






前言告示窗
水友留言:想多了解下爬虫解析网页时提取数据的代码解析,这期文档T来了,本期通过Beautiful、lxml、parsel模块进行提取,绝对的干货,是小编在坑坑中连滚带爬刨出来的,废话不多说直接上案例:
《爬取携程旅行相关信息》
本期"受害者"网址——重庆旅游,重庆旅游景点,十一月重庆旅游线路报价【携程旅游】
网址信息分析:
目标:爬取题目和旅游简介
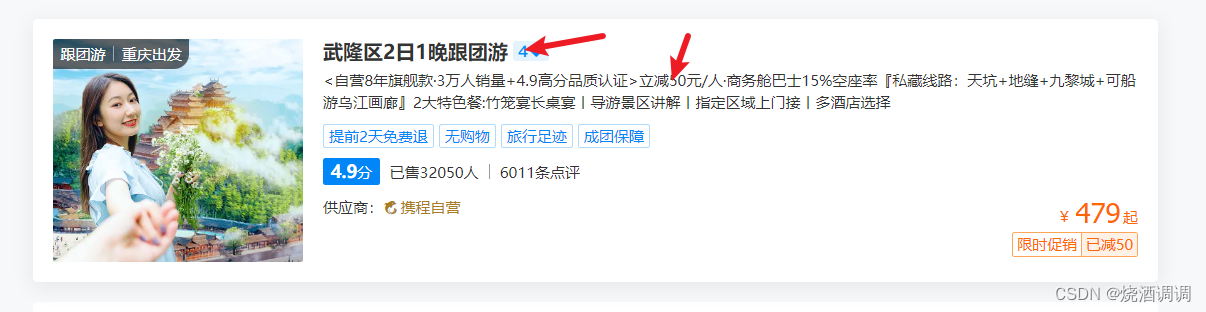
网页源代码分析:
1.找到一级标签div.main_col,二级标签div.list_ad_box
2.发现二级标签结构不一样,class属性不同
3.但是二级标签有共同的相似点
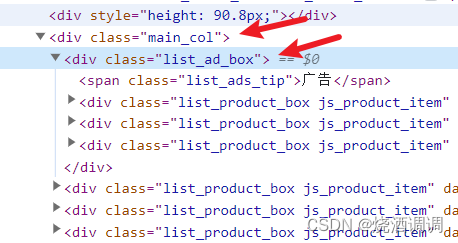
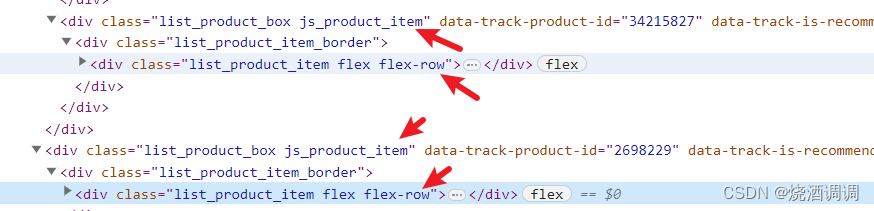
4.所以后续提取时可以抓住标签相同点进行提取
上面三块是一个单位,下面多块分别为一个单位
5.网页构建headers和payload查询参数

