









1. Midjourney与SD的文生图功能对比
Midjourney和SD都在文生图功能中可以通过提示词来生成画面。但两者的适用层面和难度有所不同。
- Midjourney:适用于初学者,简单的提示词就可获得高质量画面。
- SD:提示词设计需要需精细,长度可达上百个单词。
我们可以从一个最简单的例子来看:a cat,两款软件都采用最基本配置。
简单指令:Mj效果高于SD
Midjourney:V5.2
 mj绘图,单图1024x1024
mj绘图,单图1024x1024
画面精致,色彩丰富,很有艺术感。
SD基础模型:majicmixFantasy_v20模型
 SD基础模型,单图512x512
SD基础模型,单图512x512
SD基础模型,绘图效果相对比较朴素,其中第二张图,小猫的尾巴和身体脱落,是个比较明显的Bug。
SD高级模型:SDXL正式版
 SDXL高级模型,单图1024x1024
SDXL高级模型,单图1024x1024
高级模型绘制效果,写实程度以及非常出色,但整体风格在简单指令a cat下,较为朴素,不够炫酷。
总体上,在简单指令(无脑绘图)情况下:Mj绘图的下限明显高于SD。
精细指令:SD绘图的效果上限、可能性更加丰富
SD的特点在于,可以通过精细化的指令设置,达到非常专业级的设计效果,比如特定效果的艺术字。(这个例子,没有Mj的对比,因为Mj目前不支持这样的定制化设计。)
 SD绘制的效果图,来源:小红书
SD绘制的效果图,来源:小红书
SD精细绘图效果好的同时,也带来另一个挑战,绘图指令非常复杂,甚至会达到小作文的长度。因此,搞定SD的指令、生成技巧,是关键的技能。
2. SD的提示词设计
画面描述:正面、负面
从软件界面就能看出,SD的提示词分为两部分:正面提示词和负面提示词。
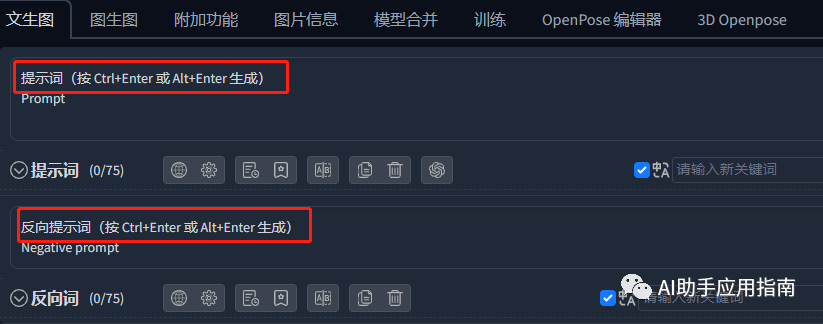
- 正面提示词:描述期望画面中出现的元素和效果。
- 负面提示词:代表不希望出现的元素、效果。
以公园草坪为例,正面提示词可包括树木、花草、小动物,负面提示词可排除人、广告牌等非自然物体。
