







原理
zookeeper
- 分布式系统就是在不同地域分布的多个服务器,共同组成的一个应用系统来为用户提供服务,在分布式系统中最重要的是进程的调度
- 分布式协调技术主要是用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种共享资源,防止造成资源竞争(脑裂)的后果
- 协调器就是分布式系统中经常提到的那个“锁”,通过这个“锁”机制,就可以保证分布式系统中多个进程能够有序的访问该共享资源。
- 把这个分布式环境下的这个“锁”叫作分布式锁,布式锁就是分布式协调技术实现的核心内容。
- 比较流行的是,Google的Chubby,还有Apache的ZooKeeper
- ZooKeeper提供基础的分布式锁服务,同时,也提供了数据的维护和管理机制,如:统一命名服务、状态同步服务、集群管理、分布式消息队列、分布式应用配置项的管理等等。
zookeeper的集群架构:
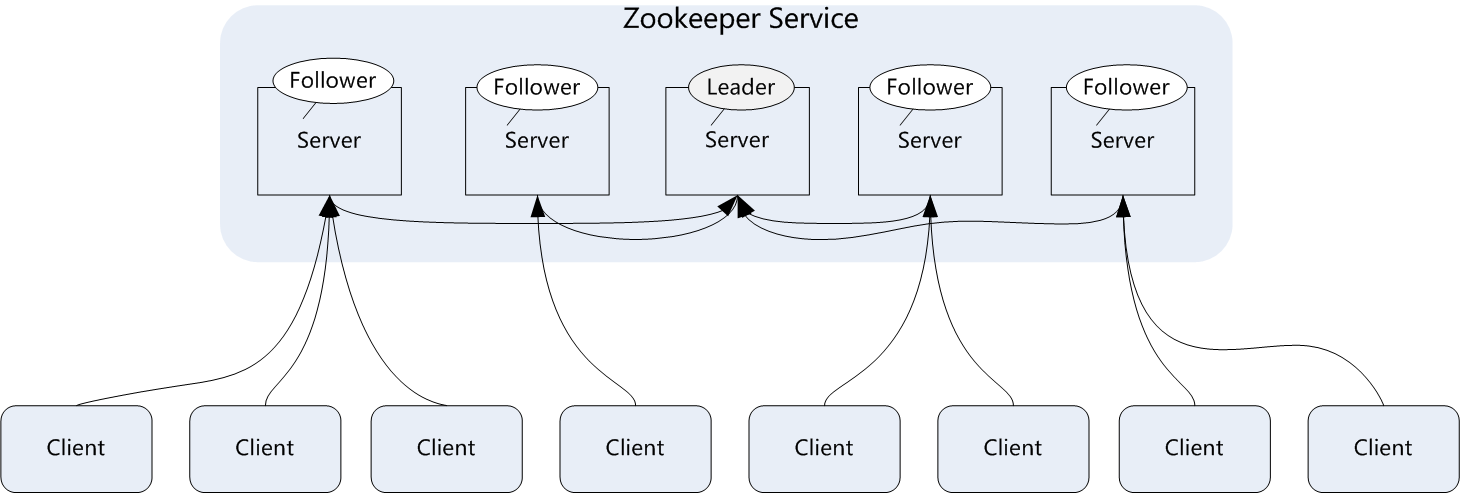
- zookeeper集群主要角色有server和client,其中server又分为leader、follower和observer三个
- 角色分为下面几种:
- Leader:领导者角色,主要负责投票的发起和决议,以及更新系统状态。
- follower:跟随着角色,用于接收客户端的请求并返回结果给客户端,在选举过程中参与投票。
- observer:观察者角色,用户接收客户端的请求,并将写请求转发给leader,同时同步leader状态,但是不参与投票。Observer目的是扩展系统,提高伸缩性。
- client:客户端角色,用于向zookeeper发起请求。
- 个人心得:
- 写操作为了保证一致性,通过leader协调
kafka
kafka是分布式消息系统,最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop平台的数据分析、低时延的实时系统、storm/spark流式处理引擎等。
角色:
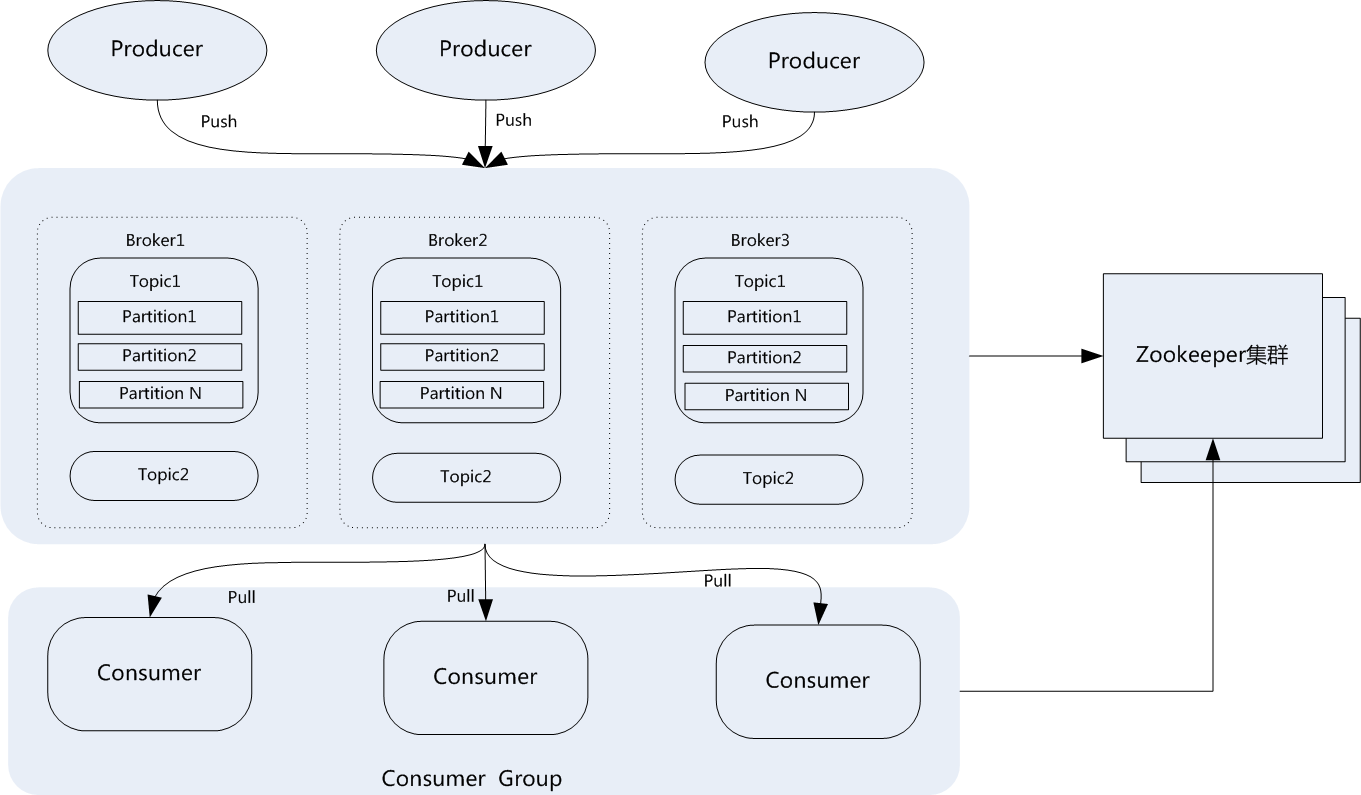
- Broker:Kafka集群包含一个或多个服务器,每个服务器被称为broker。(经纪人、中间商)
- Topic:每条发布到Kafka集群的消息都有一个分类,这个类别被称为Topic(主题)。
- Producer:指消息的生产者,负责发布消息到kafka broker。
- Consumer:指消息的消费者,从kafka broker拉取数据,并消费这些已发布的消息。
- Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition,每个partition都是一个有序的队列.partition中的每条消息都会被分配一个有序的id(offset)。
- Consumer Group:消费者组,可以给每个Consumer指定消费组,若不指定消费者组,则属于默认的group。
- Message:消息,通信的基本单位,每个producer可以向一个topic发布一些消息。
-
topic和partition,将Topic切分成多个partitions的好处是可以将大量的消息分成多批数据同时写到不同节点上,将写请求分担负载到各个集群节点。
- 推荐partition的数量一定要大于同时运行的consumer的数量。另外,建议partition的数量要小于等于集群broker的数量
- 在存储结构上,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件
- 在每个partition(文件夹)中有多个大小相等的segment(段)数据文件
- 后缀”.index“和“.log”分别表示为segment索引文件和数据文件
-
Producer生产机制: 发送消息到broker时,尽量均匀分布到不同的Partition里,实现负载均衡
-
Consumer消费机制
- 队列模式(queuing):只有一个消费组、只能被一个消费者消费
- 发布/订阅模式(publish-subscribe):多个消费组,每个消费组只有一个消费者,同一条消息可被多个消费组消费
