







MySQL之死锁问题分析、事务隔离与锁机制的底层原理剖析
一、MySQL中的死锁现象
所谓的并发事务,本质上就是MySQL内部多条工作线程并行执行的情况,也正由于MySQL是多线程应用,所以需要具备完善的锁机制来避免线程不安全问题的问题产生,对于多线程与锁而言,存在一个100%会出现的偶发问题,即死锁问题。
1.1、死锁问题概述(Dead Lock)
死锁是指两个或两个以上的线程(或进程)在运行过程中,因为资源竞争而造成相互等待、相互僵持的现象,一般当程序中出现死锁问题后,若无外力介入,则不会解除“僵持”状态,它们之间会一直相互等待下去。
1.2、MySQL中的死锁现象
而MySQL与Redis、Nginx这类单线程工作的程序不同,它属于一种内部采用多线程工作的应用,因而不可避免的就会产生死锁问题。当死锁问题出现时,MySQL会自动检测并介入,强制回滚结束一个“死锁的参与者(事务)”,从而打破死锁的僵局,让另一个事务能继续执行。
显示的定义了主键索引后,
InnoDB会基于该主键字段去构建聚簇索引,因此后续的update语句可以命中索引,执行时自然获取的也是行级别的排他锁。
1.3、MySQL中死锁如何解决呢?
预防死锁、避免死锁、解除死锁等,而当死锁问题出现后该如何解决呢?一般只有两种方案:
-
锁超时机制:事务/线程在等待锁时,超出一定时间后自动放弃等待并返回。
-
外力介入打破僵局:第三者介入,将死锁情况中的某个事务/线程强制结束,让其他事务继续执行。
1.3.1、MySQL的锁超时机制
在InnoDB中其实提供了锁的超时机制,也就是一个事务在长时间内无法获取到锁时,就会主动放弃等待,抛出相关的错误码及信息,然后返回给客户端。但这里的时间限制到底是多久呢?可以通过如下命令查询:
show variables like 'innodb_lock_wait_timeout';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_lock_wait_timeout | 50 |
+--------------------------+-------+默认的锁超时时间是50s,也就是在50s内未获取到锁的事务,会自动结束并返回。那也就意味着当死锁情况出现时,这个死锁过程最多持续50s,然后其中就会有一个事务主动退出竞争,释放持有的锁资源,这似乎听起来蛮不错呀,但实际业务中,仅依赖超时机制去解除死锁是不够的,毕竟高并发情况下,50s时间太长了,会导致越来越多的事务阻塞。
由于依靠锁超时机制,略微有些不靠谱,因此InnoDB也专门针对于死锁问题,研发了一种检测算法,名为wait-for graph算法。
1.3.2、死锁检测算法 - wait-for graph
这种算法是专门用于检测死锁问题的,在该算法中会对于目前库中所有活跃的事务生成等待图,在MySQL内部会生成一张这样的等待图:
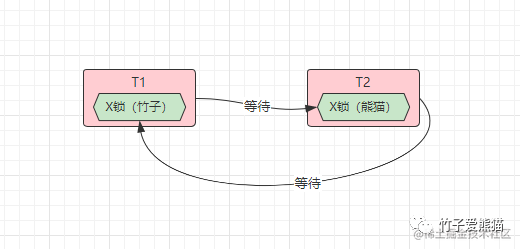
也就是T1持有着「竹子」这条数据的锁,正在等待获取「熊猫」这条数据的锁,而T2事务持有「熊猫」这条数据的锁,正在等待获取「竹子」这条数据的锁,最终T1、T2两个事务之间就出现了等待闭环,因此当MySQL发现了这种等待闭环时,就会强制介入,回滚结束其中一个事务,强制打破该闭环,从而解除死锁问题。
wait-for graph算法被启用后,会要求MySQL收集两个信息:
-
锁的信息链表:目前持有每个锁的事务是谁。
-
事务等待链表:阻塞的事务要等待的锁是谁。
