









你可能在使用LoRA模型时,总会因为LoRA的特定风格,影响到画面原本的人物形象,导致你可能需要不停的找新的LoRA模型去实验。作者本篇将会从“LoRA模型的分层控制”来介绍,如何在使用特定的LoRA模型,也可以不影响到画面原本的人物形象。如同下图这样的案例。

A4000显卡,SDWebUI原创生成
“LoRA分层控制”的教程,网络上已经有各路大佬总结过一些自己的分享了,不过在作者一一细品后,感觉都非常的学术派。在本篇作者就不再继续介绍学术理论了。感兴趣的朋友可以自行在B站或GitHub上查看相关的技术分享。
LoRA模型分层控制插件github.com/hako-mikan/sd-webui-lora-block-weight
作者本次分享将继续承接之前的AI漫画业务场景,介绍如何通过**“LoRA分层控制”**来进行角色形象风格的设定。
在介绍实操经验前,作者先简单介绍一下“如何使用LoRA模型的分层控制。”
众所周知,LoRA模型的标准使用格式为:
<lora:LoRA模型的名称:LoRA权重值>
而LoRA模型的分层控制,则是在LoRA权重值后,增加“:”,并添加的LoRA模型的17个分层的对应权重值代码。
<lora:LoRA模型的名称:LoRA权重值:分层权重值代码>
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BASE | IN01 | IN02 | IN04 | IN05 | IN07 | IN08 | MID | OUT03 | OUT04 | OUT05 | OUT06 | OUT07 | OUT08 | OUT09 | OUT10 | OUT11 |
如下表所示,LoRA的17个分层中,第一层是BASE层,也可以成为是开关层。代表这如果BASE层为0时,后面16层不管如何设置,LoRA的分层控制都无法使用。网上有一些大佬,强烈建议将开关层必须写为1(额…),这个作者持保留意见。
作者在多种LoRA模型的多轮实践后,推荐在二次元的AI绘画中,BASE层设为0.6,较为稳妥。如果这个值小于0.6,那么LoRA模型的特征将被淡化接近为无,如果大于0.6,比如为1时,LoRA模型的其他并不是你想要的特征将被放大。
如下图所示,作者在使用时,将17层权重值代码分为两部分:分层权重值(BASE层) + 分层代码(2~17层)
极虎漫剪 - LoRA分层控制功能
LoRA模型的应用场景
在二次元漫画的AI绘画场景中,LoRA模型主要用于让我们轻松画出特定的角色形象、场景穿搭、色彩画风。
那么我们将一个人物LORA的特征分下类 (人物LORA为例,容易理解)
角色容貌:主要为人物的脸型、五官等,有时候还伴有特定的表情和发型发饰。
角色服饰:主要为特定的服饰,比如机甲衣、汉服等;
画面风格:常见的画风多为仙侠风,国风,midjourney风格等;
LoRA | 角色容貌
分层权重值(BASE层):0.6
分层代码(2~17层):0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0
案例:
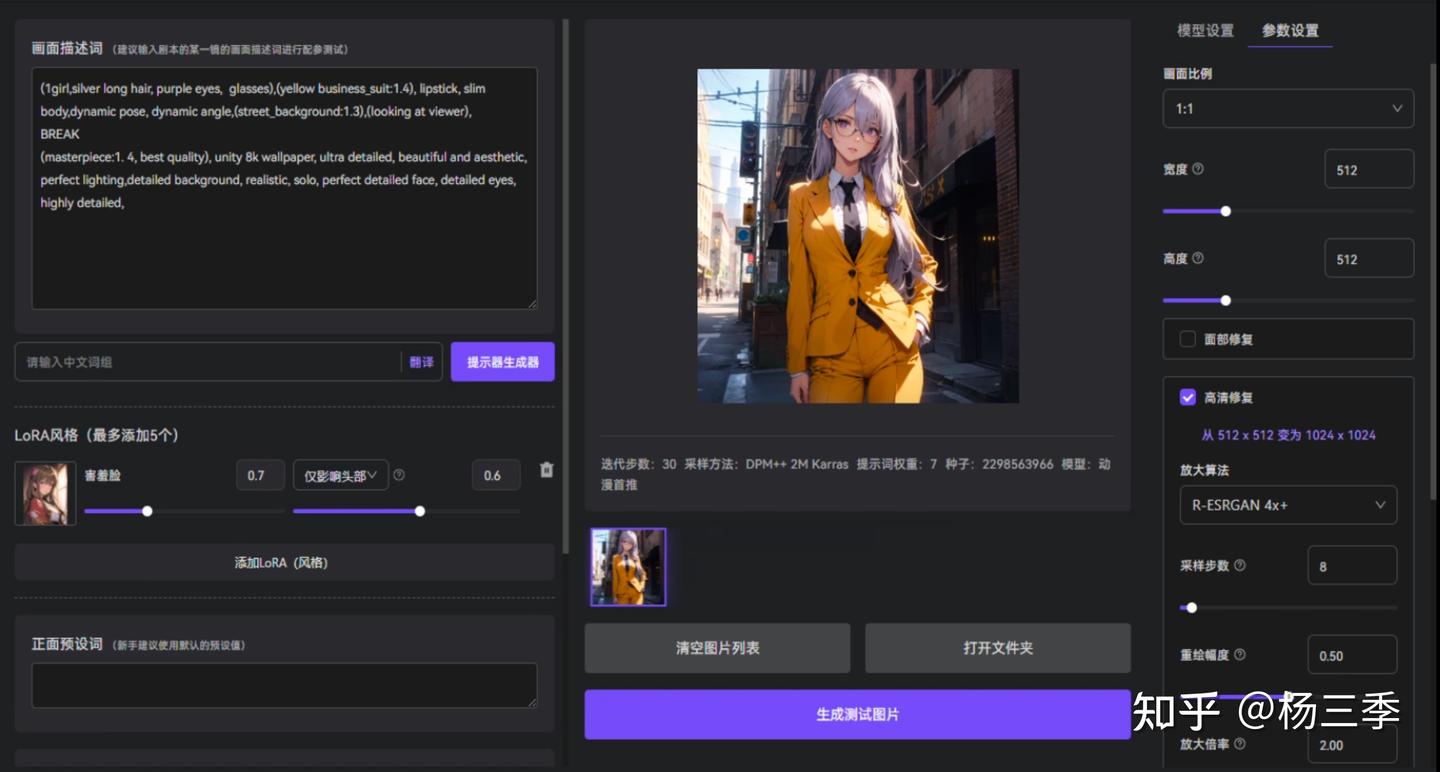
作者想生成的场景:一个穿着职业装的长发女孩下班后,走着街道。
画面描述:
- 中文:一个女孩,银色长发,紫色眼瞳,眼镜,口红,黄色职业装,纤细的身材, 走路,街道背景,看着屏幕
- 英文:1girl, silver long hair, purple eyes, glasses, lipstick, yellow business_suit, slim body, walking, street_background, looking at viewer,
(1girl, silver long hair, purple eyes, glasses),(yellow business_suit:1.4), lipstick, slim body, dynamic pose, dynamic angle,(street_background:1.3), (looking at viewer),
BREAK
(masterpiece:1.4, best quality), unity 8k wallpaper, ultra detailed, beautiful and aesthetic, perfect lighting, detailed background, realistic, solo, perfect detailed face, detailed eyes, highly detailed,
<lora:害羞脸:0.8:0.6,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0>

