









 本文介绍如何使用Python构建多层神经网络解决复杂问题,并通过一个具体示例详细讲解了网络结构、训练过程及代码实现。
本文介绍如何使用Python构建多层神经网络解决复杂问题,并通过一个具体示例详细讲解了网络结构、训练过程及代码实现。
这篇文章将讲解如何使用python建立多层神经网络。在阅读这篇文章之前,建议先阅读上一篇文章:理解神经网络,从简单的例子开始。讲解的是单层的神经网络。如果你已经阅读了上一篇文章,你会发现这篇文章的代码和上一篇基本相同,理解起来也相对容易。
上一篇文章使用了9行代码编写一个单层的神经网络。而现在,问题变得更加复杂了。下面是训练输入数据和训练输出数据,如果输入数据是[1,1,0],最后的结果是什么呢?
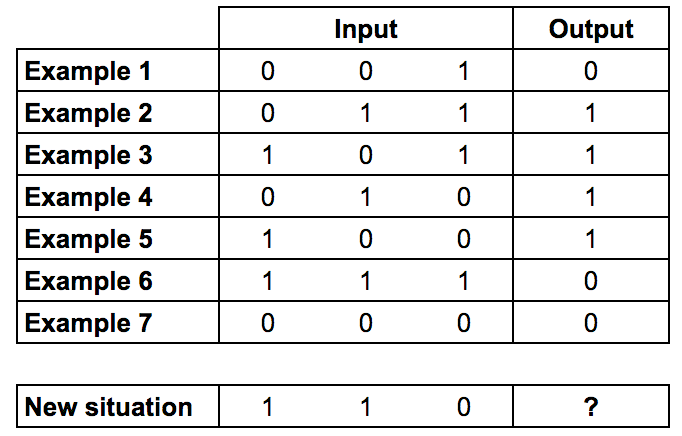
从上面的输入输出数据可以找出规律:第一和第二列的值“异或”之后得到output的值,而第三列没有关系。所谓的异或,就是相同为0,相异为1.
所以,当输入数据为[1,1,0]时,结果为0。
但是,这个在单层网络节点中是很难实现的,因为input和output之间没有一对一的对应关系。所以,可以考虑使用多层的神经网络,或者说增加一个隐藏层,叫layer1,它能够处理input的合并问题。
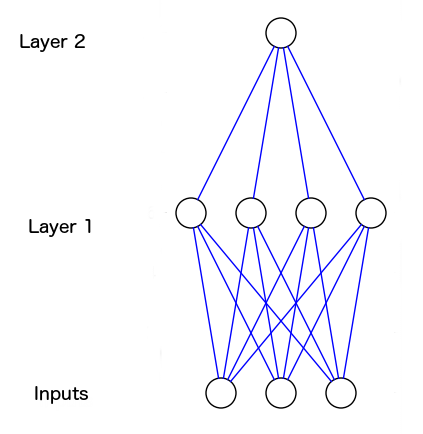
上图就是新的神经网络图。蓝线表示两个神经元之间连接的神经突触。这个图片可以使用这个开源代码自动生成: https://github.com/miloharper/visualise-neural-network。
从图中可以看出,第1层的输出进入第2层。现在神经网络能够处理第一层的输出数据和第二层(也就是最终输出的数据集)之间的关系。随着神经网络学习,它将通过调整两层的权重来放大这些相关性。
实际上,图像识别和这个很相似。比如下面图片中,一个像素和苹果没有直接的关系,但是许多像素组合在一起就能够构成一个苹果的样子,也就产生了关系。

这里通过增加更多层神经来处理“组合”问题,便是所谓的深度学习了。下面是多层神经网络的python代码。解释会在代码注释中和代码后面。
from numpy import exp, array, random, dot
class NeuronLayer():
def __init__(self, number_of_neurons, number_of_inputs_per_neuron):
self.synaptic_weights = 2 * random.random((number_of_inputs_per_neuron, number_of_neurons)) - 1
class NeuralNetwork():
def __init__(self, layer1, layer2):
self.layer1 = layer1
self.layer2 = layer2
# The Sigmoid function, which describes an S shaped curve.
# We pass the weighted sum of the inputs through this function to
# normalise them between 0 and 1.
def __sigmoid(self, x):
return 1 / (1 + exp(-x))
# The derivative of the Sigmoid function.
# This is the gradient of the Sigmoid curve.
# It indicates how confident we are about the existing weight.
def __sigmoid_derivative(self, x):
return x * (1 - x)
