









本文是一篇关于如何使用 Stable Diffusion 绘画的教程,包括软件介绍和案例带练。
在开始学之前,我想提前说一下,我所理解的 AI 绘画的本质,就是手替,人提出方案,AI 帮你完成具体的作画过程。
写这篇文章的初衷,网上的 Stable Diffusion 教程太多了,但是我真正去学的时候发现,没有找到一个对小白友好的,被各种复杂的参数、模型的专业词汇劝退。所以在我学了之后,想出一篇这样的教程,希望能帮助完全 0 基础的小白入门,即使完全没有代码能力和手绘能力的设计师也可以学得会的教程。
受限于篇幅,这篇只介绍最基本的操作,并且会带手把手带大家去做一个案例出来,让大家先把 AI 绘图的整个流程跑通。如果反馈还不错的话,下一篇补充一些进阶的操作。
另外我还想说的是,最近 AI 的工具越来越多,尤其是 AI 绘画,让大家变得越来越焦虑。我个人感觉要破解这种 AI 绘画带来的焦虑感,第一是要去了解它背后的原理,或者说它大概能做什么了解之后就相对没有那么焦虑了,第二是打不过就加入,让 AI 成为你的一个工具, 同时,即使通过 AI 可以抹平大家技法上的差距,但是审美上的差距是无法用 AI 抹平的,而这个可能会变成大家能力差距的重要来源。
一、软件总览
先给大家看一下我用 Stable Diffusion(以下称 SD)画出来的图,可以看到画面很细腻且用色也非常精致。

1. AI 绘画工具的选择
目前市面上最流行的两个绘图工具 Midjourney 和 Stable Diffusion 以及他们之间的区别,具体的研发背景等信息这里不做赘述,大家可以自行百度,只说一下对于设计师更关心的五个方面。

综上,从我的个人角度出发,SD 在工作中落地的潜力是要大于 MJ 的,这也是我选择学习和深入研究 SD 的原因。
2. 软件安装与打开
关于软件的安装,以及环境的部署,建议直接下载大佬们网上的整合包。这里推荐秋葉 aaaki 大佬的整合包,链接在这里: https://www.bilibili.com/video/BV17d4y1C73R
这里建议直接安装大佬的一键整合包,极大地降低了安装难度,对小白非常友好。
这里演示一下 Win 下如何安装,Mac 系统的同学也可以在网上找到对应的一键整合包,以及显卡不太好的同学也可以选择云端部署,这里给大家把链接贴出来。大家可以自行对照视频一步一步进行,基本没有什么难度。
Mac 芯片: https://www.bilibili.com/video/BV1Kh4y1W7Vg
云端部署: https://www.bilibili.com/video/BV1po4y1877P/
①下载后是这两个文件,先双击运行一下右边的程序,安装一些必要的运行环境,然后解压左侧的压缩文件到你想要安装的位置。