每当一个事务需要阻塞等待某个锁时,就会触发一次wait-for graph算法,该算法会以当前事务作为起点,然后从「锁的信息链表」中找到对应中锁信息,再去根据锁的持有者(事务),在「事务等待链表」中进行查找,看看持有锁的事务是否在等待获取其他锁,如果是,则再去看看另一个持有锁的事务,是否在等待其他锁.....,经过一系列的判断后,再看看是否会出现闭环,出现的话则介入破坏。
库中有T1、T2、T3三个事务、有X1、X2、X3三个锁,事务与锁的关系如下:
事务与锁
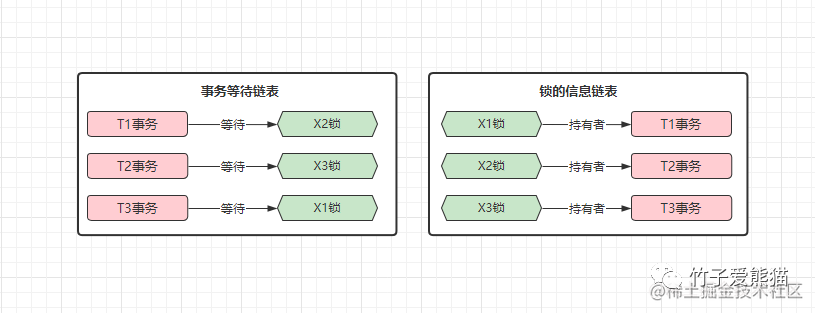
此时当T3事务需要阻塞等待获取X1锁时,就会触发一次wait-for graph算法,流程如下:
-
①先根据
T3要获取的X1锁,在「锁的信息链表」中找到X1锁的持有者T1。 -
②再在「事务等待链表」中查找,看看
T1是否在等待获取其他锁,此时会得知T1等待X2。 -
③再去「锁的信息链表」中找到
X2锁的持有者T2,再看看T2是否在阻塞等待获取其他锁。 -
④再在「事务等待链表」中查找
T2,发现T2正在等待获取X3锁,再找X3锁的持有者。
经过上述一系列算法过程后,最终会发现X3锁的持有者为T3,而本次算法又正是T3事务触发的,此时又回到了T3事务,也就代表着产生了“闭环”,因此也可以证明这里出现了死锁现象,所以MySQL会强制回滚其中的一个事务,来抵达解除死锁的目的。
但出现死锁问题时,
MySQL会选择哪个事务回滚呢?之前分析过,当一个事务在执行SQL更改数据时,都会记录在Undo-log日志中,Undo量越小的事务,代表它对数据的更改越少,同时回滚的代价最低,因此会选择Undo量最小的事务回滚(如若两个事务的Undo量相同,会选择回滚触发死锁的事务)。
同时,可以通过innodb_deadlock_detect=on|off这个参数,来控制是否开启死锁检测机制。
死锁检测机制在
MySQL后续的高版本中是默认开启的,但实际上死锁检测的开销不小,上面三个并发事务阻塞时,会对「事务等待链表、锁的信息链表」共计检索六次,那当阻塞的并发事务越来越多时,检测的效率也会呈线性增长。
1.3.3、如何避免死锁产生?
因为死锁的检测过程较为耗时,所以尽量不要等死锁出现后再去解除,而是尽量调整业务避免死锁的产生,一般来说可以从如下方面考虑:
-
合理的设计索引结构,使业务
SQL在执行时能通过索引定位到具体的几行数据,减小锁的粒度。 -
业务允许的情况下,也可以将隔离级别调低,因为级别越低,锁的限制会越小。
-
调整业务
SQL的逻辑顺序,较大、耗时较长的事务尽量放在特定时间去执行(如凌晨对账...)。 -
尽可能的拆分业务的粒度,一个业务组成的大事务,尽量拆成多个小事务,缩短一个事务持有锁的时间。
-
如果没有强制性要求,就尽量不要手动在事务中获取排他锁,否则会造成一些不必要的锁出现,增大产生死锁的几率。
其实简单来说,也就是在业务允许的情况下,尽量缩短一个事务持有锁的时间、减小锁的粒度以及锁的数量。
同时也要记住:当
MySQL运行过程中产生了死锁问题,那这个死锁问题以后绝对会再次出现,当死锁被MySQL自己解除后,一定要记住去排除业务SQL的执行逻辑,找到产生死锁的业务,然后调整业务SQL的执行顺序,这样才能从根源上避免死锁产生。
二、锁机制的底层实现原理
2.1、锁的内存结构
在Java中,Synchronized锁是基于Monitor实现的,而ReetrantLock又是基于AQS实现的,那MySQL的锁是基于啥实现的呢?