查询参数可以参照网址,key = value形式为查询参数
![]()
parsel模块之xpath和css语法
#网页分析这是一个静态网页
import requests
import parsel
#请求头
headers={
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
'Cookie':'GUID=09031041414364265179; MKT_CKID=1695913650540.6gjq0.ea77; _RSG=__qZDNTgOpElpgskrq5cH9; _RDG=2883981c00394a25da041af7fa773d62c8; _RGUID=ecd8a9d5-cd8f-4fff-9466-174d6edaacef; _bfaStatusPVSend=1; nfes_isSupportWebP=1; UBT_VID=1695913650066.12ysue; intl_ht1=h4=37_2036785,2_7937525; MKT_CKID_LMT=1699421067940; _RF1=183.230.199.58; StartCity_Pkg=PkgStartCity=4; _ubtstatus=%7B%22vid%22%3A%221695913650066.12ysue%22%2C%22sid%22%3A3%2C%22pvid%22%3A3%2C%22pid%22%3A102001%7D; Union=OUID=title&AllianceID=5376&SID=153507&SourceID=&createtime=1699429035&Expires=1700033834619; MKT_OrderClick=ASID=5376153507&AID=5376&CSID=153507&OUID=title&CT=1699429034620&CURL=https%3A%2F%2Fwww.ctrip.com%2F%3Fsid%3D153507%26allianceid%3D5376%26ouid%3Dtitle%26sepopup%3D104&VAL={}; _bfi=p1%3D102001%26p2%3D102001%26v1%3D3%26v2%3D1; _bfaStatus=success; _jzqco=%7C%7C%7C%7C1699421068215%7C1.790210799.1695913650528.1699429034906.1699429038069.1699429034906.1699429038069.undefined.0.0.12.12; _bfa=1.1695913650066.12ysue.1.1699429062073.1699429121250.3.7.104317',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
}
#查询参数
params={
'sv':'重庆',
'startcity':'4'
}
if __name__=='__main__':
your_url='https://vacations.ctrip.com/list/whole/sc.html?'
response=requests.get(url=your_url,headers=headers,params=params)
print(response.text)
#方式一使用css语法
#创建selector对象
# selector=parsel.Selector(response.text)
# divs=selector.css('div.main_col>div')
#根据一级标签进行循环解析
# for div in divs:
# title=div.css('p.list_product_title>span::text').get()
# info=div.css('p.list_product_subtitle::attr(title)').get()
# print(title,info,sep='\t')
"""
css语法:
1、.css()根据css语法进行查询
2、::text提取标签文本
3、::attr(title)提取title的属性值
4、如果子集标签没有class属性不好提取,可以用右边的例子:div[title="重庆"]这样按照title属性值为重庆来提取
5、切记别忘了.get()!!!!
"""
#方式二使用xpath语法
selector=parsel.Selector(response.text)
divs=selector.xpath('//div[@class="list_product_box js_product_item"]')
for div in divs:
title=div.xpath('.//p[@class="list_product_title"]/span/text()').get() #注意第二次提取一定一定要加上.
info=div.xpath('.//p[@class="list_product_subtitle"]/text()').get()
print(title,info,sep='\t')
"""
xpath语法:
1、标签//[@id="重庆"],//表示选取所有,该语句选取id为重庆的标签
2、/text()表示提取标签文本
3、也不要忘了.get()
4、第二次提取时一定要注意加点,表示从当前目录继续提取, .//p[@id="hhh"]
"""
Beautiful模块之css语法
from bs4 import BeautifulSoup
import requests
#前面都一样省略
if __name__=='__main__':
your_url='https://vacations.ctrip.com/list/whole/sc.html?'
response=requests.get(url=your_url,headers=headers,params=params)
#首先构建soup提取对象
soup=BeautifulSoup(response.text,'lxml')
#方法一css
divs=soup.select('div.main_col>div')
for div in divs:
title=div.select('p.list_product_title>span')[0].get_text()
info = div.select('p.list_product_subtitle')[0].get_attribute_list('title')[0]
#Beatiful库只能说勉强能够接受,.get_text()是获取文本内容
#而get_attribute_list是获取属性元素
print(title,info,sep='\t')
#经发现Beautiful里面没有xpath语法可以提取!!!!
#踩坑点
#title=div.select('p.list_product_title>span')是返回的一个列表
#[<span>重庆+巫山+奉节+巫峡·神女景区+白帝城+洪崖洞民俗风貌区+磁器口古镇6日5晚跟团游</span>, <span>重庆2日1晚跟团游</span>, <span>武隆区2日1晚私家团</span>]
#title=div.select('p.list_product_title>span')[0]是列表的一个子元素,是span标签
#<span>重庆+涪陵区+武隆区2日1晚跟团游</span>
#提取文本标签格式为.get_text有些差异
lxml模块之xpath和css语法
import lxml.html
from lxml import etree
import requests
if __name__=='__main__':
your_url='https://vacations.ctrip.com/list/whole/sc.html?'
response=requests.get(url=your_url,headers=headers,params=params)
select=lxml.html.fromstring(response.text)
#注意这个模块不能用一级二级循环遍历来写
#方法一使用cssselect语法,divs他是element元素只能使用.text提取文本内容,.get('src')提取src属性
# divs=select.cssselect('div.main_col>div .list_product_title>span')
# divs_2=select.cssselect('div.main_col>div .list_product_subtitle')
# for div,divs_2 in zip(divs,divs_2):
# print(div.text,divs_2.get('title'),sep='\t')
#1、.text获取文本内容,.get('title')获取title属性值
#方式二:使用xpath语法,和parsel比较相近
divs=select.xpath('//div[@class="list_product_box js_product_item"]')
for div in divs:
title=div.xpath('.//p[@class="list_product_title"]/span/text()')[0]# 可以看出parsel和lxml细微差别
info=div.xpath('.//p[@class="list_product_subtitle"]/text()')[0]
other=div.xpath('.//p[@class="list_product_subtitle"]/@title')[0] #提取title属性值
print(title,info,sep='\t')
#1、注意获取的列表,需要加上[0]
总结:
css、xpath语法在上述案例中使用都相当,但为了后续提取解析数据更方便,小编在这里推荐使用parsel模块,因为parsel模块兼备css和xpath,可以使用一级二级标题循环遍历法,在后续scrapy框架时,scrapy框架内置parsel,更容易上手。
至于本次没有提取携程价格的,是因为小编还不够格,水平达不到~~~
各位友友们,咋们还是得冲冲冲!!!
















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











