







 本文详细介绍了大模型在文档解析、向量检索、RAG技术及多模态检索等领域的应用。重点讨论了如何将非结构化文档转化为结构化数据,以及在文本分割、向量数据库选型、检索策略和RAG模型评估等方面的技术原理。此外,还探讨了如何利用大模型进行多模态检索和增强,以及各种优化技巧,如模块添加、流程调整和Agent设计,以提升检索和推理性能。
本文详细介绍了大模型在文档解析、向量检索、RAG技术及多模态检索等领域的应用。重点讨论了如何将非结构化文档转化为结构化数据,以及在文本分割、向量数据库选型、检索策略和RAG模型评估等方面的技术原理。此外,还探讨了如何利用大模型进行多模态检索和增强,以及各种优化技巧,如模块添加、流程调整和Agent设计,以提升检索和推理性能。
原文地址:大模型应用技术原理
- 文档解析器
- 目标:将非结构化的文档(pdf,word,ppt等)转换为结构化数据
- 非结构文档分类
- 高度结构化的文档:基于标记语言的文本,md,html,latex
- 半结构化的文档:word等
- 低结构化的文档:ppt,pdf等
- 难点:OCR
- 公式:Nougat
- 表格:PaddleOCR,阿里追光,camelot,lineless_table_rec
- 文字:Umi-OCR,Rapid-OCR,PaddleOCR
- 文本分割器
- 基于规则的分割
- CharacterTextSplitter,RecursiveCharacterTextSplitter等
- 基于模型/算法的分割
- damo/nlp_bert_document-segmentation_chinese-base,NLTKTextSplitter,SpacyTextSplitter
- 针对高度结构化的非结构文本的分割器
- MarkdownTextSplitter,PythonCodeTextSplitter,HTMLHeaderTextSplitter,LatexTextSplitter等
- 面向token的分割
- SentenceTransformersTokenTextSplitter
- 基于规则的分割
- Embedding模型:Instruction+对称 VS 非对称
- 对称 query:question,text:text
- sentence-T5
- T5-encoder+mean pooling
- 无标注对比学习+有标注对比学习的两阶段训练
- sentence-T5
- 非对称:query:text
- GTR
- 与sentence-T5结构相同
- 将fine tune的数据集从NLI换成检索相关的,并且利用百度的rocketqa来获得hard negative
- 对比学习改成双向对比学习(每个batch里有两个对比学习损失,第一个损失是以query为中心去构建正负样本,第二个损失是以positive document为中心去构建正负样本)
- stella-v2
- 无instruction的非对称训练
- 带有hard negative样本的对比学习训练
- https://huggingface.co/infgrad/stella-large-zh-v2
- piccolo
- 无instruction的非对称训练
- 采用了无监督二元组对比学习预训练+hard negative三元组对比精调的两阶段的训练方式
- https://huggingface.co/sensenova/piccolo-base-zh
- GTR
- 混合
- Instructor
- 以GTR为基底模型,经过进一步的“instruction tuning”得到
- 将模型输入改成Task Instuction+[X]([X]代表具体的文本输入)
- m3e
- 无instruction的混合训练
- 朴素的对比训练,包含大规模对称和非对称语义数据训练
- GitHub - wangyuxinwhy/uniem: unified embedding model
- gte
- 基于非对称文本进行预训练,基于对称+非对称文本进行监督训练
- 无instruction的混合训练
- https://huggingface.co/thenlper/gte-large-zh
- bge
- 可选instruction的混合训练
- 基于RetroMAE进行预训练,基于对比训练进行二次监督训练
- GitHub - FlagOpen/FlagEmbedding: Dense Retrieval and Retrieval-augmented LLMs
- Instructor
- 对称 query:question,text:text
- 向量数据库
- 选型标准
- 开源 VS 闭源 VS 源码可见
- 客户端/SDK语言:python,rust,go...
