









Bagging(集成学习模型)
使用一系列弱学习器(也称为基础模型或基模型)进行学习,并将各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果。
随机森林是什么?
Bagging + 决策树 = 随机森林;也就是单个决策树容易判断片面,随机森林思想是采用三个臭皮匠顶个诸葛亮,兼听则明,偏信则暗的哲学思想。
随机森林可以做分类可以做回归吗?
分类问题中是用n个弱学习器投票的方式获取最终结果,在回归问题中则是取n个弱学习器的平均值作为最终结果
做决策树常用的python包
Sklearn 全称为 scikit-learn pip install scikit-learn
常用的函数
from sklearn.tree import RandomForestClassifier分类
from sklearn.tree import RandomForestRegressor回归
from sklearn.metrics import accuracy_score 评分
随机森林简单案例
from sklearn.ensemble import RandomForestClassifier
X = [[1,2],[3,4],[5,6],[7,8],[9,10]]
y = [0,0,0,1,1]
# 设置弱学习器数量为10
model = RandomForestClassifier(n_estimators=10,random_state=123)
model.fit(X,y)
model.predict([[5,5]])
# 输出为:array([0])
决策树好坏的评价
- 整体的预测准确度
from sklearn.metrics import accuracy_score
- 模型预测效果评估(ROC曲线)
对于分类模型,不仅关心预测准确度,更关心命中率和假警报率这两个指标,并通过这两个指标绘制ROC曲线来评估模型。
from sklearn.metrics import roc_curve
特征重要性评估
模型搭建完成后,有时还需要知道各个特征变量的重要程度,即哪些特征变量在模型中发挥的作用更大,这个重要程度称为特征重要性。
在决策树模型中,一个特征变量对模型整体的基尼系数下降的贡献越大,它的特征重要性就越大。
model.feature_importances_
参数调优
- GridSearch网格搜索
import akshare as ak
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
import talib
# 此代码包括数据获取、衍生变量生成、模型搭建、训练、评估、参数调优以及收益回测曲线的绘制。
# 设置中文字体(如SimHei、Microsoft YaHei)
plt.rcParams['font.sans-serif'] = ['SimHei'] # :ml-citation{ref="3,5" data="citationList"}
# 解决负号显示异常问题
plt.rcParams['axes.unicode_minus'] = False # :ml-citation{ref="3,5" data="citationList"}
# 获取 A 股数据(以贵州茅台 600519 为例)
def get_stock_data(symbol="600519", start_date="2020-01-01"):
stock_df = ak.stock_zh_a_hist(symbol=symbol, period="daily", adjust="qfq") # 获取前复权数据
stock_df = stock_df[['日期', '开盘', '收盘', '最高', '最低', '成交量']] # 选取关键字段
stock_df['日期'] = pd.to_datetime(stock_df['日期']) # 转换日期格式
stock_df = stock_df[stock_df['日期'] >= start_date] # 过滤起始日期
return stock_df
# 获取股票基本数据
df = get_stock_data(symbol="600519")
df = df.set_index('日期')
# 生成简单衍生变量
df['close-open'] = (df["收盘"] - df["开盘"]) / df["开盘"]
df['high-low'] = (df['最高'] - df['最低']) / df['最低']
df['pre_close'] = df["收盘"].shift(1)
df['price_change'] = df["收盘"] - df['pre_close']
df['p_change'] = (df["收盘"] - df['pre_close']) / df['pre_close'] * 100
