






 本文深入探讨MapReduce计算框架,介绍了MapReduce的基本原理、作业数据流、Hadoop流处理,以及通过Python实现词频统计的MapReduce程序,包括map和reduce函数的详细解释和本地测试。此外,还讨论了Reducer数量的设定、Combiner的作用,以及如何使用MapReduce进行数据连接,以航班数据为例展示了完整的Map和Reduce实现。
本文深入探讨MapReduce计算框架,介绍了MapReduce的基本原理、作业数据流、Hadoop流处理,以及通过Python实现词频统计的MapReduce程序,包括map和reduce函数的详细解释和本地测试。此外,还讨论了Reducer数量的设定、Combiner的作用,以及如何使用MapReduce进行数据连接,以航班数据为例展示了完整的Map和Reduce实现。
MapReduce计算框架
MapReduce原理
MapReduce是一个软件编程框架,用于开发能够在商用硬件组成的集群中并行处理大数据的应用程序。为了理解方便,本节以词频统计为例,详细解读MapReduce原理,整个流程如下图所示。
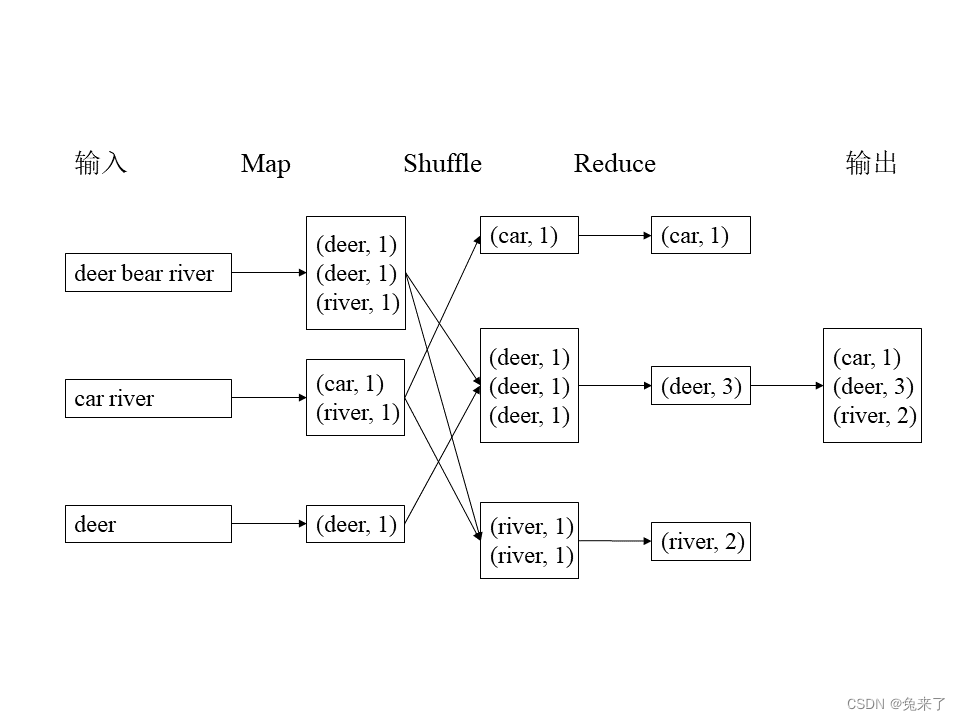
MapReduce的基本原理是,将数据处理分为2个阶段,即Map阶段和Reduce阶段。每一阶段的输入和输出都是一个键值对,具体数据类型可以由用户指定。用户还需要实现2个函数,即map和reduce函数。
Map阶段的输入为3行文本,输入格式即为文本格式。文件的每一行都会调用一次map函数,输入的键为自文件开头到当前行的偏移字节数,输入的值为每一行的文本。在本例中,map函数很简单,只需要将每一行文本按空格分割成单词,输出键为单词、值为1的键值对。reduce函数统计每个单词出现的次数。
具体而言,输入文本为
(0, deer car river)
(14, deer river)
(24, deer)
map函数将输入文本按空格分割成单词作为键、1为值,输出的键值对为
(deer, 1)
(car, 1)
(river, 1)
(deer, 1)
(river, 1)
(deer, 1)
map函数的输出会经过Shuffle操作,即按键排序和分组,将结果输入reduce函数。reduce函数的输入键值对为
(car, [1])
(deer, [1, 1, 1])
(river, [1, 1])
即每个单词都对应了一个由1组成的列表,每个1代表该单词出现过一次。而在后续章节介绍的Hadoop流处理中,相同键所对应的值并不一定会组成所用语言中的列表数据结构,但还是会按键排序,即
(car, 1)
(deer, 1)
(deer, 1)
(deer, 1)
(river, 1)
(river, 1)
reduce函数只需要遍历列表,或在Hadoop流处理中判断当前键是否与上一个键一致,对相同键对应的值求和,输出的键值对为
(car, 1)
(deer, 3)
(river, 2)
后续章节会给出本例MapReduce程序的具体实现。在此之前,还需要理解MapReduce作业数据流。
通常情况下,MapReduce作业的计算节点和数据的存储节点是同一系列节点。换言之,Hadoop中的每个从节点一般既作为YARN资源池的一部分,提供CPU、内存等资源,同时也作为HDFS数据节点的一部分,提供存储。MapReduce作业在向YARN申请资源时,会尽可能将任务在该任务输入数据所在节点上执行,以节省网络带宽。
MapReduce作业数据流
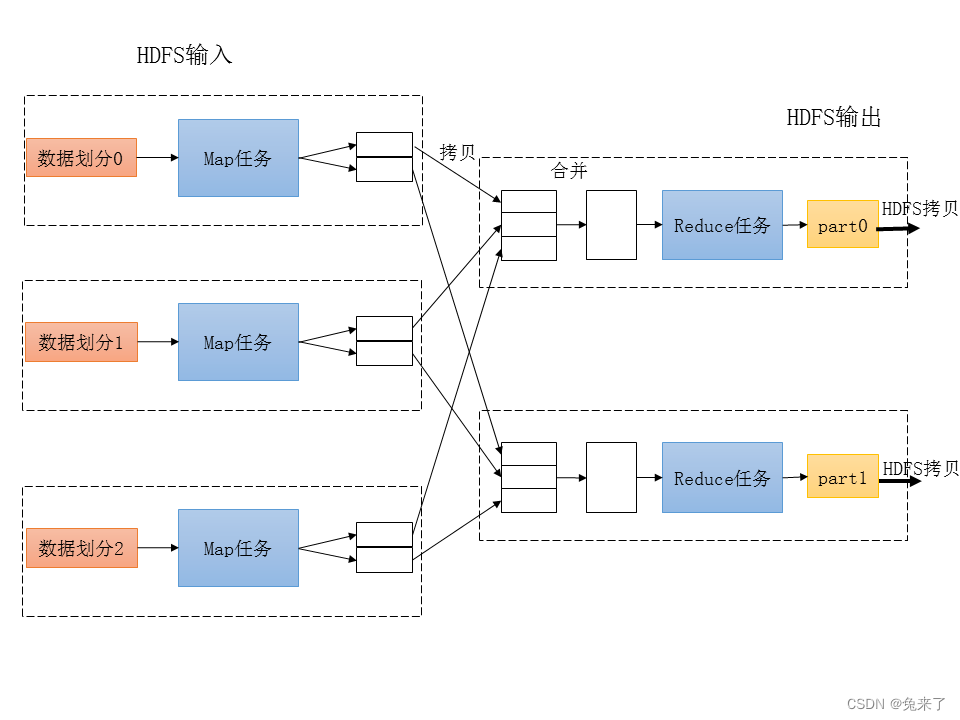
一个MapReduce作业由输入数据、MapReduce程序和配置信息组成。Hadoop在运行MapReduce作业时,会分成多个Map和Reduce任务。YARN负责调度这些任务,并在集群中的节点上执行,任务如果失败则会在不同的节点上重试。
Hadoop将MapReduce作业的输入分割成多个固定大小的数据划分(split)。对于每一个数据划分,都启动一个Map任务,用于在输入数据中的每条记录上调用map函数。多数情况下,数据划分的大小与文件块的大小一致,默认为128 MB。
Hadoop会尽其所能将Map任务在该任务输入数据所在节点上执行,以节省网络带宽,称为“数据本地化优化”。如果有该任务输入数据拷贝的所有节点都没有空闲资源,调度器则会尽量将任务在同一机架的其他节点执行。如果同一机架的所有节点仍然没有空闲资源,才考虑在其他机架的节点执行该任务。
Map任务的输出直接写入本地磁盘,而不是HDFS。究其原因,Map任务的输出只是中间结果,会输出Reduce任务做进一步处理进而产生最终结果,整个作业完成时Map任务的输出会被删除。假如将此中间结果存储在HDFS中形成多份拷贝,则会造成过多的系统开销。