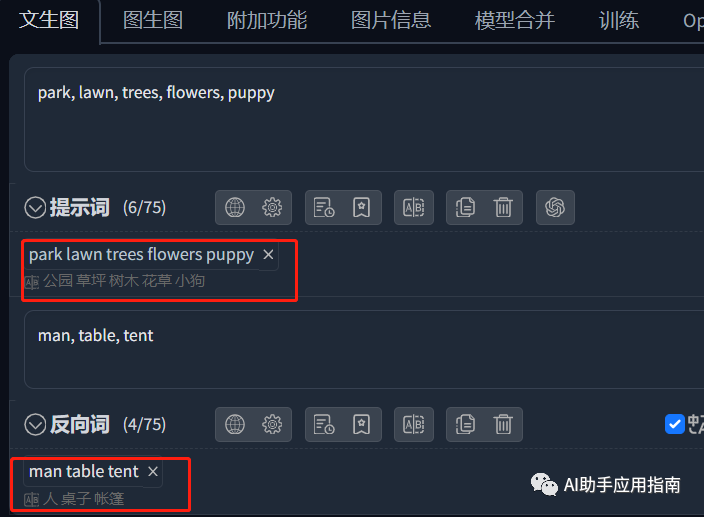
按以上的设定,绘图效果:
 正面、负面提示词示例
正面、负面提示词示例
在这个画面中,我们想要的正面要素(公园、草地、花、小狗)都有出现,负面要素(人、桌子、帐篷)都没有出现。这就是对画面要素控制的基本思路。
注意,负面提示词在Mj中只能通过--no A,B的语法来控制,但从实操效果来看,不明显,可控性较差。负面提示词的控制能力,是SD的一大优势。
风格与背景描述
SD能得到精准控制的图像,提示词一方面描述画面中的物体,一方面描述画面的风格。
- 场景描述:室内室外
indoor, outdoor、大背景forest, city - 环境与光照:白天或黑夜
day, night、晴天阴天clear, cloudy。 - 视角设定:近距离或远距离
close-up, distant、视角方向from above, view of back等。 - 绘图风格:卡通
Cartoon、摄影Photorealistic等等。
这些描述词,本质上与Mj的提示词没有明显区别。
权重描述
在SD中,我们可以对具体的描述词的权重进行精细地控制,明确制定我们更看重什么。
- 强调语法:
(key word)或者(key word:1.5) - 弱化语法:
(key word)或者(key word:0.9)
比如,我们在画面中强调park,而弱化tree:
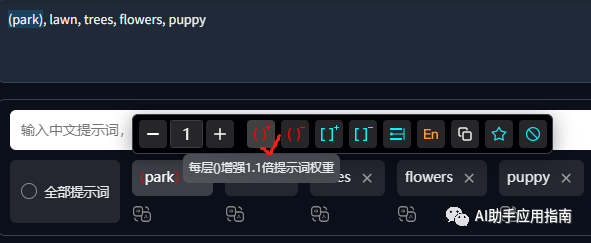 增加权重
增加权重
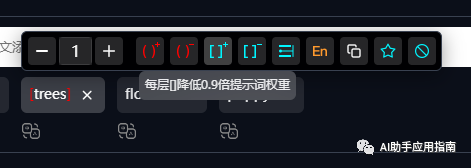 降低权重
降低权重
完整的SD指令效果
综合了以上种种语法,再叠加其他的高级技术,一个精细的画面描述往往呈现出非常复杂的形态:
(masterpiece, best quality:1.3), 8k, HD, CGproduct asw, no humans, still life,Tiktok logo, water, reflection, liquid, flower, leaf, (yellow|orange:1.1), day, bright lighting, white background <lora:CGproduct asw_v1:0.5>
