






原文地址:data-design-for-fine-tuning-llm-long-context-windows
微调LLMs以充分利用可用的上下文窗口。
2024 年 5 月 4 日
介绍
考虑到最近的研究,我发现有趣的是,某些微调和梯度技术的主要目的并不是将特定领域的数据注入语言模型。
相反,他们的主要目标是改变模型的行为,并通过微调数据的设计和结构来指导其执行特定任务。
这些任务包含推理、自我纠正和更好地处理大上下文等功能。 IN2 是这种方法的另一个例子。
问题
目前,许多大型语言模型(LLM)可以接收长文本作为输入。我们称之为上下文窗口或大上下文窗口。
然而,LLMs仍然难以在长期背景下充分利用信息,这被称为“lost-in-the-middle”。这是LLMs强调提交数据集开头和结尾的信息的现象。当对数据主体提出问题时,忽略中间部分。
引起"lost-in-the-middle"的根本原因源于隐藏在一般训练数据中的无意识偏差。
解决方案
最近的一项研究认为,长上下文训练期间缺乏明确的监督是造成这种现象的原因。
显性监督应明确强调这样一个事实:长上下文背景下的任何位置都可以掌握关键信息。
进入信息强化 (IN2) 培训
IN2 是一个纯粹的数据驱动解决方案,旨在克服中间迷失的问题。
IN2 训练利用合成的长上下文问答数据集,其中答案需要两个元素:
- 在合成的长上下文中对短片段进行细粒度的信息感知。
- 对两个或多个短片段的信息进行整合和推理。
在自回归预训练中,预测下一个标记通常更多地受到附近标记的影响,而不是远处标记的影响。
类似地,在监督微调中,强烈影响响应生成的系统消息通常放置在上下文的开头。这可能会产生偏差,表明重要信息总是出现在上下文的开头或结尾。
信息密集型(IN2)的重点是LLMs的培训,以明确地教导模型关键信息可以在整个上下文中集中呈现,而不仅仅是在开头和结尾。
IN2 是一个纯粹的数据驱动解决方案。
IN2 的方法
长上下文从 4K 到 32K 令牌,由许多短片段编译而成,每个短片段大约有 128 个令牌。
问答(QA)对询问位于一个或多个片段中的信息,这些片段在长上下文中随机定位。
生成两种类型的问题:
- 人们需要对单个短片段有详细的了解,
- 而另一个则需要对来自多个细分市场的信息进行整合和推理。
这些 QA 对是通过使用特定指南和原始片段指导 GPT-4-Turbo(OpenAI,2023b)生成的。
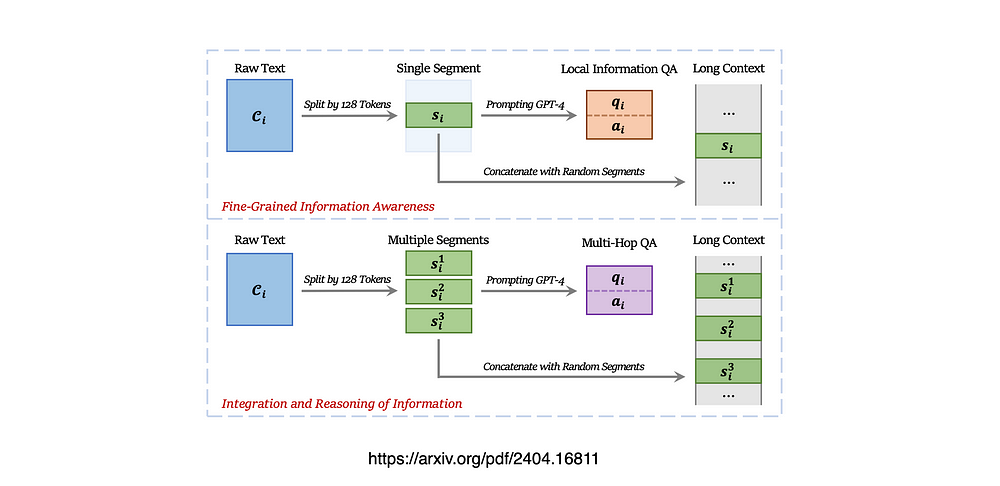
考虑上图,创建训练数据的流程:
上:增强细粒度信息意识
下:信息整合与推理
细粒度的信息感知
上下文的最小信息单元被认为是 128 个令牌段。
以下是该研究中的三个示例,说明了细粒度信息感知数据是如何设计的。

请注意该部分,即问题以及上下文中的适当答案。

下面是一个更长的例子,根据片段和答案全部在上下文中。

信息整合与推理
除了利用每个单独的片段之外,该研究还考虑了如何为两个或多个片段中包含的信息生成问答对。

下面是一个较短的答案示例。

还有另一种变化...

数据生成和训练提示
下面使用的模板...

最后
这项研究引入了 IN2 训练来解决中间迷失的挑战,并展示了探测任务和现实世界长上下文任务的显着增强,而不会牺牲短上下文场景中的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