②然后打开解压后的文件夹,找到“A 启动器”的 exe 文件,双击打开。
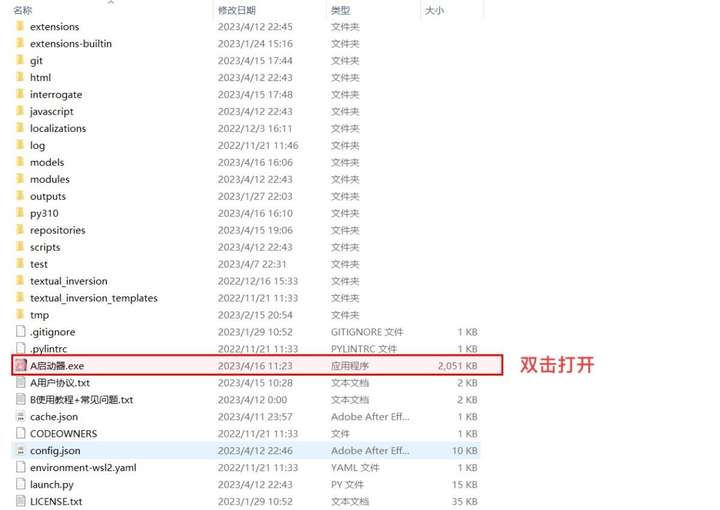
③打开后如图所示。
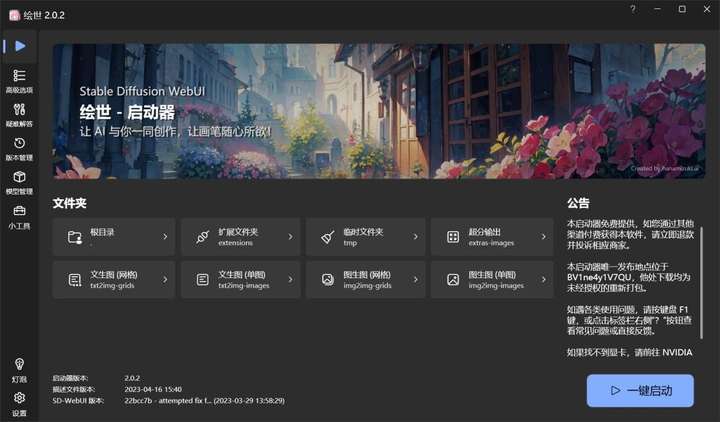
④然后点击“一键启动”,稍等片刻后会自动打开这个浏览器界面,就可以使用了(第一次打开时会有点久)
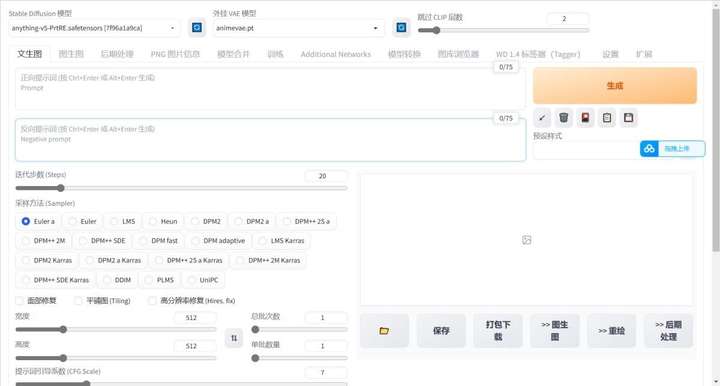
3. 流程和界面介绍
这里不去介绍 sd 的实现模型,只介绍一下我们所看到的呈现模型。可以理解为,就像是在做一道菜一样。首先准备原料(提示词和参数),然后按照菜谱(模型)来烹饪,让原料经历各种处理,最后就得到了可供品尝的美食(图像)。
下面是关于软件的界面整体布局介绍,主要是由三大模块构成的,模型,提示词和参数,后面的章节会具体介绍一下每个模块。
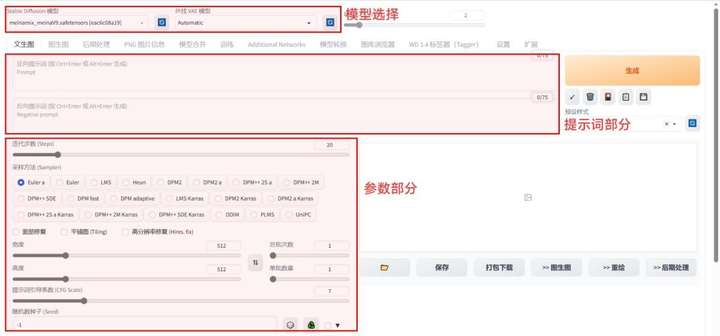
二、模型
1. 模型分类:SD 五大模型
如前面所说,模型就像是我们做菜时所用到的菜谱。每个模型都会有自己的风格,例如二次元画风,CG 画风等。
在 SD 中,目前共有 5 种模型。
- 基础底模型(单独使用):checkpoint
- 辅助模型(配合底模使用):Embedding,lora,Hypernetwork
- 美化模型:VAE
对于这几种的区别和使用方式,可以理解为基础底模型就是烹饪中的“炒”,而辅助模型则是“爆炒,小炒”,最后美化模型则是更细节的方式,例如(盐爆,葱爆,油爆)等。
在 sd 中,基础底模型必须有且只能有一种,而后面的模型则没有限制性,可以没有,也可以是一种或多种。
2. 模型的下载和使用
我们在下模型时,就可以看到对应的类别:这里以最常用的基础底模型(checkpoint)和 lora 模型为例,介绍一下它们怎么使用。
①首先我们要知道下载的模型是什么类别,如果是从上面两个网站下载的,那我们下载时就知道它的类别。如果是从其他渠道比如说别人的百度网盘链接,那这时,我们可以借助一个网站去获取模型类别: https://spell.novelai.dev/
②然后,将模型文件放到对应的文件夹中。在这里,我们可以同时放一张模型的预览图,然后将图片名称改成和模型一样,这样后面我们调用模型时,就可以直接根据预览图来选择。另外在模型的命名上,我们可以用 “/” 来对模型进行分类整理。例如一个模型是二次元相关的,就可以命名为“二次元/XXX” 。
③接下来就是模型的调用,对于基础底模型,我们可以直接在这里选择,如果没有找到,点一下右边的刷新按钮,稍等即可。VAE 模型则是在后面的下拉框中选择。这里可以一般采用默认的选项,然后如果出来的图发灰,再考虑使用 Vae 模型。对于其他模型,则需要先点一下这里的 icon,然后点一下想用的模型即可,这时上面的正向提示词输入框会出现对应的模型,想取消调用的话,再点一下模型或者直接在输入框中删掉即可。对于某一些模型,还需要在正向提示词输入框中输入特定的触发词,才可以让模型发挥效果。
三、提示词
提示词也就是我们对 AI 的指令。
- 正向提示词:即对画面的描述,例如,一个女孩,月亮,吉他,沙发等
- 反向提示词:指你不想在画面中出现的元素或属性。例如,低质量,畸形的手等
1. 基本规范
这里有两条基本规范需要注意一下:
- 提示词包括标点符号全部用英文的
- 单词、短语、句子基本上是等效的。例如“1gril、sofa、sitting”与“A girl sitting on the sofa”对 SD 来说是等效的。
2. 书写提示词的整体思路
在给正向提示词的时候,我们一般通过分类描述的方式来给出。具体可以分为以下三类:整体描述、主体、场景。
①整体描述
这里包括四个方面:
画质:高画质还是中等画质或者低画质,2k、或者 4k 等等
画风:CG、二次元、真人等
镜头:画面中人物的占比,半身像还是全身像
色调:冷色调或暖色调
②主体
对于人物主体的描述包括三个方面:头部、服饰、姿势
③头部
这里面包括的内容和我们玩游戏时捏脸的内容差不多,具体也就是包括这些内容:
- 眼睛大小、颜色和形状,鼻子大小和形状,嘴巴大小和形状,下巴形状等等。
- 皮肤颜色和纹理:人物的皮肤颜色和纹理,例如光滑或有皱纹的皮肤等等。
- 面部特征细节:进一步描述人物的面部细节,例如眼睛的纹理、唇色、发色,等等。
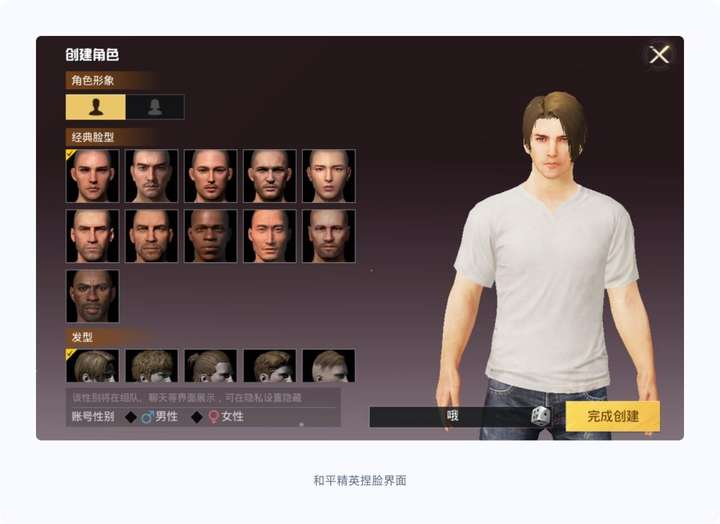
④服饰
包括衣服,裤子、鞋以及其他更细节的比如袜子之类的
⑤姿势
即人物的姿势,坐立跑等
⑥场景
基础的场景描述一般包括三个内容:时间、地点、天气,进阶的表达可以加入一些细节,例如天空中的蝴蝶、花瓣等。
3. 提示词的语法
仅仅有了提示词还不够,我们还需要知道怎么把提示词组成 SD 可以识别的格式。
①提示词的连接方式
- 不同的提示词之间用英文逗号分隔
- 提示词越靠前,权重越高,所以主体应该放在前面
②提示词的强化/弱化方式
- (提示词:权重数值)。其中这个数值的取值范围是 0.1~100,默认是 1,小于 1 是弱化,大于 1 是强化。例如:(a girl:0.8)
- (提示词)[提示词]。提示词外面加()表示强化,加[]表示弱化。允许套多层来增强强化或弱化的程度。例如:((a girl))
③提示词的进阶玩法
这里推荐几个提示词的网站。在掌握了提示词的基本用法后,再去看这些网站就会更得心应手一些。
- https://prompttool.com/NovelAI
- https://wolfchen.top/tag/
- https://moonvy.com/apps/ops/
- http://poe.com/ChatGpt
四、参数
这里不想去说太多参数的官方解释,而且,在初期并不是所有的参数都需要了解,所以这里直接用通俗易懂的语言来给大家介绍一下需要用到的参数是什么,以及怎么用。
1. 采样方法
这里的原理比较复杂,笔者这里直接抛出结论:
一般情况下使用 DPM++ 2M 或 DPM++ 2M Karras 或 UniPC,想要一些变化,就用 Euler a、DPM++ SDE、DPM++ SDE Karras、DPM2 a Karras。
2. 迭代步数
这里指的是 sd 用多少步把你的描述画出来。这里先给出结论,一般 20 到 40 步就足够了。迭代步数每增加一步迭代,都会给 AI 更多的机会去比对提示和当前结果,并进行调整。更高的迭代步数需要更多的计算时间。但并不意味着步数越高,质量越好。
这里是相同提示词和参数,不同迭代步数时的表现。可以看到在这组参数下,步数在 32 左右表现是最好的,从 32 到 40 提升不大,到 48 时以及出现了一些畸形,到 64 时腿部已经完全畸形了。