Reduce任务不具备Map任务的数据本地化优势,一个Reduce任务的输入通常情况下来自所有Map任务的输出。因此,Map任务的输出经过按键排序后,必须通过网络传输到执行Reduce任务的节点,该过程也称为Shuffle操作。同一个键的键值对会合并成列表,输入用户定义的reduce函数。Reduce任务的输出通常情况下会写入HDFS。
Reduce任务的数量并不取决于输入数据大小,因为在MapReduce作业启动前,框架无法预知Map任务的输出数据大小。Reduce任务的数量通常情况下由用户或更高层的应用指定。当指定了多个Reduce任务时,Map任务会将输出按键做分区(partition),每个分区对应一个Reduce任务。每个分区可以对应多个键,但每个键只能对应一个分区,即键相同的记录必然进入同一个Reduce任务。默认的分区方法为,对键执行哈希函数,哈希值相同的记录为同一个分区,用户也可以指定自己的分区函数。
整个流程如下图所示。
Hadoop流处理
Hadoop的接口函数语言为Java。Hadoop流处理(streaming)使得用户能够采用Unix标准流作为接口与Hadoop交互,而不必须使用Java。用户可以通过读取标准输入流和写入标准输出流的方式,使用任何编程语言开发MapReduce程序。本章所有MapReduce程序将基于Python编写,通过Hadoop流处理执行。
Hadoop流处理最基本的调用语法为
hadoop jar hadoop-streaming.jar
-input <输入路径>
-output <输出路径>
-mapper <map函数脚本>
-reducer <reduce函数脚本>
MapReduce程序实现词频统计
map函数
创建map函数的Python脚本mapper.py。脚本读取标准输入,遍历每一行文本。调用字符串的函数strip()去除首尾不可见字符,并调用函数lower()将文本转换为小写,再调用程序包re中的函数split()将每一行文本按非字母的字符分割成单词。对于每一个分割得到的单词,如果长度大于0,输出以单词为键、以1为值的键值对,以制表符做分隔,调用函数print()写入标准输出。
#!/usr/bin/env python
import sys, re
for line in sys.stdin:
line = line.strip().lower()
keys = re.split(“[^a-z]”, line)
for key in keys:
if len(key) > 0:
value = 1
print( “%s\t%d” % (key, value) )
reduce函数
创建reduce函数的Python脚本reducer.py。脚本首先定义变量last_key存储上一行的键即单词,running_total存储单词的出现频次。读取标准输入,遍历每一行文本。调用字符串的函数strip()去除首尾不可见字符,再调用函数split()将每一行文本按制表符分割成单词和出现频次(本例中都是1)。由于Reduce任务的输入都已经按照键做了排序,如果当前行的键与上一行的键相同,则将词频累加,如果不相同,则表示上一行的键已经全部统计完毕,因此调用函数print()将键和累加的词频写入标准输出。最后2行代码则用于输出最后一个键和对应的词频。
#!/usr/bin/env python
import sys
last_key = None
running_total = 0
for input_line in sys.stdin:
input_line = input_line.strip()
this_key, value = input_line.split(“\t”, 1)
value = int(value)
if last_key == this_key:
running_total += value
else:
if last_key:
print( “%s\t%d” % (last_key, running_total) )
running_total = value
last_key = this_key
if last_key == this_key:
print( “%s\t%d” % (last_key, running_total) )
本地测试
在提交到Hadoop执行前,先在本地进行测试。
使用chmod命令开放脚本的执行权限。
chmod 755 mapper.py
chmod 755 reducer.py
根据之前章节的例子,使用echo命令和输出重定向,创建一个仅有3行内容的文本文件test.txt。
echo “deer deer river
car river
deer” > test.txt
使用cat命令将文本输出,并用管道|将其作为脚本mapper.py的标准输入,执行脚本mapper.py,查看Map阶段的输出。