# 生成移动平均线指标MA值
df['MA5'] = df["收盘"].rolling(5).mean()
df['MA10'] = df["收盘"].rolling(10).mean()
df.dropna(inplace=True)
# 通过TA-Lib库构造衍生变量数据
df['RSI'] = talib.RSI(df["收盘"], timeperiod=12)
df['MOM'] = talib.MOM(df["收盘"], timeperiod=5)
df['EMA12'] = talib.EMA(df["收盘"], timeperiod=12)
df['EMA26'] = talib.EMA(df["收盘"], timeperiod=26)
df['MACD'], df['MACDsignal'], df['MACDhist'] = talib.MACD(df["收盘"], fastperiod=6, slowperiod=12, signalperiod=9)
df.dropna(inplace=True)
# 提取特征变量和目标变量
X = df[["收盘", '成交量', 'close-open', 'MA5', 'MA10', 'high-low', 'RSI', 'MOM', 'EMA12', 'MACD', 'MACDsignal', 'MACDhist']]
y = np.where(df['price_change'].shift(-1) > 0, 1, -1)
# 划分训练集和测试集
X_length = X.shape[0]
split = int(X_length * 0.9)
# X_train,X_test = X[:split],X[split:]
y_train,y_test = y[:split],y[split:]
X_train = X.iloc[:split].copy() # 明确创建训练集副本
X_test = X.iloc[split:].copy() # 明确创建测试集副本
# 模型搭建与训练
model = RandomForestClassifier(max_depth=8, n_estimators=10, min_samples_leaf=20, random_state=123)
model.fit(X_train, y_train)
# 预测下一天的股价涨跌情况
predictions = model.predict(X_test)
# 模型准确度评估
accuracy = accuracy_score(y_test, predictions)
print(f'模型准确度: {accuracy}')
# 分析特征变量的特征重要性
importances = model.feature_importances_
features = X.columns
feature_importances = pd.DataFrame({'Feature': features, 'Importance': importances}).sort_values(by='Importance', ascending=False)
print(feature_importances)
# 参数调优
parameters={'n_estimators':[5,10,20],'max_depth':[2,3,4,5,6],'min_samples_leaf':[5,10,20,30]}
new_model = RandomForestClassifier(random_state=123)
grid_search = GridSearchCV(new_model, parameters, cv=6, scoring='accuracy')
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
print(f'最佳参数: {best_params}')
# 收益回测曲线绘制
X_test['prediction'] = model.predict(X_test)
X_test['p_change'] = (X_test["收盘"] - X_test["收盘"].shift(1)) / X_test["收盘"].shift(1)
X_test['origin'] = (X_test['p_change'] + 1).cumprod()
X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod()
X_test[['strategy', 'origin']].dropna().plot()
plt.gcf().autofmt_xdate()
plt.show()
运行结果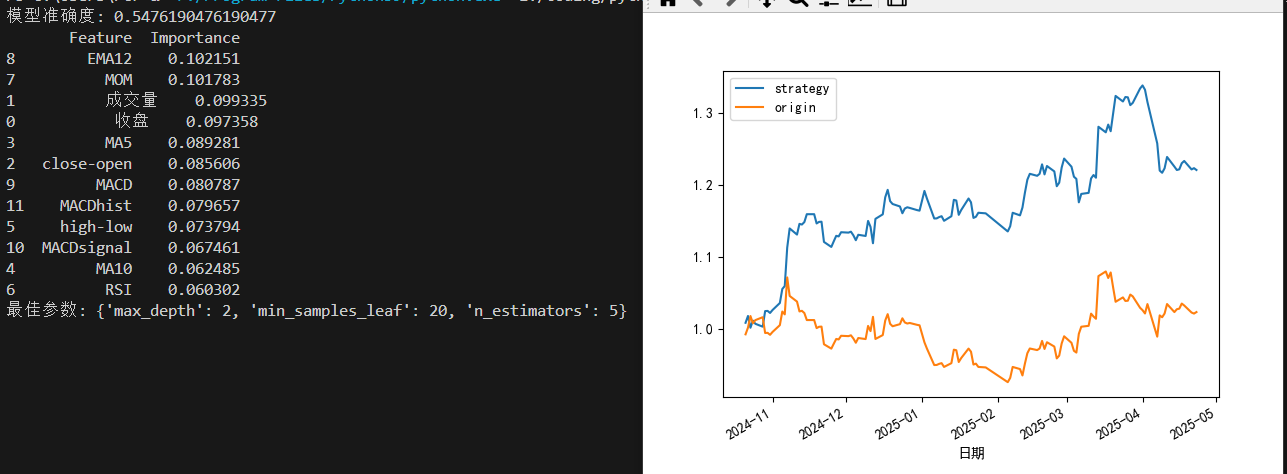


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