3. 面部修复
根据个人喜好开关,这个对最终成像效果影响不大。
4. 平铺图
这个一般用不到。
5. 高分辨率修复
通俗来说,就是以重新绘制的方式对图像进行放大,并且在放大的同时补充一些细节。
打开后,这里会出现一些子参数。
放大算法:用默认值即可。
高分迭代步数:一般选在 10~20 即可。这里还是以这个图为例,可以看到在步数超过 20 后就开始出现了畸形。

重绘幅度:一般是 0.5~0.8 之间。幅度过小,效果不好,幅度过大时,和原图差异太大。
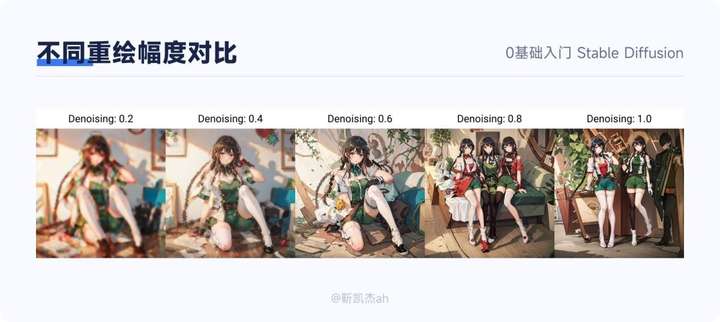
放大倍率:这个比较好理解,就是指最终的图原来图的分辨率的比值。例如,默认生成的图是 512_512,设定为 2 倍后,最终产出的图就是 1024_1024。
6. 总批次数和单批数量
这个是指一次性出图的数量。以搬砖为例,同样是搬 4 块砖,体力好的人可以一次搬 4 块,只搬一次,对应到 SD 中,就是总批次数是 1,单批数量为 4;而体力不好的人一次只能搬一块,需要搬 4 次,对应到 SD 中,就是总批次数是 4,单批数量为 1。一般而言,如果不是顶级显卡,我们都会保持单批数量为 1,去改变总批次数来增加一次性出图的数量。
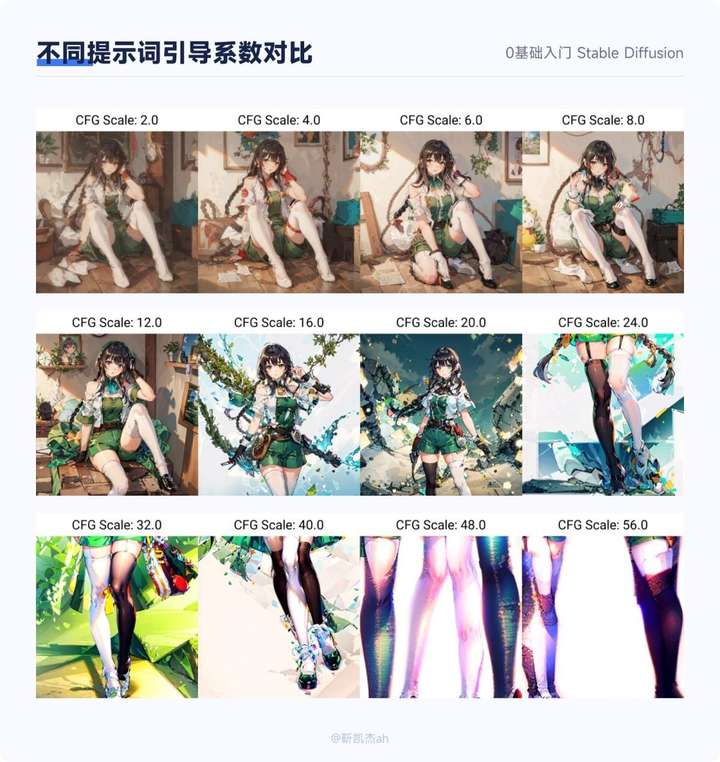
7. 提示词引导系数
最终生成的画面和你的描述词的趋近程度,一般设置为 7~15 之间,太高也会出现问题。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉大厂AIGC实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉12000+AI关键词大合集👈

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