部署安装
- docker-compose的样例:
- 原来的kafka-manager已弃用,https://github.com/vimagick/dockerfiles/tree/master/kafka-manager
- https://hub.docker.com/r/hlebalbau/kafka-manager/
-改用 https://github.com/vimagick/dockerfiles/blob/master/cmak/docker-compose.yml - 该例子中,使用了私人的wurstmeister/kafka,官方的zookeeper,vimagick/cmak的cmak版本
- kafka: https://github.com/wurstmeister/kafka-docker
- https://hub.docker.com/r/hlebalbau/kafka-manager/
- 原来的kafka-manager已弃用,https://github.com/vimagick/dockerfiles/tree/master/kafka-manager
通过docker-compose启动:
version: "3"
services:
zookeeper:
image: zookeeper
ports:
- "21060:2181"
volumes:
- ./data/zookeeper:/data
- ./log/zookeeper:/datalog
restart: unless-stopped
kafka:
image: wurstmeister/kafka:2.12-2.4.1
ports:
- "9061:9092"
volumes:
- ./data/kafka:/kafka
- /var/run/docker.sock:/var/run/docker.sock
environment:
- KAFKA_ADVERTISED_HOST_NAME=10.1.192.118
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- JMX_PORT=9999
depends_on:
- zookeeper
restart: unless-stopped
cmak: # Cluster Manager of Apache Kafka
image: vimagick/cmak
ports:
- "9060:9000"
environment:
- ZK_HOSTS=zookeeper:2181
- KAFKA_MANAGER_AUTH_ENABLED=true
- KAFKA_MANAGER_USERNAME=admin
- KAFKA_MANAGER_PASSWORD=admin
depends_on:
- zookeeper
healthcheck:
test: curl -f http://127.0.0.1:9000/api/health || exit 1
restart: unless-stopped
cmak使用
-
参看 官网介绍:https://github.com/yahoo/CMAK
-
集群管理
-
主题列表
-
Topic View
-
Consumer List View # 有bug,看不到效果
-
Consumed Topic View # 有bug,看不到效果
-
Broker List
-
Broker View
python程序调用
kafka-python 注意安装命令为pip install kafka-python
!!注意kafka的版本!!
以kafka-2.11-2.1.1 为例:前面的版本号是编译 Kafka 源代码的 Scala 编译器版本,真正的 Kafka版本号实际上是 2.1.1。那么这个 2.1.1 又表示什么呢?
- 前面的 2 表示大版本号,即 Major Version;
- 中间的 1 表示小版本号或次版本号,即 Minor Version;
- 最后的 1 表示修订版本号,也就是 Patch 号。
要注意kafka客户端支持的版本号与kafka的版本一致:
比如:kafka-python客户端的Compatibility中支持的版本为2.4~0.8
而在镜像 wurstmeister/kafka中的最新版本是2.5版本
若版本不一样,在kafka日志中会出现下面异常:
org.apache.kafka.common.errors.ControllerMovedException:Received update metadata request with correlation id 0 from an old controller
创建队列
from kafka import KafkaAdminClient
from kafka.admin import NewTopic
admin = KafkaAdminClient(bootstrap_servers='10.1.192.118:9061')
topic = NewTopic(name='test', num_partitions=1,replication_factor=1)
admin.create_topics([topic])
读写队列
import threading, time
import json
from kafka import KafkaAdminClient, KafkaConsumer, KafkaProducer
is_exit = False
class Producer(threading.Thread):
def run(self):
producer = KafkaProducer(bootstrap_servers='10.1.192.118:9061',
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
while not is_exit:
producer.send('q_test1', {"date":time.localtime()})
time.sleep(2)
producer.close()
class Consumer(threading.Thread):
def run(self):
consumer = KafkaConsumer(bootstrap_servers='10.1.192.118:9061',
value_deserializer= lambda m: json.loads(m.decode('utf-8')))
consumer.subscribe(['q_test1'])
while not is_exit:
print('重新拉消息队列')
for message in consumer:
print("获得一个消息",message.value)
if is_exit:
break
consumer.close()
def main():
tasks = [ Producer(), Consumer()]
[t.start() for t in tasks ] # 启动线程
time.sleep(600) # 执行 600秒
is_exit = True
[t.join() for t in tasks] # 等待安全退出
if __name__ == "__main__":
main()
消费队列的auto_offset_reset参数
- earliest :当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
- latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
- none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
与其他消息中间件的区别是,消息被消费后还会继续保存,因为kafka是分布式设计,通过zookeeper维持偏移量,消息的删除是通过配置保留时间或者磁盘配额自动完成
默认值: auto_offset_reset = latest















 4421
4421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