# We train the neural network through a process of trial and error.
# Adjusting the synaptic weights each time.
def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations):
for iteration in range(number_of_training_iterations):
# Pass the training set through our neural network
output_from_layer_1, output_from_layer_2 = self.think(training_set_inputs)
# Calculate the error for layer 2 (The difference between the desired output
# and the predicted output).
layer2_error = training_set_outputs - output_from_layer_2
layer2_delta = layer2_error * self.__sigmoid_derivative(output_from_layer_2)
# Calculate the error for layer 1 (By looking at the weights in layer 1,
# we can determine by how much layer 1 contributed to the error in layer 2).
layer1_error = layer2_delta.dot(self.layer2.synaptic_weights.T)
layer1_delta = layer1_error * self.__sigmoid_derivative(output_from_layer_1)
# Calculate how much to adjust the weights by
layer1_adjustment = training_set_inputs.T.dot(layer1_delta)
layer2_adjustment = output_from_layer_1.T.dot(layer2_delta)
# Adjust the weights.
self.layer1.synaptic_weights += layer1_adjustment
self.layer2.synaptic_weights += layer2_adjustment
# The neural network thinks.
def think(self, inputs):
output_from_layer1 = self.__sigmoid(dot(inputs, self.layer1.synaptic_weights))
output_from_layer2 = self.__sigmoid(dot(output_from_layer1, self.layer2.synaptic_weights))
return output_from_layer1, output_from_layer2
# The neural network prints its weights
def print_weights(self):
print( " Layer 1 (4 neurons, each with 3 inputs): ")
print( self.layer1.synaptic_weights)
print( " Layer 2 (1 neuron, with 4 inputs):")
print( self.layer2.synaptic_weights)
if __name__ == "__main__":
#Seed the random number generator
random.seed(1)
# Create layer 1 (4 neurons, each with 3 inputs)
layer1 = NeuronLayer(4, 3)
# Create layer 2 (a single neuron with 4 inputs)
layer2 = NeuronLayer(1, 4)
# Combine the layers to create a neural network
neural_network = NeuralNetwork(layer1, layer2)
print ("Stage 1) Random starting synaptic weights: ")
neural_network.print_weights()
# The training set. We have 7 examples, each consisting of 3 input values
# and 1 output value.
training_set_inputs = array([[0, 0, 1], [0, 1, 1], [1, 0, 1], [0, 1, 0], [1, 0, 0], [1, 1, 1], [0, 0, 0]])
training_set_outputs = array([[0, 1, 1, 1, 1, 0, 0]]).T
# Train the neural network using the training set.
# Do it 60,000 times and make small adjustments each time.
neural_network.train(training_set_inputs, training_set_outputs, 60000)
print ("Stage 2) New synaptic weights after training: ")
neural_network.print_weights()
# Test the neural network with a new situation.
print ("Stage 3) Considering a new situation [1, 1, 0] -> ?: ")
hidden_state, output = neural_network.think(array([1, 1, 0]))
print (output)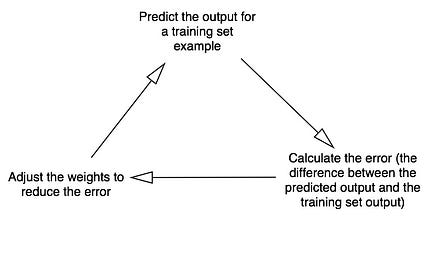
上图是深度学习的计算周期
和上篇博客中的单层神经网络相比,这里是多层,也就是增加了隐藏层。当神经网络计算第二层的error误差值的时候,会把这个error向后面一层也即是第一次传播,从而计算并调整第一层节点的权值。也就是,第一层的error误差值是从上一层也即是第二层所传播回来的值中计算得到的,这样就能够知道第一层对第二层的误差有多大的贡献。
运行上面的代码,会得到下面所示的结果。
Stage 1) Random starting synaptic weights:
Layer 1 (4 neurons, each with 3 inputs):
[[-0.16595599 0.44064899 -0.99977125 -0.39533485]
[-0.70648822 -0.81532281 -0.62747958 -0.30887855]
[-0.20646505 0.07763347 -0.16161097 0.370439 ]]
Layer 2 (1 neuron, with 4 inputs):
[[-0.5910955 ]
[ 0.75623487]
[-0.94522481]
[ 0.34093502]]
Stage 2) New synaptic weights after training:
Layer 1 (4 neurons, each with 3 inputs):
[[ 0.3122465 4.57704063 -6.15329916 -8.75834924]
[ 0.19676933 -8.74975548 -6.1638187 4.40720501]
[-0.03327074 -0.58272995 0.08319184 -0.39787635]]
Layer 2 (1 neuron, with 4 inputs):
[[ -8.18850925]
[ 10.13210706]
[-21.33532796]
[ 9.90935111]]
Stage 3) Considering a new situation [1, 1, 0] -> ?:
[ 0.0078876]这篇文章是本人根据这篇博客写的。一定程度上算是在做翻译的工作。本人特别推荐该源码的风格,一看就知道这是编程经验丰富之人才能写出来的代码,清晰明了,看起来特别舒服。
结束! 转载请标明出处,感谢!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