cat test.txt | ./mapper.py
deer 1
deer 1
river 1
car 1
river 1
deer 1
进一步加入管道|,并使用sort命令按字母排序,查看Reduce阶段的输入。
cat test.txt | ./mapper.py | sort
car 1
deer 1
deer 1
deer 1
river 1
river 1
进一步加入管道|,并执行脚本reducer.py,查看Reduce阶段的输出。
cat test.txt | ./mapper.py | sort | ./reducer.py
car 1
deer 3
river 2
数据准备
使用hdfs dfs -put命令从本地文件系统将文件夹/opt/data/novels上传到到HDFS。
hdfs dfs -put /opt/data/novels/
提交到Hadoop集群执行
使用hadoop jar命令将MapReduce程序提交到Hadoop集群执行,其中
第1个参数表示程序jar包,这里指定Hadoop流处理包;
参数-files表示程序执行需要的文件列表;
参数-mapper表示map函数脚本;
参数-reducer表示reduce函数脚本;
参数-input表示输入数据路径;
参数-output表示输出数据路径。
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar -files mapper.py,reducer.py -mapper mapper.py -reducer reducer.py -input novels -output output
在作业开始执行开始前,输出的信息包括
mapred.FileInputFormat: Total input paths to process表示输入文件数量为3;
mapreduce.JobSubmitter: number of splits表示输入文件的划分数量为3,这里即每个文件只有一个划分;
mapreduce.JobSubmitter: Submitting tokens for job表示作业的标识符为job_1538355655973_0003,查看状态或杀死作业时使用;
mapreduce.Job: The url to track the job表示跟踪作业运行状态的URL地址,可以在浏览器中打开。
在作业执行过程中,会实时输出类似map X% reduce X%的进度情况。
在作业执行完毕后,输出多个计数器,包括
File System Counters表示文件系统计数器,其中又包括
FILE: Number of bytes read/written表示操作系统读取/写入的文件字节数;;
HDFS: Number of bytes read/written表示HDFS读取/写入文件字节数;
Job Counters表示作业计数器,其中又包括
Launched map/reduce tasks表示Map/Reduce任务数;
Total time spent by all map/reduce tasks (ms)表示所有Map/Reduce任务花费的毫秒数;
Map-Reduce Framework表示MapReduce框架计数器,其中又包括
Map/Combine/Reduce input records表示Map/Combine/Reduce任务输入记录数;
Map/Combine/Reduce output records表示Map/Combine/Reduce任务输出记录数;
Map output bytes表示Map任务输出字节数;
Map output materialized bytes表示Map任务输出且在写入硬盘的字节数,Map任务的输出作为中间结果会写入任务所在的操作系统硬盘;
Reduce input groups表示Reduce任务的输入分组数;
Reduce shuffle bytes表示Shuffle操作的字节数;
查看结果
hdfs dfs -ls output
Found 2 items
-rw-r–r-- 1 root hadoop 0 2018-10-01 14:37 output/_SUCCESS
-rw-r–r-- 1 root hadoop 158322 2018-10-01 14:37 output/part-00000
可以看出,输出文件夹中包含2个文件,文件_SUCCESS是一个空文件,大小为0,仅表示作业执行成功,文件part-00000是输出数据文件,其中包含了词频统计结果。
使用hdfs dfs -tail命令显示文件末尾1KB内容。
hdfs dfs -tail output/part-00000
wouldn 44
wound 10
wove 4
woven 1
wrap 3