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry,
生成SD的提示词三种策略
尽管提示词的设定有一点复杂性,但基本原理与Midjourney也是相似的,我们可以通过一些基本策略,快速提高效率。
策略1:直接翻译
- 操作方式:将所想画面直接翻译成英文让软件绘制。
- 优点:操作简单。
- 不足:对画面的精细控制能力有限。
- 适用场景:初步尝试和简单项目。
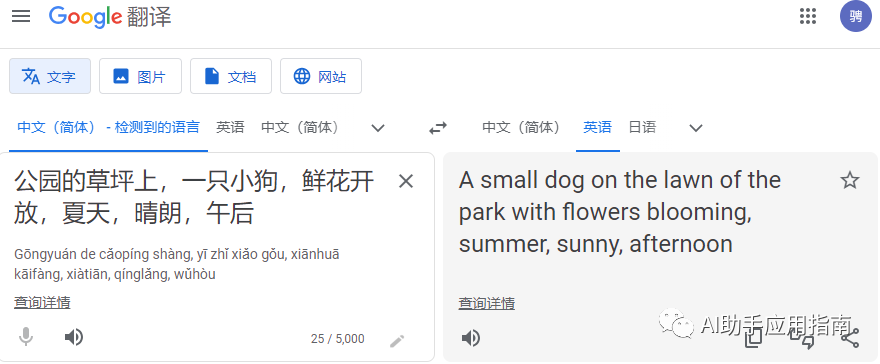
这样的得到提示词:A small dog on the lawn of the park with flowers blooming, summer, sunny, afternoon

策略2:使用专门的软件生成提示词
- 操作方式:利用已有工具生成复杂专业的提示词。
- 优点:达到高效果,适合不同复杂程度的项目。
- 现状:国内外已有很多人开发此类工具。
两个代表性的工具站:
- http://www.atoolbox.net/Tool.php?Id=1101
- https://ai.dawnmark.cn/
以dawnmark网站为例:
- 摄影效果选择
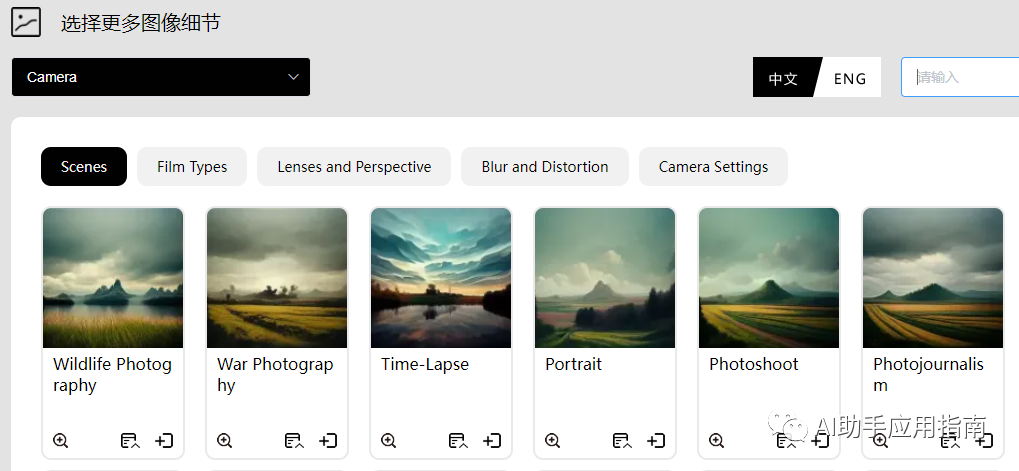
- 色系选择
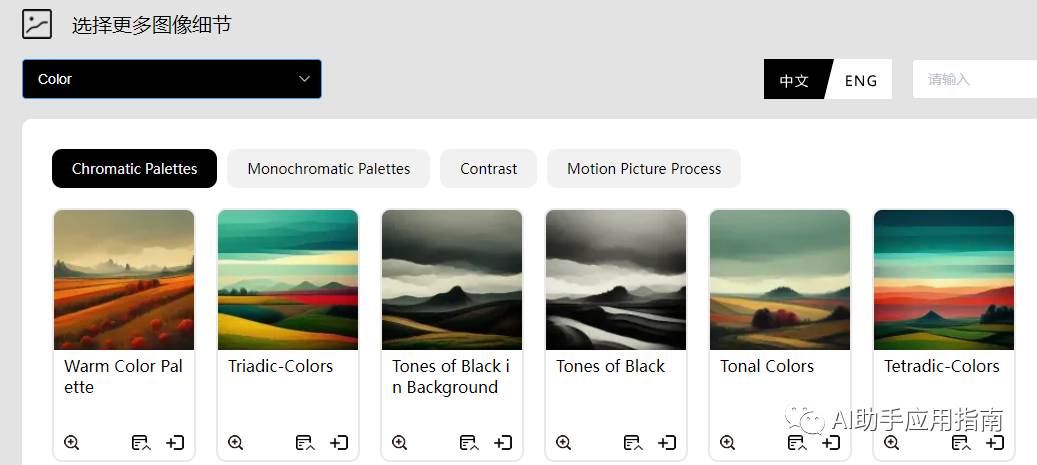
- 光线选择
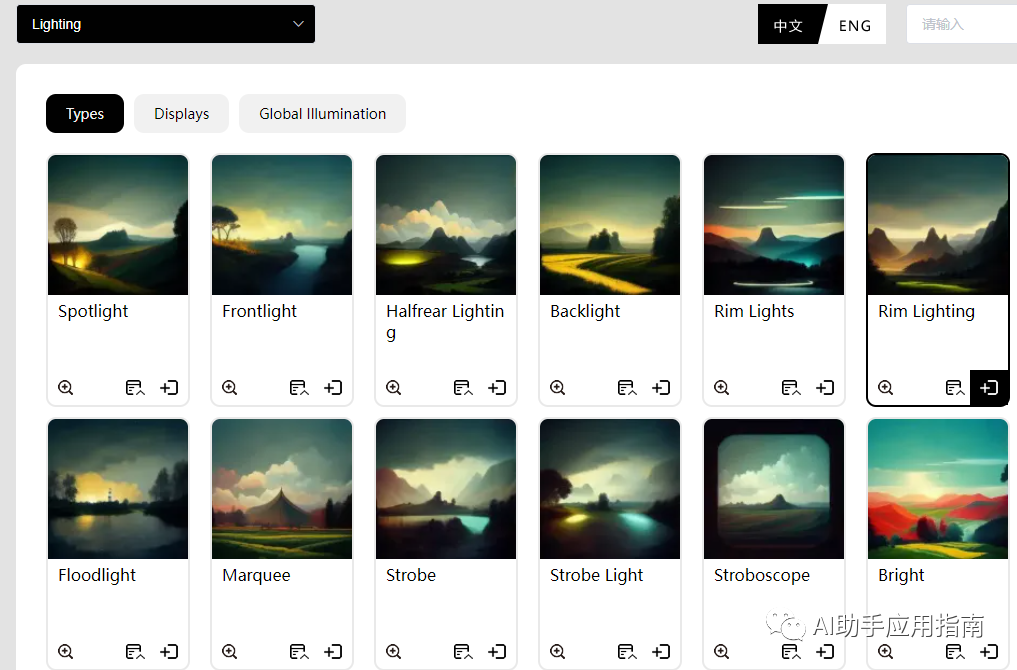
综合多种选择,可以得到组合的效果描述:in a symbolic and meaningful style, Rim Lighting, CRT, Triadic-Colors, Portraita (一种象征性且有意义的风格,边缘照明、CRT、三色、肖像)