A4000显卡,SDWebUI原创生成
可以发现:
- 不使用LoRA的分层控制(不指定调用区域)时,LoRA模型影响了原本画面的结构(人物的姿态、发色、服装颜色等);
- 使用LoRA的分层控制(指定调用脸部区域)后,LoRA模型仅影响了原本画面人物的脸部区域;
- 在使用LoRA的分层控制后,并将BASE层数值从 0.6 调整至 1.0 后,LoRA模型除影响了原本画面人物的脸部区域外,还影响了姿态、发色。
因此,作者建议BASE层数值的默认值设为 0.6 ,因为不同的LoRA模型的训练的拟合程度不同,所以作者建议你使用时,也不能一味照搬,还是要基于实际结果调整。
LoRA | 角色服饰
分层权重值(BASE层):0.6
分层代码(2~17层):1,1,1,1,0,0.2,0,0.8,1,1,0.2,0,0,0,0,0
案例:
沿用上面的案例,作者希望女孩的服装不要太正式,时尚一点。因此此次加入了一个服装LoRA。
LoRA模型的地址:
是肚兜V1.0 - 1www.tusi.art/models/605263116525128948
(1girl, silver long hair, purple eyes, glasses),(yellow business_suit:1.4), lipstick, slim body, dynamic pose, dynamic angle,(street_background:1.3), (looking at viewer),
BREAK
(masterpiece:1.4, best quality), unity 8k wallpaper, ultra detailed, beautiful and aesthetic, perfect lighting, detailed background, realistic, solo, perfect detailed face, detailed eyes, highly detailed,
<lora:肚兜_shidudou:0.8:0.6,1,1,1,1,0,0.2,0,0.8,1,1,0.2,0,0,0,0,0>

