







存储引擎就是存储数据、建立索引、更新 / 查询数据等技术的实现方式。它是基于表的,所以存储引擎也可被称为表类型,Mysql默认存储引擎类型为InnoDB。因为表的存储类型有很多,我这里只说一下常用的存储类型InnoDB和MyISAM。
可以通过show create table 表名;来查看当前表的存储引擎类型。

创建表的时候可以通过engine 指定存储引擎,如果不指定默认是InnoDB。
create table table(
id int,
name varchar(10)
) engine = MyISAM;
这里推荐先看一下mysql的底层数据结构 (超链接)
InnoDB存储引擎
我们可以通过my.ini文件的datadir参数查看mysql数据的存放目录,默认是在mysql安装目录下的data文件夹下,一个数据库对应一个文件夹。
-
InnoDB类型的数据表对应两个文件:
1.(表明).idb文件,该文件包含了索引信息和表数据信息。
2.(表明).frm文件,该文件包含了表格式定义。 -
InnoDB优点:InnoDB 是一个事务安全的存储引擎,支持4个事务隔离级别,支持多版本并发控制机制(mvcc算法),支持行锁,它具备提交、回滚以及崩溃恢复的功能以保护用户数据(通过日志文件bin-log进行数据库回滚)。效率非常慢。InnoDB类型的库是聚集索引,聚集索引可以理解为索引和数据结构不是存在在一起的(以后有时间详细说一下聚焦所以和非聚焦索引)。
-
InnoDB缺点**:清空整个表时,InnoDB 是一行一行的删除。
-
InnoDB 是一个聚集索引(叶子结点包含了完整的数据记录)。
为什么InnoDB 必须建主键,并且推荐使用整形的自增主键?
- mysql如果表中没有索引,会进行筛选,找到一列内容不重复的作为索引,如果所有的列都没有不重复的数据,mysql会建一列隐藏列,类似于row_id,作为索引列。
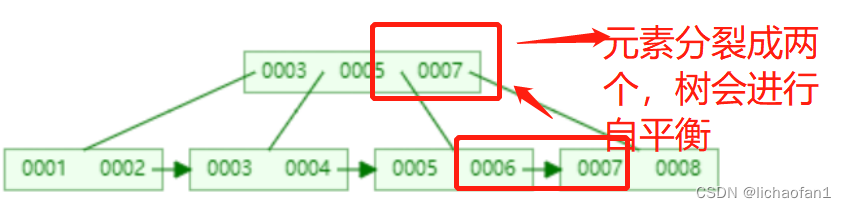
- 如下图,如果不是顺序插入的,较小的数据插入进来,会将索引元素分裂,然后对树进行一个平衡,索引会变动,影响效率。如果是自增的数据,节点满了之后只需要在后面新建一个节点就可以了,效率相对会高一点。

MyISAM存储引擎
- Myisam类型的数据表对应三个文件:
1.(表明).frm文件,该文件包含了表格式定义。
2.(表明).myd文件,该文件包含了表数据信息。
3.(表明)*.myi文件,该文件包含了索引信息。 - Myisam优点:myisan只支持全文索引,Myisam适合查询、插入为主的应用。清空整个表时,MyISAM 则会重建表。
- Myisam缺点:myisan不支持事务,不支持外键约束,最小颗粒锁是表锁,读写互相阻塞,写入不能读,读时不能写。
- myisan是非聚集索引。
InnoDB存储引擎 和 MyISAM存储引擎通过索引是怎么查询数据的?
InnoDB
- 首先看一下InnoDB,表中数据是和叶子节点在一起的(索引和数据信息在一个文件里面),非叶子节点是冗余节点,查找数据的时候,直接通过索引找到匹配就可以了。
- 比如col=30,会先把所有的根节点区查找,然后通过30 去索引中匹配,通过高效查找的算法(比如折半算法),然后找到位于30区间的磁盘页地址,直到最后找到根节点。因为根节点直接包含了数据,查询到此结束。

MyISAM
-
MyISAM的索引和数据信息是放在两个文件里面的,数据在*.myd文件,索引在.myi文件。查找数据信息的时候需要先找到索引,然后通过索引的存储地址找到对应的数据。
-
比如col=30,会先把所有的根节点区查找,然后通过30 去索引中匹配,通过高效查找的算法(比如折半算法),然后找到位于30区间的磁盘页地址,直到最后找到根节点,而根节点存的是数据的存储地址,还需要拿节点30的磁盘文件地址拿出来,然后去磁盘文件找记录。

聚集索引 和 非聚集索引
聚集索引对应的InnoDB
非聚集索引对应的MyISAM
聚集索引的效率要高于非聚集索引,聚集索引在查找数据的时候,直接找到叶子节点就可以了,非聚集索引找到叶子节点之后,还需用根据对应数据的磁盘文件地址去获取数据。















 1113
1113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