综合风格提示词设定的绘图效果:

虽然美观补足,但的确刷出了一个特色的效果。
策略3:抄作业法
- 操作方式:寻找高质量的图像及其对应提示词进行学习或复制。
- 优点:更容易达到好效果。
- 来源:小红书上的博主、AI绘图社区等,都在分享图片时提供相关提示词。
以国外SD社区https://prompthero.com 为例,直接提供了抄作业按钮。
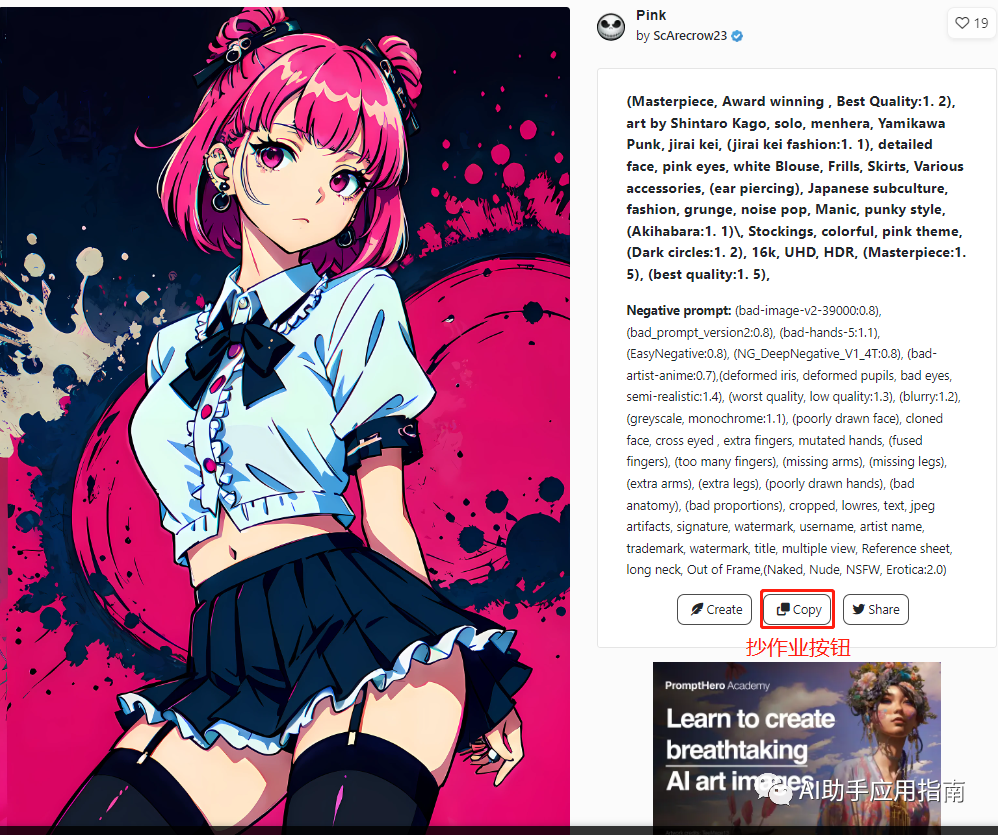
这个例子中,一部分提示词是通用的正面、负面提示词,可以作为长期的模板:
正面提示词:
(Masterpiece, Award winning , Best Quality:1. 2)
翻译:(杰作、获奖、最佳质量:1. 2)
负面提示词:
Negative prompt: (bad-image-v2-39000:0.8), (bad_prompt_version2:0.8), (bad-hands-5:1.1), (EasyNegative:0.8), (NG_DeepNegative_V1_4T:0.8), (bad-artist-anime:0.7),(deformed iris, deformed pupils, bad eyes, semi-realistic:1.4), (worst quality, low quality:1.3), (blurry:1.2), (greyscale, monochrome:1.1), (poorly drawn face), cloned face, cross eyed , extra fingers, mutated hands, (fused fingers), (too many fingers), (missing arms), (missing legs), (extra arms), (extra legs), (poorly drawn hands), (bad anatomy), (bad proportions), cropped, lowres, text, jpeg