.tar.bz2 ]; then
# echo "Download of $data_file has failed!"
# exit 1
# fi
#fi
3) 修改model为final.mdl
# online-wav-gmm-decode-faster --verbose=1 --rt-min=0.8 --rt-max=0.85\
# --max-active=4000 --beam=12.0 --acoustic-scale=0.0769 \
# scp:$decode_dir/input.scp $ac_model/model $ac_model/HCLG.fst \
# $ac_model/words.txt '1:2:3:4:5' ark,t:$decode_dir/trans.txt \
# ark,t:$decode_dir/ali.txt $trans_matrix;;
online-wav-gmm-decode-faster --verbose=1 --rt-min=0.8 --rt-max=0.85\
--max-active=4000 --beam=12.0 --acoustic-scale=0.0769 \
scp:$decode_dir/input.scp $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' ark,t:$decode_dir/trans.txt \
ark,t:$decode_dir/ali.txt $trans_matrix;;
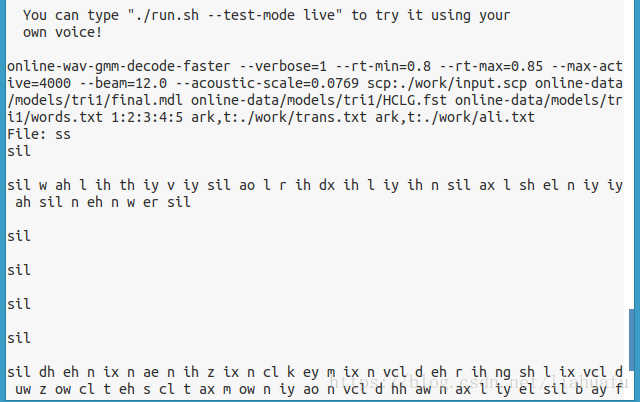
4、./run.sh开始识别audio文件夹下的语音(这个语音参数需要16bit,16Khz,我用Audacity录了几段)。./run.sh --test-mode live 命令就是从麦克风识别(如果提示错误,可参考https://blog.csdn.net/u012236368/article/details/71628777)。














 2040
2040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