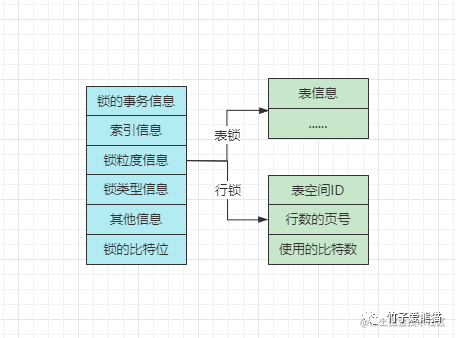
InnoDB引擎中,每个锁对象在内存中的结构如上,其中记录的信息也比较多,先全部理清楚后再聊聊锁的实现。
2.1.1、锁的事务信息
其中记录着当前的锁结构是由哪个事务生成的,记录的是指针,指向一个具体的事务。
2.1.2、索引的信息
这个是行锁的特有信息,对于行锁来说,需要记录一下加锁的行数据属于哪个索引、哪个节点,记录的也是指针。
2.1.3、锁粒度信息
这个略微有些复杂,对于不同粒度的锁,其中存储的信息也并不同,如果是表锁,其中就记录了一下是对哪张表加的锁,以及表的一些其他信息。
但如果锁粒度是行锁,其中记录的信息更多,有三个较为重要的:
-
Space ID:加锁的行数据,所在的表空间ID。 -
Page Number:加锁的行数据,所在的页号。 -
n_bits:使用的比特位,对于一页数据中,加了多少个锁(后续结合讲)。
2.1.4、锁类型信息
对于锁结构的类型,在内部实现了复用,采用一个32bit的type_mode来表示,这个32bit的值可以拆为lock_mode、lock_type、rec_lock_type三部分,如下:
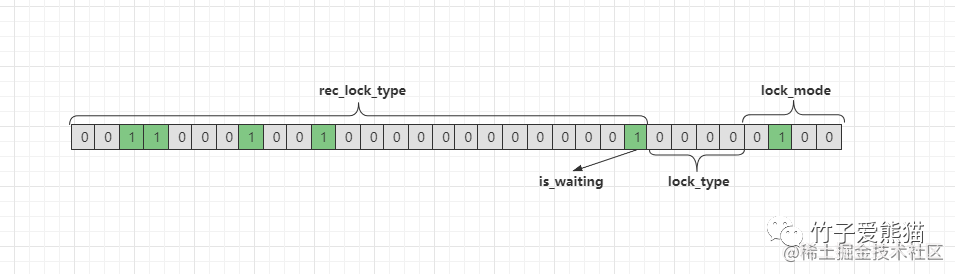
锁类型
-
lock_mode:表示锁的模式,使用低四位。-
0000/0:表示当前锁结构是共享意向锁,即IS锁。 -
0001/1:表示当前锁结构是排他意向锁,即IX锁。 -
0010/2:表示当前锁结构是共享锁,即S锁。 -
0011/3:表示当前锁结构是排他锁,即X锁。 -
0100/4:表示当前锁结构是自增锁,即AUTO-INC锁。
-
-
lock_type:表示锁的类型,使用低位中的5~8位。-
LOCK_TABLE:当第5个比特位是1时,表示目前是表级锁。 -
LOCK_REC:当第6个比特位是1时,表示目前是行级锁。
-
-
rec_lock_type:表示行锁的具体类型,使用其余位。-
LOCK_ORDINARY:当高23位全零时,表示目前是临键锁。 -
LOCK_GAP:当第10位是1时,表示目前是间隙锁。 -
LOCK_REC_NOT_GAP:当第11位是1时,表示目前是记录锁。 -
LOCK_INSERT_INTENTION:当第12位是1时,表示目前是插入意向锁。 -
内部还有一些其他的锁类型,会使用其他位。
-
-
is_waiting:表示目前锁处于等待状态还是持有状态,使用低位中的第9位。-
0:表示is_waiting=false,即当前锁无需阻塞等待,是持有状态。 -
1:表示is_waiting=true,即当前锁需要阻塞,是等待状态。
-
00000000000000000000000100100011
比如上面给出的这组bit,锁粒度、锁类型、锁状态是什么情况呢?如下:
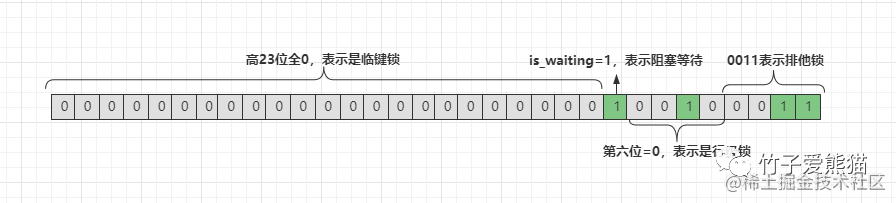
从上图中可得知,目前这组bit代表一个阻塞等待的行级排他临键锁结构。
2.1.5、其他信息
