






 本文探讨了大型语言模型在处理空间场景中的局限,并提出COS方法,通过符号表示改进空间理解。COS在空间任务中显著提升准确性和减少令牌消耗,如在BrickWorld中,ChatGPT的准确率提升60.8%。
本文探讨了大型语言模型在处理空间场景中的局限,并提出COS方法,通过符号表示改进空间理解。COS在空间任务中显著提升准确性和减少令牌消耗,如在BrickWorld中,ChatGPT的准确率提升60.8%。
原文地址:Chain-of-Symbol Prompting (CoS) For Large Language Models
论文地址:https://arxiv.org/pdf/2305.10276
大型语言模型需要理解通过自然语言描述的虚拟空间环境,并在环境中规划并实现定义的目标。
2024 年 1 月 29 日
摘要
尽管传统的“思维链”(Chain-of-Thought,CoT)提示方法在各种语言任务上表现出色,但在空间场景中的应用几乎未被探索。论文首先评估了LLMs在模拟自然语言的虚拟空间环境中理解和推理的能力。作者发现,即使是像ChatGPT这样的流行LLMs,在文本中处理空间关系方面仍然存在能力不足的问题。这引发了一个问题:自然语言是否是为LLMs表示复杂空间环境的最佳方式,或者是否存在其他更有效的方法,如符号表示。
为了解决这个问题,作者提出了一种新的方法,称为COS(Chain-of-Symbol Prompting),它在链式中间思维步骤中用简化的符号表示空间关系。COS易于使用,且不需要对LLMs进行额外训练。通过大量实验,作者表明COS在所有三个空间规划任务和现有的空间问答基准测试中的表现明显超过了用自然语言描述的CoT提示,同时在输入中使用的令牌数量也比CoT少。在Brick World任务中,ChatGPT的准确率提高了60.8%(从31.8%提高到92.6%),COS还显著减少了提示中令牌的数量,最多减少了65.8%。
论文的主要贡献包括:
- 在现有的经典空间理解任务和作者提出的合成空间规划任务上评估了LLMs的性能。作者发现即使使用CoT,当前LLMs的性能仍有提升空间。
- 提出了一种新的方法COS,它提示LLMs将用自然语言描述的复杂环境转换为简化的符号表示。COS显著提高了LLMs在空间任务上的准确性,同时也减少了LLMs的令牌消耗。
- 对COS进行了深入分析,探讨了使用不同符号、不同LLMs和不同语言对方法的影响,展示了COS的鲁棒性。
介绍
LLMs的空间挑战:传统的思维链提示一般对LLMs来说是有效的,但其在空间场景中的表现在很大程度上仍未得到探索。
LLMs和空间理解:这项研究调查了LLMs使用自然语言模拟虚拟空间环境的复杂空间理解和规划任务的性能。
当前LLMs的局限性:LLMs在处理文本提示中的空间关系方面表现出局限性,引发了自然语言是否是复杂空间环境最有效表示的问题。
CoS 简介:本研究提出了一种称为符号链提示 (CoS)的方法,该方法在链式中间思维步骤中用压缩符号表示空间关系。
CoS 易于使用,不需要额外的LLMs培训。
性能改进:在三个空间规划任务和现有空间 QA 基准中,CoS 优于自然语言的思想链 (CoT) 提示。
CoS 的性能提升高达 60.8% 的准确性(从 31.8% 到 92.6%),同时提示中使用的令牌数量也减少了。
注意事项
将空间任务转换为符号表示可能会增加该过程的复杂性和计算开销。
此外,它还需要注释,与自然语言中的思维链或基于程序的思维方法相比,注释可能更具挑战性
在某种程度上,描述供LLMs导航的虚拟空间环境是LLMs符号推理的延伸。
将符号推理与空间关系相结合是一种强大的组合,其中符号描述与其空间表示相联系。
这种方法的有效性是显而易见的,但挑战在于如何在没有任何手动干预或提示脚本的情况下自动大规模创建良好的 CoS 提示。
CoS
事实证明,LLMs在推理过程中表现出令人印象深刻的顺序文本推理能力,在遇到用自然语言描述的推理问题时,其表现会显着提升。
这种现象在称为“思想链”(CoT) 的方法中得到了清楚的说明,该方法引发了一些人称为“X 链”的现象。
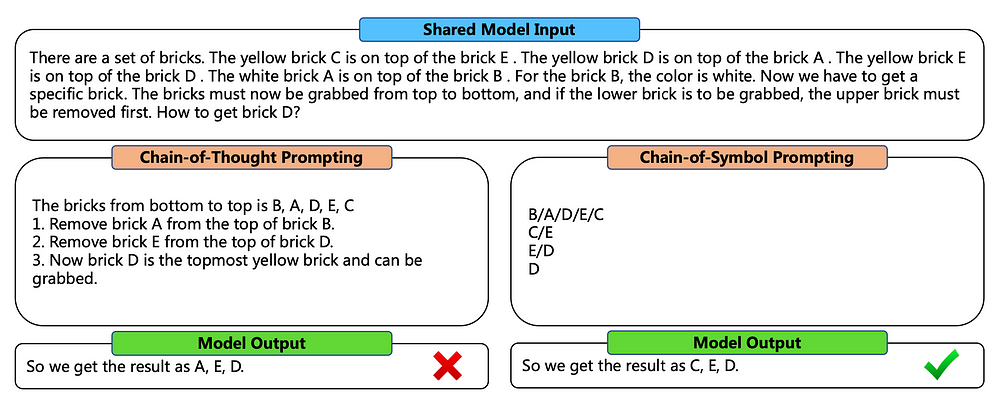
下图显示了思想链 (CoT) 和符号链 (CoS) 之间的比较,说明了LLMs如何通过改进的性能和令牌使用来处理复杂的空间规划任务。Source
建议的创建 CoS 演示的三步程序:
- 自动提示LLMs使用零样本方法生成 CoT 演示。
- 如果有任何错误,请更正生成的 CoT 演示。
- 将CoT中自然语言描述的空间关系替换为随机符号,并且只保留物体和符号,去除其他描述。
CoS 的优点
- CoS 与 CoT 不同,允许更简洁和精炼的程序。
- CoS 的结构使得人类注释者更容易一目了然地进行分析。
- CoS 提供了改进的空间考虑因素的表示,与自然语言相比,LLMs更容易学习。
- CoS 减少了输入和输出令牌的数量。

上图中的提示工程示例显示了 Brick World、基于 NLVR 的操作(自然语言视觉表示)和自然语言导航的建议任务。符号链突出显示。
Conclusion
当前流行的 LLMs 在复杂的空间规划和理解任务上仍然缺乏能力。为此,提出了一种新的方法,称为COS(链式符号提示),它将自然语言描述中的空间关系转换为链式中间思维步骤中的简化符号表示。COS易于使用,且不需要对LLMs进行额外训练。广泛的实验表明,使用少数示例的COS示范明显超过了使用自然语言描述的CoT在所有三个我们提出的空间规划任务和代表性的空间问答基准测试中的性能,同时在输入中使用的令牌数量也比CoT提示少(大约是CoT思维步骤令牌数量的1/3)。性能提升显著,例如在Brick World任务中ChatGPT的准确率提高了60.8%。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









