









前言
本文使用软件为Bilibili社区核心贡献者秋叶大佬发布的整合包,跳过了绝大多数对网络、Python的前置知识要求。这让完全没有编程知识的人也能够从0开始学习使用Stable Diffusion,并且在几乎0调整的前提下就可以享受最新最核心的技术。可以说,从这一天开始从这一天开始&zhida_source=entity),AI绘画,尤其是SD的普及,又得到了更进一步的推动。
本文将基于最新的秋叶整合包,结合笔者整合的资源,为大家介绍最基础的概念和安装方式。
Stable Diffusion(SD)是什么
Stable Diffusion是2022年发布的深度学习文本到图像生成模型,它是一种潜在扩散模型,它由创业公司Stability AI与多个学术研究者和非营利组织合作开发。目前的SD的源代码和模型都已经开源,在Github上由AUTOMATIC1111维护了一个完整的项目,正在由全世界的开发者共同维护。由于完整版对网络有一些众所周知的需求,国内有多位开发者维护着一些不同版本的封装包。开源社区为SD的普及做出了难以磨灭的贡献。
SD最大的特征,就是由于其开源的特性,可以在电脑本地上离线运行。可以在大多数配备至少8GB显存的适度GPU的消费级硬件上运行。笔者推荐显存线是12G。
由于AI训练和产出的本质是软硬件结合了的深度学习原理,因此常常会用到英伟达公司的显卡,以及相关的诸如CUDA、CUDNN,乃至python相关的深度学习组件如xformer、pytorch等,学习AI想要进阶的话非常容易碰到这些需要大量额外学习编程知识的内容,所以非常容易让小伙伴们感到困难。
本文以及秋叶包都不会涉及到这些内容,会比原版相对来说容易理解,也容易部署得多得多得多。
SD基本概念
大模型:用素材+SD低模(如SD1.5/SD1.4/SD2.1),深度学习之后炼制出的大模型,可以直接用来生图。大模型决定了最终出图的大方向,可以说是一切的底料。多为CKPT/SAFETENSORS扩展名。
VAE:类似滤镜,是对大模型的补充,稳定画面的色彩范围。多为CKPT/SAFETENSORS扩展名。
LoRA:模型插件,是在基于某个大模型的基础上,深度学习之后炼制出的小模型。需要搭配大模型使用,可以在中小范围内影响出图的风格,或是增加大模型所没有的东西。炼制的时候如果基于SD底模,在不同大模型之间更换使用时的通用性会较好。但如果基于特定的大模型,可能会在和该大模型配合时得到针对性的极佳效果。
ControlNet:神级插件,让SD有了眼睛,能够基于现有图片得到诸如线条或景深的信息,再反推用于处理图片。
Stable Diffusion Web-UI(SD-WEBUI):开源大神AUTOMATIC1111基于Stability AI算法制作的开源软件,能够展开浏览器,用图形界面操控SD。
秋叶包:中国大神秋叶开发的整合包。由于WEBUI本身基于GitHub的特性,绝大多数时候的部署都需要极高的网络需求,以及Python环境的需求。使用秋叶整合包,内置了和电脑本身系统隔离的Python环境,以及内置了Git,不需要了解这两个软件就可以运行。可以几乎忽视这样的门槛,让更多人能够享受AI出图。
软件部署
软件下载
可以下载笔者整合的资源包。
https://pan.baidu.com/s/1EcmHFTiJ5-yw3ztOElOtBw?pwd=L461
大模型除了资源包里的,还可以去LiblibAi下载。国内可用,服务器稳定。
LiblibAi - 中国领先原创AI模型分享社区www.liblibai.com/
下载完资源后,我们可以先安装启动器的运行依赖,并解压秋叶包本体。
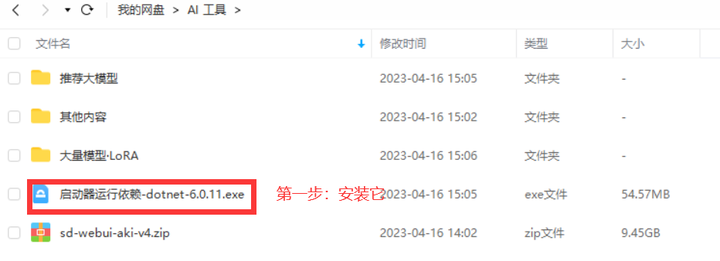

当我们解压好启动器本体的时候,暂时还不要启动,先一起把模型安装了。
导入核心数据
下载推荐大模型文件夹中的模型,

并把文件夹里的所有模型放在这个目录下:
\sd-webui-aki-v4\models\Stable-diffusion
同时,还要下载ControlNet模型,

ControlNet模型文件夹里的所有内容,放在这个目录下
\sd-webui-aki-v4\models\ControlNet
最后,需要单独下载LoRA

这些LoRA是笔者为了方便小伙伴们取用改了名的,需要全部放在这个目录下:
sd-webui-aki-v4\\models\lora
当大家上手之后就可以参考这一篇文章,并在【大量模型·LoRA】文件夹中寻找自己想要的LoRA了。

开启软件运行
解压并导入完毕上述数据之后,就可以点开启动器了。
在安装目录下往下拉,找到这个启动器,双击。

再点击右下角的一键启动。

再让这个界面跑一会儿

就可以看到它自动在浏览器中打开了一个新的网页,就算是启动成功了。

更多模型和LoRA介绍在这里:
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