artifacts, signature, watermark, username, artist name, trademark, watermark, title, multiple view, Reference sheet, long neck, Out of Frame,(Naked, Nude, NSFW, Erotica:2.0)
翻译:负提示:(bad-image-v2-39000:0.8)、(bad_prompt_version2:0.8)、(bad-hands-5:1.1)、(EasyNegative:0.8)、(NG_DeepNegative_V1_4T:0.8)、(bad-artist-anime: 0.7),(虹膜变形、瞳孔变形、眼睛不好、半写实:1.4)、(最差质量、低质量:1.3)、(模糊:1.2)、(灰度、单色:1.1)、(脸部绘制不佳)、 克隆脸、斗鸡眼、额外的手指、变异的手、(融合的手指)、(手指太多)、(缺少手臂)、(缺少腿)、(额外的手臂)、(额外的腿)、(画得不好的手)、( 不良解剖学)、(不良比例)、裁剪、低分辨率、文本、jpeg 伪影、签名、水印、用户名、艺术家姓名、商标、水印、标题、多视图、参考表、长脖子、画框外
在抄作业方面,需要注意的是:
- 在MJ(Made Journey)中,直接用提示词就可以完全复现。
- 在SD中,画面设置的参数、选用模型、底图都会对生成的效果带来很大影响。
因此,真正复现一张照片在SD中可能需要更多精力。
结论
生成SD的提示词并不是一件轻松的工作,但通过理解和运用以上策略,我们可以有效地掌握这一技能。从直接翻译到使用专门的工具,再到抄作业法,不同的方法适用于不同的场景和需求。
特别是在SD中,我们需要对整个过程有更深入的理解,才能达到精细控制画面的目的。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1742
1742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









