






原始论文:https://arxiv.org/abs/2008.12281
1.纠错整体流程
本文的纠错结构比较简单,如下图,利用bert对一个包含错误句子中的每一个词进行预测,然后利用过滤器对结果进行过滤,由于“五”和“一”不存在任何音似或形似的地方,所以“一”的位置不进行修改,这就是本文纠错的思路,非常简单吧

2.Head Filt 过滤器
本文的亮点就在于过滤器上,本文的过滤器实际上就是一个混淆集,只不过与之前的固定混淆集不同,本文的混淆集能够通过相似的笔画和初始混淆集进行自动扩展。比如下面这幅图中的例子,如果给定初始的混淆二元组(無,吾),由于“無”和“舞”笔画相近,通过本文的方法就能够学习到(舞,吾)也是易混淆的二元组。所以本文就是做了一个扩展这个混淆集的工作
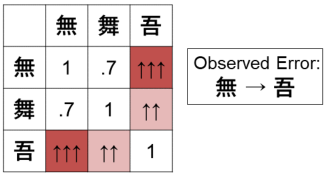
3.如何扩展混淆集?
如右下角所示,每个字都由一定的笔画组成,每一个笔画有一个向量表示,然后共同组成了字,那么字的向量可以通过笔画的向量得到,那么笔画的向量如何得到字的向量了,这里方法其实很多,作者采用TreeLSTM的方法获得,关于TreeLSTM具体可以参考论文https://arxiv.org/abs/1503.00075。然后通过两个字的向量就可以计算两个字的相似性了。
模型的训练细节如下:
-
TreeLSTM模型的训练就是使得相似的字得分接近1,不相似的字得分接近0
-
TreeLSTM模型训练的正样本为: 1.初始混淆集(可以认为是公开的混淆集)中的相似的字符;2.平行错误训练数据中的相似字符。负样本为:初始混淆集中不相似的字符。
-
TreeLSTM模型训练时,首先使用初始混淆集中正负样本进行训练,然后使用训练数据中的正样本进行训练,这样能够通过训练数据对原始混淆集进行扩展
















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