[…]
MapReduce程序的Reducer数量
前面已经提到,Reduce任务的数量并不取决于输入数据大小,因为在MapReduce作业启动前,框架无法预知Map任务的输出数据大小。 Reduce任务的数量通常情况下由用户或更高层的应用指定。
Hadoop流处理命令中,指定选项numReduceTasks表示Reducer数量,这里设为3。
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar -files mapper.py,reducer.py -mapper mapper.py -reducer reducer.py -input novels -output output1 -numReduceTasks 3
使用命令hdfs dfs -ls显示文件(夹)统计信息。
hdfs dfs -ls output1
Found 4 items
-rw-r–r-- 1 root hadoop 0 2018-10-01 14:45 output1/_SUCCESS
-rw-r–r-- 1 root hadoop 52341 2018-10-01 14:45 output1/part-00000
-rw-r–r-- 1 root hadoop 53503 2018-10-01 14:45 output1/part-00001
-rw-r–r-- 1 root hadoop 52478 2018-10-01 14:45 output1/part-00002
可以看出,除了文件_SUCCESS以外,另有3个以part-开头的文件是输出数据文件,每个文件对应一个Reducer的输出。
MapReduce程序的Combiner
Combiner也称为迷你版的Reducer,用于在Mapper的输出通过网络传输到Reduce任务前,根据键合并Mapper的输出,以减少网络传输。Combiner与Mapper一一对应,即如果配置启用Combiner,则每个Mapper会对应一个Combiner,并且该Combiner只会接受来自所对应的Mapper的输出。
考虑在词频统计的例子中,有2个Map任务,其中第一个Mapper的输入为deer deer river,而另一个Mapper的输入为car car。
当没有启用Combiner时,第一个Mapper输出到Reducer的为3条记录,即
(deer, 1)
(deer, 1)
(river, 1)
另一个Mapper输出到Reducer的为2条记录,即
(car, 1)
(car, 1)
当启用Combiner时,第一个Mapper输出经Combiner合并,输入到Reducer的为2条记录,即
(deer, 2)
(river, 1)
另一个Mapper输出经Combiner合并,输入到Reducer的为1条记录,即
(car, 2)
因此,通过启用Combiner节省了网络传输。
Hadoop流处理命令中,指定选项combiner表示Combiner函数脚本。
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar -files mapper.py,reducer.py -mapper mapper.py -reducer reducer.py -input novels -output output2 -numReduceTasks 3 -combiner reducer.py
与上一节没有Reducer对比,Shuffle操作的字节数从3442000减少到307177,减少了一个数量级。
MapReduce程序实现数据连接
数据连接指的是,将两个数据集按照某些条件(通常为某一列的值相等)合并成一个数据集。
本节的例子基于2个数据集。第一个数据集是2014年前10个月由纽约出发航班的准点情况数据,由美国运输局收集整理,包含253,316个样本,每个样本包含17个属性,如下表所示
属性 定义
year 年份
month 月份
day 日期
dep_time 出发时间
dep_delay 出发延误分钟数
arr_time 到达时间
arr_delay 到达延误分钟数
carrier 航空公司代码
tailnum 尾翼编号
flight 航班编号
origin 出发地
dest 目的地
air_time 飞行分钟数
distance 距离
hour 小时
min 分钟
该数据集的路径为/opt/data/flights/flights14.csv。
head /opt/data/flights/flights14.csv
第二个数据集是航空公司简写与描述的映射数据集,由美国运输局收集整理,包含1,889个样本,每个样本包含2个属性,如下表所示
属性 定义
carrier 航空公司代码
description 描述
