






学习路线参考《机器学习》周志华
其他参考书:《机器学习实战》《数据挖掘》《百面机器学习》
还在更新ing...
1.数据挖掘
1.1 什么是数据挖掘?
从大量有噪声的数据中提取出隐含的、有价值的信息的过程。
1.2 数据挖掘、统计学和机器学习之间的关系是什么?
统计学和机器学习为数据挖掘提供技术和方法,数据挖掘将其应用在海量数据上。
2.数据清洗的基本内容是什么?
数据可能存在在的质量问题:测量误差、数据收集错误、噪声、离群点、缺失值、不一致值、重复数据
数据清洗一般有:去重、处理缺失值、平滑噪声数据
2.1 如何处理缺失值?
(1)当确实数据所占比例较小时,可以直接删除
(2)数据补齐:当数据量小,对数据相关信息比较了解时,可以采取人工填写;平均值、众数(非数值型)、中位数(倾斜分布)填充;采用基于推断的方法填充,如建立回归模型,对缺失值进行估计,使用贝叶斯模型推理。
2.2 平滑噪声
分箱法:把待处理的数据按照一定的规则放进一些箱子中,考察每个箱子中的数据,采用某种方法对各个箱子中的数据进行处理。
等深分箱法(记录数相等)、等宽分箱法(区间相等)等
局部平滑方式:按平均值平滑、按边界值、按中值
3.数据预处理的方法和内容
数据清洗、数据集成、数据规范化、数据规约、数据离散化
2.1 什么是数据集成?需要注意什么?
将若干分散数据源中的数据集成到一个统一的数据集合中。
存在实体识别问题(同名异义、异名同义、单位统一)、属性冗余问题、数据值冲突问题(规格单位、编码)
2.2 有哪些数据规范化的方法?
最小-最大规范化,z-score标准化,按小数定标规范化、独热码处理标称属性数据
2.3 为什么要归一化?
作用:简化计算,提升模型的收敛速度;在涉及一些距离计算的算法时防止具有较大初始值域的属性与具有较小初始值域的属性相比权重过大,有效提高结果精度。
2.3 数据归约
2.4 怎么处理类别特征?
序号编码、独热编码、二进制编码
2.5 有哪些文本表示模型?
词袋模型:把每篇文章看成一袋子词,忽略词出现的顺序。
词嵌入模型:将词向量化 ,把每个词都映射成低维空间上的一个稠密向量。
4. 异常检测
4.1 有哪些异常检测方法?
基于统计的异常检测方法(p值较小的为异常值)、3原则、箱型图
基于距离的异常检测方法——KNN
基于密度的异常检测方法——LOF
基于集成的异常检测方法——孤立森林
基于聚类的异常检测方法——DBSCAN
参考:
一文详解8种异常检测算法(附Python代码)-CSDN博客
4.2 离群点处理
需要具体分析,一般有如下三种方式:
1.删除。如果想找出一般的规律,而且异常值也不太多,可以考虑删除。因为异常值可能会影响结论。
2.如果进行拟合的时候并没有使模型造成太大偏差,可以放任不管。因为异常值代表的也是真实发生的事件,背后是具体的行为。有些值即使异常,也不会影响模型。
3.视为缺失值进行填充。因为贸然删除数据可能会损失信息,而如果放任不管可能又影响我们的模型,所以可以考虑用均值、临近值进行填充。
4.把异常值单独提取出来做分析。
参考来源:
数据清洗中异常值(离群值)的判别和处理方法_离群值要单独分析吗-CSDN博客
5.特征选择方法有哪些?
过滤式、包裹式、嵌入式
5.1 过滤式选择
先对数据集进行特征选择,再训练学习器,特征选择过程与后续学习器无关。
5.2 包裹式选择
直接把最终要使用的学习器的性能作为特征子集的评价准则,换言之,包裹式特征选择的目的就是为给定学习器选择最有利于其性能、量身定做的特征子集。
5.3 嵌入式选择
5.3.1 什么是嵌入式选择?
将特征选择与学习器训练过程融为一体,两者在同一个优化过程中完成,即学习器训练过程中自动地进行了特征选择。例如岭回归、Lasso回归。
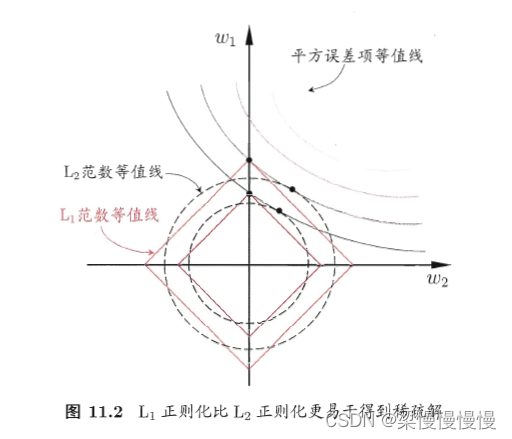
5.3.2 为什么L1正则化更容易获得稀疏解?
因为采用L1范数时,平方误差项等值线与正则化项等值线的交点常出现在坐标轴上,出现每个分量为0

















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









