






学习路线参考《机器学习》周志华
其他参考书:《机器学习实战》《数据挖掘》《百面机器学习》
还在更新ing...
1.聚类是什么?
将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇(类)。
2.聚类有什么性能度量指标?
外部指标:将聚类结果和某个参考模型进行比较,例如JC系数、FM指数、Rand指数
内部指标:直接考察聚类结果而不利用任何参考模型,例如DBI指数、DI指数。
3.距离度量有哪几种?
欧氏距离、曼哈顿距离、闵可夫斯基距离。
无序属性可采用VDM。
4.有哪些聚类方法?
4.1 k均值聚类
4.1.1 k均值聚类的流程是什么?
从数据集中随机选择k个样本作为初始均值向量,计算其他所有样本与k个均值向量的距离,距离哪个最近就把该样本标记为相应的簇,然后更新均值向量,直到当前均值向量不再变化或者达到迭代步数。

4.1.2 k均值算法的优缺点是什么?
缺点:
- 受初值和离群点的影响,每次的结果不稳定
- 结果通常不是全局最优而是局部最优解
- 样本只能被分到单一的类中
- 需要人工预先确定初始K值,且该值和真实的数据分布未必吻合。
优点:
- 对于大数据集,K均值算法相对是高效的
- 尽管算法通常以局部最优结束,但一般情况下达到局部最优已经可以满足聚类的需求
4.1.3 如何对K均值算法进行调优?
- 数据归一化和离群点处理。
- 合理选择K值。K值的选择一般基于经验和多次结果,例如采用手肘法,尝试不同的K值,将不同K值所对应的损失函数画成折线,横轴为K的取值,纵轴为误差平方和所定义的损失函数。拐点就是K的最佳值。
- 采用核函数。传统的欧式距离度量方式,使得K均值算法本质上假设了各个数据簇的数据具有一样的先验概率,并呈现球形或者高维球形分布,这种分布在实际生活中并不常见。面对非凸的数据分布形状,可以引进核函数来优化,这时算法又称为核K均值算法,是核聚类的一种。核聚类的主要思想是通过一个非线性映射,将输入空间中的数据点映射到高维的特征空间中,并在新的特征空间中进行聚类。非线性映射增加了数据点线性可分的概率,从而可以达到更为准确的聚类效果。
4.2 密度聚类
4.2.1  -邻域、核心对象、密度直达、密度可达、密度相连是什么意思?
-邻域、核心对象、密度直达、密度可达、密度相连是什么意思?

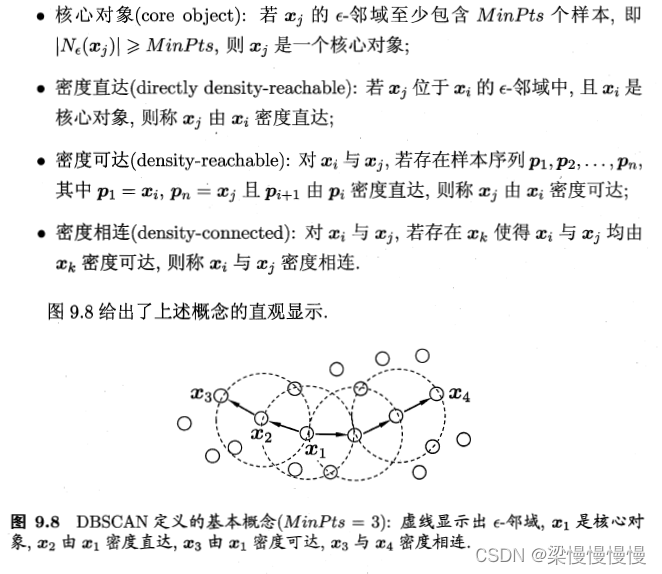
4.2.2 DBSCAN的流程是什么?
设置邻域半径大小和Minpoints。(1)确定核心对象集合;(2)随机选取一个核心对象,找出由其密度可达的样本生成聚类簇,直到所有核心对象都被访问过为止。

4.2.3 DBSCAN相比k均值聚类有什么优点?
可以发现任意形状的簇,而且能在聚类的同时找出异常点。如果数据集不是稠密的,则不适合用DBSCAN。
4.3 层次聚类
可以采用自底向上的聚合策略,可以采用自顶向下的分拆策略。
AGNES 是一种自底向上聚合策略的层次聚类算法。先将数据集中每个样本看成一个初始聚类簇,然后在每一步找出距离最近的两个聚类簇进行合并,并对合并得到的聚类簇的距离矩阵进行更新,知道达到预设的聚类簇个数。
聚类簇的距离计算有最小距离、最大距离和平均距离。

4.4 高斯混合聚类GMM
4.4.1 高斯混合模型是什么?/高斯混合模型的核心思想是什么?
高斯混合模型假设每个簇的数据都是符合高斯分布的,当前数据呈现的分布就是各个簇的高斯分布叠加在一起的结果,需要用多个高斯分布函数的线性组合来对数据分布进行拟合。在该假设下,每个单独的分模型都是高斯模型,其均值和方差是待估计的参数,此外,每个分模型都还有一个参数,可以理解为权重或生成数据的概率,高斯混合模型的公式为
4.4.2 高斯混合模型是如何迭代求解的?
E步:根据当前的参数,计算每个样本的由某个分模型生成的后验概率
M步:根据极大似然估计求出的参数估计公式,更新参数

4.4.3 高斯混合模型与K均值算法的异同点是什么?
相同点:都需要指定K值,都是使用EM算法求解,都往往只能收敛于局部最优
相比K均值的优点是:可以给出一个样本属于某类的概率是多少,不仅可以用于聚类,还可以用于概率密度估计,并可以用于生成新的样本点。















 374
374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