该数据集的路径为/opt/data/flights/carrier.csv。
head /opt/data/flights/carrier.csv
可以看出,两个数据文件的第一行都是数据的变量名,且数据集的各变量都以逗号,分隔。第二个数据集carriers.csv中的每个变量内容首都用了双引号"。这两个数据集的公共变量是航空公司代码(变量carrier),即第一个数据集的第9列和第二个数据集的第1列。以下的例子将以该变量相等作为连接条件。
map函数
创建map函数的Python脚本join_mapper.py。脚本读取标准输入,遍历每一行文本。调用字符串的函数strip()去除首尾不可见字符,并调用函数split()将每一行文本按逗号,做分割。由于输入的数据文件可能来自包含17个变量的航班准点情况数据,也可能来自包含2个变量的航空公司简写与描述映射数据,因此需要进行区分处理。如果分割后有17个元素,则表示该行数据来自航班准点情况数据,将第9个元素作为键,整行内容作为值,并添加一个来源标记flight,用于在reduce函数中区分数据来自哪个数据集。如果分割后没有17个元素,则表示该行数据来自航空公司简写与描述映射数据,将第1个元素作为键并调用函数replace()去除双引号",键后面的内容作为值,并添加一个来源标记carrier。最终以制表符做分隔,调用函数print()将数据连接键、来源标记和值写入标准输出。
#!/usr/bin/env python
import sys, re
for line in sys.stdin:
line = line.strip()
fields = line.split(“,”)
if len(fields) == 17:
key = fields[8]
source = “flight”
value = line
else:
key = fields[0].replace(“”“, “”)
source = “carrier”
value = line.split(”,", 1)[1]
if (key != “year”) & (key != “carrier”):
print( “%s\t%s\t%s” % (key, source, value) )
reduce函数
创建reduce函数的Python脚本join_reducer.py。脚本首先定义变量last_key存储上一行的键。读取标准输入,遍历每一行文本。调用字符串的函数strip()去除首尾不可见字符,再调用函数split()将每一行文本按制表符分割成数据连接键、来源标记和值。由于Reduce任务的输入都已经做了排序,且对于同样的数据连接键,来源标记carrier排在flight前面(按字母顺序),如果当前行的键与上一行的键不相同,则将航空公司描述(变量carrier_description)设为空字符串。如果该行的来源标记表示来自航空公司简写与描述映射数据,则将值赋给变量carrier_description,否则表示来自航班准点情况数据,则调用函数print()将值和变量carrier_description写入标准输出。
#!/usr/bin/env python
import sys
last_key = None
for input_line in sys.stdin:
input_line = input_line.strip()
this_key, source, value = input_line.split(“\t”, 2)
if this_key != last_key:
carrier_description = “”
last_key = this_key
if source == “carrier”:
carrier_description = value
else:
print( “%s,%s” % (value, carrier_description) )
本地测试
创建一个测试文本文件flights14_sample.csv,为航班准点情况数据的一小部分。
2014,1,1,1754,24,2041,16,0,AA,N623AA,2448,JFK,EGE,266,1746,17,54
2014,1,1,647,-3,942,-13,0,AA,N5CEAA,2493,JFK,MCO,147,944,6,47
2014,1,1,1829,4,2140,-12,0,AS,N423AS,5,EWR,SEA,347,2402,18,29
2014,1,1,709,4,1030,15,0,AS,N435AS,15,EWR,SEA,348,2402,7,9
2014,1,1,846,51,1100,60,0,B6,N318JB,1273,JFK,CHS,109,636,8,46
2014,1,1,1353,41,1657,51,0,B6,N318JB,553,JFK,PBI,165,1028,13,53
