







很多朋友问我学Python可不可以挣钱?答案是”当然可以!“
python爬虫肯定是可以当副业的,我身边一个伙伴就靠会python爬虫这一项技能一个月差不多能有一万多收入。
他截图给我看的他的收入图是这样的,人家一个月就靠接单这个副业都比很多人主业收入要多。
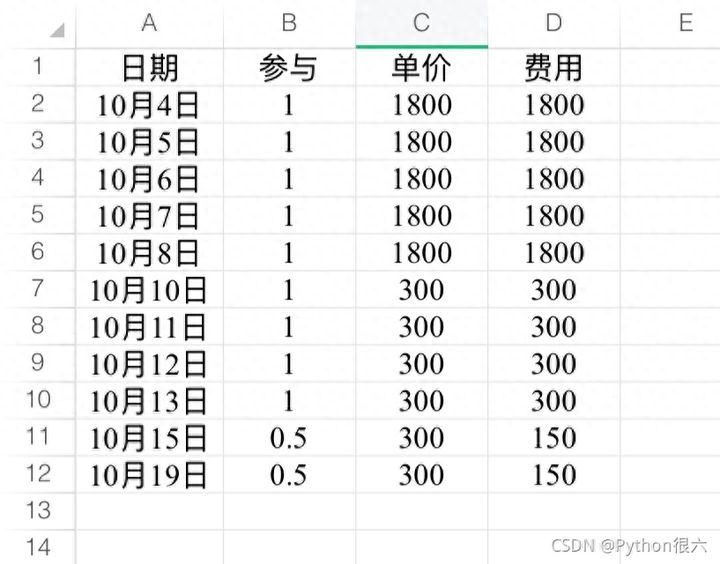
以上数据代表个人情况!
干货主要有:
- ① 200 多本 Python 电子书(和经典的书籍)应该有
- ② Python标准库资料(最全中文版)
- ③ 项目源码(四五十个有趣且可靠的练手项目及源码)
- ④ Python基础入门、爬虫、网络开发、大数据分析方面的视频(适合小白学习)
- ⑤ Python学习路线图(告别不入流的学习)

上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
👉[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]](安全链接,放心点击)

对爬虫陌生的朋友可能不太知道爬虫是什么。这里简单讲下:
爬虫是通过代码在互联网上高效大批量获取信息、整理信息的一种技术手段。大数据时代,如何在茫茫如海的网络中快速、大量、自动地获取想要的信息,并用于数据分析和决策?你就需要学会爬虫技术!
编写爬虫程序是一个非常有用的技能点,尤其对 Python 工程师而言甚至是必备技能。我们可以将数据采集到以后,通过数据清洗,结构化等步骤最后让数据用来做商业分析;也可以拿到信息并用于日常生活,比如买房前抓取对应地区历史成交记录再决策;还可以实现一个聚合应用,甚至未来能商业化运作……所以有一个职业叫做「爬虫工程师」。
在学习编程开发中,写爬虫是一个非常好的切入点,在实现爬虫的过程中既可以提高对应编程语言的熟悉程度,也可以把自己感兴趣的内容收集起来,以便得到进一步的利用。写爬虫是一个非常容易有成效和成就感的工作,你能快速地感受到编程的乐趣。
既然爬虫这么强大,那么爬虫到底可以用来做什么呢?比如:
- 拍图片、爬取视频
- 爬豆瓣Top250的电影、学术论文
- 爬淘宝的销售数据、房价的变化趋势
- 对股票市场进行分析和预测
- 把百度网盘的资源,存到数据库中(当然,只是保存资源的链接和标题),然后制作一个网盘的搜索引擎
等等等等除了以上的还有很多未经列举的,只要是你想要爬取的数据,只要你能通过浏览器访问的数据都可以通过爬虫获取。就连我们每天使用的百度,其实也就是利用了这种爬虫技术,每天放出无数爬虫到各个网站,把他们的信息抓回来供你使用。
总有人需要各类网站的数据,比如facebook、猫眼等大型数据类网站。通过一些外包网站,可以很快接到订单,一般我们向甲方提供爬虫、数据分析、数据清洗这样的服务。(可以去猪八戒等外包平台)
除了猪八戒网,国内国外都还有蛮多网站,我总结下,如果想学习怎么去这些平台接单赚外快,可以加入我下面这个群学习下,大佬还在线分享案例实操
总结下爬虫一些接单平台,可以收藏下,怕以后找不到:
一、国内接单平台
1、程序员客栈
程序员客栈中国非常领先的自由工作平台,为中高端程序员、产品经理和设计师等等互联网相关人员提供稳定的线上工作机会,包括自由工作、远程工作和兼职工作,还支持按需雇佣,工作模式非常多,感兴趣的推荐大家尝试一下。
虽然名称叫程序员客栈,但是除了程序员,像产品经理,设计师等等互联网相关人员,都能在上面找到适合自己的项目。感兴趣的可以体验一下。
2. CODING 码市
Coding 旗下的互联网软件外包服务平台,平台以外包为主。

