







1.对于初学者我觉得没必要安装 完全分布式集群,或是高可用集群
一是完全分布式集群非常占用内存和磁盘空间 , 一个集群少说也带三台linux, 非常消耗电脑资源,更别说去操作集群.
所以我觉得搭一个伪分布式,方便快捷,而且操作也是一样的.最起码一次不用开3,4台linux
安装步骤
软件包
链接: https://pan.baidu.com/s/1X2O0Jk0E9exrPh37NL-uNg 提取码: cx3n

一.安装java
创建文件夹并java文件放到这目录上
mkdir /opt/sxt
解压
tar -zxvf java
(这个截图是我远程linux的目录,正在安装的)
配置环境变量
vi /etc/profile
在最后加上
export JAVA_HOME=/opt/sxt/java
export HADOOP_HOME=/opt/sxt/hadoop-2.8.5
export ZOOKEEPER_HOME=/opt/sxt/zookeeper-3.4.14
export HBASE_HOME=/opt/sxt/hbase-1.3.5
export HIVE_HOME=/opt/sxt/apache-hive-1.2.1-bin
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin

. /etc/profile 从新加载一下profile文件
验证java安装是否成功
输入java
 java安装成功
java安装成功
=================================================================
hadoop安装
tar -zxvf hadoop…
进入这个目录

主要配置这6文件
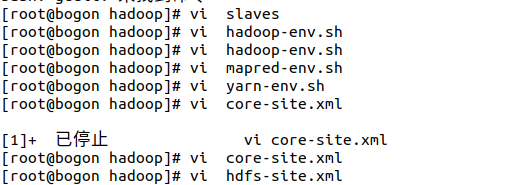
slaves里面只写一个 localhost就行
hadoop-env.sh , maper-env.sh , yarn-env.sh
这三就指明java路劲
找到export JAVA_HOME将后面改成
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/sxt/hadoop/full</value>
</property>
</configuration>

hdfs-site.xml
<configuration>
<property>
<name>dfs.relication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>localhost:50090</value>
</property>
</configuration>

对自身免密☆☆☆
生成私钥和公钥
ssh-keygen -t rsa

touch authorized_keys
chmod 600 authorized_keys
cat id_rsa.pub >> authorized_keys
ssh localhost
看看是不是免密成功
不需要输密码就是成功
由于这是伪分布式不需要配置网卡
格式化hadoop
hdfs namenode -format

有这句表示格式化成功
启动hadoop
start-all.sh

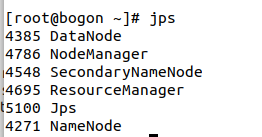
表示成功
在浏览器上输入ip:50070如果无法访问就关闭防火墙
systemctl stop firewalld.service
禁止开机自起
systemctl disable firewalld.service

看到这个界面就OK了
=================================================================
zookeeper安装
在conf里面创建文件zoo.cfg
touch zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/var/sxt/hadoop/zk
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=0.0.0.0:2888:3888
直接将这个复制进去
zkServer.sh start 启动
============================================================
hbase安装
修改hbase-env.cmd
加入
export JAVA_HOME=/opt/sxt/java
export HBASE_MANAGES_ZK=false

在hbase-site.xml里面加入
<configuration>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/var/zookeeper</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
start-hbase.sh
hbase shell 进入hbase数据库
======================================================
hive安装
把这个mysql-connector-java-5.1.40-bin.jar放到hive的lib文件下
在进入conf 删除hive-default.xml.template , 新建一个hive-site.xml
touch hive-site.xml
chmod 777 hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
#这个ip是你mysql所在的主机ip,我这linux上没安装就直接用我电脑上的mysql了
<value>jdbc:mysql://192.168.1.103:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
#mysql账户
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
#mysql密码
<value>root</value>
</property>
</configuration>
start-all.sh 上面几个的前提是 hadoop必须先启动
输入hive启动


到此安装全部完成.
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
这是我第22次安装hadoop生态圈,哎!!!, 心累
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
把这个记下来,方便以后回顾
以下网卡配置是我针对自己的linux进行配配置的,详细的还需多百度
centos网卡配置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.2.132
PREFIX=24
GATEWAY=192.168.2.2
DNS1=192.168.2.2
NAME=ens33
ubuntu 网卡配置
vi /etc/network/interfaces
auto lo
iface lo inet loopback
#The primary network interface
auto ens33
iface ens33 inet static
address 192.168.2.129
netmask 255.255.255.0
gateway 192.168.2.2
dns-nameserver 119.29.29.29
dns-nameserver 114.114.114.114
dns-nameserver 8.8.8.8
/etc/init.d/networking restart
service network-manager restart
vi /etc/resolvconf/resolv.conf.d/base
nameserver 192.168.2.129
nameserver 114.114.114.114
sudo /sbin/resolvconf -u














 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