2014,1,1,2127,72,2215,49,0,B6,N318JB,418,JFK,BOS,32,187,21,27
创建另一个测试文本文件carrier_sample.csv,为航空公司简写与描述映射数据的一小部分。
“AA”,“American Airlines Inc. (1960 - )”
“B6”,“JetBlue Airways (2000 - )”
“CA”,“Air China (1981 - )”
在提交到Hadoop执行前,先在本地进行测试。
使用chmod命令开放脚本的执行权限。
chmod 755 join_mapper.py
chmod 755 join_reducer.py
使用cat命令将文件flights14_sample.csv输出,并用管道|将其作为脚本join_mapper.py的标准输入,执行脚本join_mapper.py,查看Map阶段的输出。
cat flights14_sample.csv | ./join_mapper.py
AA flight 2014,1,1,1754,24,2041,16,0,AA,N623AA,2448,JFK,EGE,266,1746,17,54
AA flight 2014,1,1,647,-3,942,-13,0,AA,N5CEAA,2493,JFK,MCO,147,944,6,47
AS flight 2014,1,1,1829,4,2140,-12,0,AS,N423AS,5,EWR,SEA,347,2402,18,29
AS flight 2014,1,1,709,4,1030,15,0,AS,N435AS,15,EWR,SEA,348,2402,7,9
B6 flight 2014,1,1,846,51,1100,60,0,B6,N318JB,1273,JFK,CHS,109,636,8,46
B6 flight 2014,1,1,1353,41,1657,51,0,B6,N318JB,553,JFK,PBI,165,1028,13,53
B6 flight 2014,1,1,2127,72,2215,49,0,B6,N318JB,418,JFK,BOS,32,187,21,27
对文件carrier_sample.csv做同样操作。
cat carrier_sample.csv | ./join_mapper.py
AA carrier “American Airlines Inc. (1960 - )”
B6 carrier “JetBlue Airways (2000 - )”
CA carrier “Air China (1981 - )”
进一步加入管道|,并使用sort命令按字母排序,查看Reduce阶段的输入。
cat *.csv | ./join_mapper.py | sort
AA carrier “American Airlines Inc. (1960 - )”
AA flight 2014,1,1,1754,24,2041,16,0,AA,N623AA,2448,JFK,EGE,266,1746,17,54
AA flight 2014,1,1,647,-3,942,-13,0,AA,N5CEAA,2493,JFK,MCO,147,944,6,47
AS flight 2014,1,1,1829,4,2140,-12,0,AS,N423AS,5,EWR,SEA,347,2402,18,29
AS flight 2014,1,1,709,4,1030,15,0,AS,N435AS,15,EWR,SEA,348,2402,7,9
B6 carrier “JetBlue Airways (2000 - )”
B6 flight 2014,1,1,1353,41,1657,51,0,B6,N318JB,553,JFK,PBI,165,1028,13,53
B6 flight 2014,1,1,2127,72,2215,49,0,B6,N318JB,418,JFK,BOS,32,187,21,27
B6 flight 2014,1,1,846,51,1100,60,0,B6,N318JB,1273,JFK,CHS,109,636,8,46
CA carrier “Air China (1981 - )”
进一步加入管道|,并执行脚本join_reducer.py,查看Reduce阶段的输出。
cat *.csv | ./join_mapper.py | sort | ./join_reducer.py
2014,1,1,1754,24,2041,16,0,AA,N623AA,2448,JFK,EGE,266,1746,17,54,“American Airlines Inc. (1960 - )”