3. 开源众包
开源中国的众包平台,主要是以众包为主。

4. 猪八戒
找兼职的地方,主要是入门级项目,不适合专业程序员,只适合新手。
5. 英选
平台以定制开发外包服务为主,也是外包项目平台。
6. 快码众包
7. 码易众包平台
8. 一早一晚平台
9. 开发邦
10. 人人开发
11. 厘米脚印

12. Sxsoft
13. 猿急送
14. 实现网传送门
15. 智城外包网
二、国外接单平台
1. Upwork
Upwork 是全球最大的、最优秀的、最规范的综合类人力外包服务平台,由著名的 Elance 和 oDesk 合并。这里聚集 900 万来自全球各地的自由工作者,你肯定可以在找到适合你的职位。
2. Freelancer
工作类型覆盖了很多不同的领域,由程序开发到市场营销、广告、会计、法务等一系列的可以远程的工作

3. Dribbble
你没看错,Dribbble 不只是全球最受欢迎的设计师社区,同样是设计师寻找远程工作的好出处。自从被 Tiny 收购后,Dribbble 的招聘属性正在慢慢增强,试着持续 PO 除了自己的好作品,等待你的伯乐,同样你可以关注 Jobs 页面,给心仪的 Team 提交简历。
4. Stackoverflow
被广大程序员熟知的 Stackoverflow 本身就是一个全民远程工作的公司,程序员在远程工作中有很大的先天优势,Stackoverflow Jobs 里面有远程职位的筛选,这里有丰富的远程技术职位。
5. 99designs
99designs 是一个专门针对设计师的雇佣平台,你可以在这里参加设计竞赛公开的项目投标,也可以给雇主提供一对一的专业服务。
6. Remoteok
Remoteok 不仅提供最初的兼职类远程工作,还有全职类,签署合同类和实习类的工作。网站创始人 Pieter Levels 本身就是一名数字游民,他同样是 Nomadlist 的创始人。
7. Toptal
Toptal 是一个高端一些的自由职业者平台,适合比较有经验和工作能力的远程工作者。它将企业与全球的软件工程师,设计师和业务顾问联系起来。

8. Ange
AngelList 主要是服务于初创公司和天使投资人的平台,这里还有初创公司提供的远程工作的机会,如果对远程加入初创公司感兴趣的,可以尝试一下。
9. Topcoder
Topcoder 通过算法比赛吸引世界顶级的程序员,他会将一下大型项目分割成很多小模块,通过竞赛的模式交给用户来做,优胜者可以拿到制定模块的奖金。
对于后面一个问题,python爬虫学到什么程度可以接单:
先你得要熟练使用Python爬虫,那么一些Python基础知识肯定需要了解,Python环境的安装和使用,Python基础语法,列表,字典,字符串的处理这些简单的知识都是需要学习的。
其次Python爬虫主要用到的库就是request库,这个库是你必须要学习的,获取到的数据还需要你自行处理,通过数据筛选规则,正则表达式等等技术进行筛选。
当然你还需要学习一些前端的基础知识,因为你爬取的数据都在网络上,所以前端基础你一定要懂,否则你可能都找不到你需要的数据,又何谈爬取数据。
还有就是现如今的很多网站都开发了属于自己的反爬机制,所以一些常见的反爬措施也是你需要学习的,不学习的话你也无法顺利爬取想要的数据。
到这里总结一下,想要自己写一个Python爬虫程序,你必须学会Python基础,包括环境安装,基础语法,字典,正则匹配,还有一些数据处理技术等等。其次就是模拟请求的库request,还有一些反爬技术和前端基础。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析学习等教程。带你从零基础系统性的学好Python!
上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