A4000显卡,SDWebUI原创生成
可以发现:
- 不使用LoRA的分层控制(不指定调用区域)时,LoRA模型由于其训练特征,几乎影响了原本画面中的角色的全部特征(人物的姿态、发色、服装颜色等);
- 使用LoRA的分层控制(指定调用服装区域)后,LoRA模型除影响了原本画面人物的服装的内搭区域,其他部分影响很小;
- 在使用LoRA的分层控制后,并将BASE层数值从 0.6 调整至 1.0 后,LoRA模型除影响了原本画面人物的服装的内搭区域,对服装款式影响较大;
LoRA | 画面风格
分层权重值(BASE层):0.6
分层代码(2~17层):0,0,0,0.1,0.2,0,0,0,0,0.1,1,1,1,1,1,1
案例:
沿用上面的案例,作者希望整个画面有一种春天的温暖感。因此此次加入了一个风格LoRA。
LoRA模型的地址:
吐司独家 | 这盛世,繁荣景象 | Prosperity in a prosperous era - V1www.tusi.art/models/610809727502360072
(1girl, silver long hair, purple eyes, glasses),(yellow business_suit:1.4), lipstick, slim body, dynamic pose, dynamic angle,(street_background:1.3), (looking at viewer),
BREAK
(masterpiece:1.4, best quality), unity 8k wallpaper, ultra detailed, beautiful and aesthetic, perfect lighting, detailed background, realistic, solo, perfect detailed face, detailed eyes, highly detailed,
<lora:繁荣景象:0.8:0.6,0,0,0,0.1,0.2,0,0,0,0,0.1,1,1,1,1,1,1>

A4000显卡,SDWebUI原创生成
可以发现:
- 不使用LoRA的分层控制(不指定调用区域)时,LoRA模型由于其训练特征,几乎影响了原本画面中的角色的全部特征(人物的姿态、发色、服装颜色等);
- 使用LoRA的分层控制(指定调用上色层级)后,LoRA模型除对原本画面整体画风进行影响外,其他部分影响很小;
本期就介绍这三种较为通用的LoRA模型分层控制的案例,在作者的调研中,LoRA分层还可以指定特定姿态动作的调用,也可以反向调用,比如LoRA模型仅影响除头部以外的区域。但由于这几类分层代码的适用性不如以上三种的适用性高,因此作者就不在此次展开介绍了。有兴趣的朋友可以留言交流,也可以关注我的公众号
留言与我交流。
下期介绍
对于LoRA模型分层控制的实操就先介绍到这,下一篇将会介绍如何通过 Stable Diffusion 提示词生成特定的情绪表情以及画面视角的实操技巧。
A4000显卡,SDWebUI原创生成
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