2014,1,1,647,-3,942,-13,0,AA,N5CEAA,2493,JFK,MCO,147,944,6,47,“American Airlines Inc. (1960 - )”
2014,1,1,1829,4,2140,-12,0,AS,N423AS,5,EWR,SEA,347,2402,18,29,
2014,1,1,709,4,1030,15,0,AS,N435AS,15,EWR,SEA,348,2402,7,9,
2014,1,1,1353,41,1657,51,0,B6,N318JB,553,JFK,PBI,165,1028,13,53,“JetBlue Airways (2000 - )”
2014,1,1,2127,72,2215,49,0,B6,N318JB,418,JFK,BOS,32,187,21,27,“JetBlue Airways (2000 - )”
2014,1,1,846,51,1100,60,0,B6,N318JB,1273,JFK,CHS,109,636,8,46,“JetBlue Airways (2000 - )”
数据准备
使用hdfs dfs -put命令从本地文件系统将文件夹/opt/data/flights上传到到HDFS。
hdfs dfs -put /opt/data/flights/
提交到Hadoop集群执行
使用hadoop jar命令将MapReduce程序提交到Hadoop集群执行。
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar -files join_mapper.py,join_reducer.py -mapper join_mapper.py -reducer join_reducer.py -input flights -output output3
查看结果
使用hdfs dfs -ls命令显示文件(夹)统计信息。
hdfs dfs -ls output
Found 2 items
-rw-r–r-- 1 root hadoop 0 2018-10-08 10:47 output/_SUCCESS
-rw-r–r-- 1 root hadoop 24015343 2018-10-08 10:47 output/part-00000
使用hdfs dfs -tail命令显示文件末尾1KB内容。
hdfs dfs -tail output/part-00000
2014,9,11,850,-5,1012,-13,0,WN,N710SW,3415,LGA,MDW,118,725,8,50,“Southwest Airlines Co. (1979 - )”
2014,9,11,555,-5,707,-3,0,WN,N8327A,4963,LGA,MDW,109,725,5,55,“Southwest Airlines Co. (1979 - )”
2014,9,11,925,-5,1046,-24,0,WN,N555LV,786,LGA,MKE,121,738,9,25,“Southwest Airlines Co. (1979 - )”
2014,9,11,558,-2,718,-2,0,WN,N957WN,1027,LGA,MKE,120,738,5,58,“Southwest Airlines Co. (1979 - )”
2014,9,11,1404,-6,1515,-20,0,WN,N298WN,1345,LGA,MKE,118,738,14,4,“Southwest Airlines Co. (1979 - )”
2014,9,11,1931,1,2049,-11,0,WN,N7715E,2164,LGA,MKE,123,738,19,31,“Southwest Airlines Co. (1979 - )”
2014,9,11,1824,-1,1955,-10,0,WN,N236WN,791,LGA,STL,132,888,18,24,“Southwest Airlines Co. (1979 - )”
2014,9,11,1154,-6,1333,-22,0,WN,N467WN,2414,LGA,STL,134,888,11,54,“Southwest Airlines Co. (1979 - )”
2014,9,11,710,-5,846,-9,0,WN,N772SW,3755,LGA,STL,136,888,7,10,“Southwest Airlines Co. (1979 - )”
2014,10,31,1310,0,1600,-30,0,WN,N231WN,244,EWR,AUS,217,1504,13,10,“Southwest Airlines Co. (1979 - )”


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