- 托管方式
- self-hosted/on-premise
- redis,pgvector,milvus
- managed/cloud-native
- zilliz,pinecone
- embeded+cloud-native
- chroma,lanceDB
- self-hosted+cloud-native
- vald,drant,weaviate,vspa,elasticsearch
- self-hosted/on-premise
- 索引方法
- 算法
- Flat
- Tree-based:KD-Tree,Trinary Projection Trees,Annoy
- IVF-based:IVF,IVMF
- Graph-based:NSW,NSG,HNSW,DiskANN
- HNSW
-
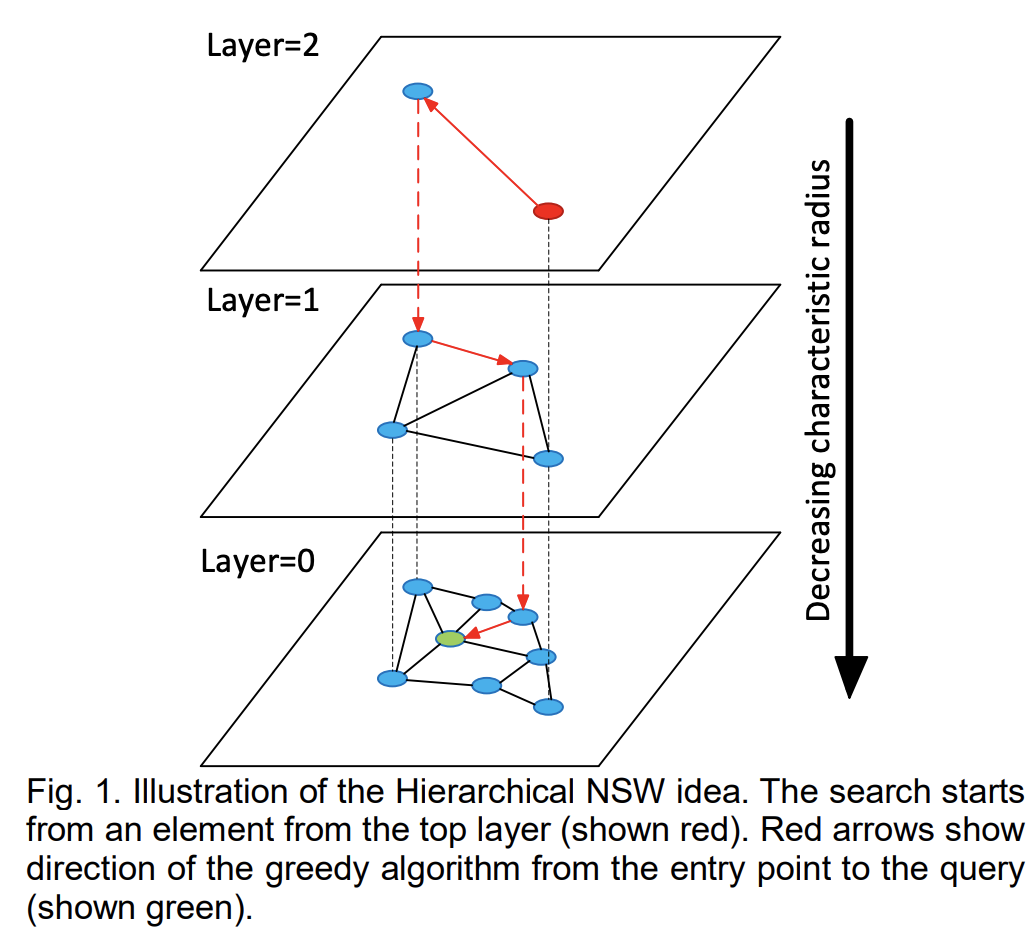
- 分层的可导航小世界(Hierarchical Navigable Small World,HNSW)是一种基于图的数据结构,它将节点划分成不同层级,贪婪地遍历来自上层的元素,直到达到局部最小值,然后切换到下一层,以上一层中的局部最小值作为新元素重新开始遍历,直到遍历完最低一层。它的基本思想是:跳表+NSW
- 跳表
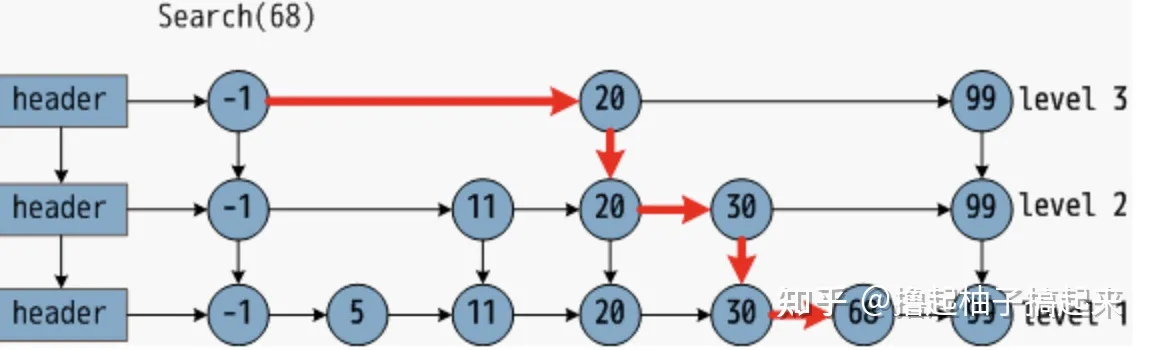
-
- NSW
- 核心思想:可导航小世界(Navigable Small World,NSW)将候选集合构建成可导航小世界图,利用基于贪婪搜索的kNN算法从图中查找与查询点距离最近的k个顶点。
- 近似Delonay图:向图中逐个插入点,对于每个新插入点,使用近似KNN搜索(approximate KNN search)算法从图中找到与其最近f个点集合,该集合中所有点与插入点连接。通过上述方式构建的是近似Delonay图,与标准Delonay图相比,随着越来越多的点被插入到图中,初期构建的短距离边会慢慢变成长距离边,形成可导航的小世界,从而在查找时减少跳数加快查找速度。
- 德劳内(Delaunay)三角剖分算法,这个算法可以达成如下要求:
- (1)图中每个点都有“友点”。
- (2&#
- HNSW
- 算法
- 选型标准
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