这个所谓的其他信息,也就是指一些用于辅助锁机制的信息,比如之前死锁检测机制中的「事务等待链表、锁的信息链表」,每一个事务和锁的持有、等待关系,都会在这里存储,将所有的事务、锁连接起来,就形成了上述的两个链表。
2.1.6、锁的比特位
与其说是锁的比特位,不如说是数据的比特位,好比举个例子:
SELECT * FROM `zz_student`;
+------------+--------+------+--------+
| student_id | name | sex | height |
+------------+--------+------+--------+
| 1 | 竹子 | 男 | 185cm |
| 2 | 熊猫 | 女 | 170cm |
| 3 | 子竹 | 男 | 182cm |
| 4 | 棕熊 | 男 | 187cm |
| 5 | 黑豹 | 男 | 177cm |
| 6 | 脑斧 | 男 | 178cm |
| 7 | 兔纸 | 女 | 165cm |
+------------+--------+------+--------+学生表中有七条数据,此时就会形成一个比特数组:000000000,行锁中,间隙锁可以锁定无穷小、无穷大这两个间隙,因此这组比特中,首位和末位即表示无穷小、无穷大两个间隙。
好比此时T1事务,对ID=2、3、6这三条数据加锁了,此时这个比特数组就会变为001100100,表示T1事务同时锁定了三条数据。而之前聊到的n_bits,它就会记录一下在这组比特中,多少条记录被上锁了。
2.2、InnoDB的锁实现
如果一个事务同时需要对表中的
1000条数据加锁,会生成1000个锁结构吗?
如果这里是SQL Server数据库,那绝对会生成1000个锁结构,因为它的行锁是加在行记录上的,但MySQL锁机制并不相同,因为MySQL是基于事务实现的锁。来看看:
-
①目前对表中不同行记录加锁的事务是同一个。
-
②需要加锁的记录在同一个页面中。
-
③目前事务加锁的类型都是相同的。
-
④锁的等待状态也是相同的。
当上述四点条件被满足时,符合条件的行记录会被放入到同一个锁结构中,好比以上面的问题为例:
假设加锁的
1000条数据分布在3个页面中,同时表中没有其他事务在操作,加的都是同一类型的锁。
此时依据上述的前提条件,那在内存中仅会生成三个锁结构,能够很大程度上减少锁结构的数量。总之情况再复杂,也不会像SQL Server般生成1000个锁对象,那样开销太大了!
2.3、MySQL获取锁的过程
当一个事务需要获取某个行锁时,首先会看一下内存中是否存在这条数据的锁结构,如果存在则生成一个锁结构,将其is_waiting对应的比特位改为1,表示目前事务在阻塞等待获取该锁,当其他事务释放锁后,会唤醒当前阻塞的事务,然后会将其is_waiting改为0,接着执行SQL。
实际上会发现这个过程并不复杂,唯一有些难理解的点就在于:事务获取锁时,是如何在内存中,判断是否已经存在相同记录的锁结构呢?还记得锁结构中会记录的一个信息嘛?也就是「锁粒度信息」,如果是表锁,会记录表信息,如果是行锁,会记录表空间、页号等信息。在事务获取锁时,就是去看内存中,已存在的锁结构的这个信息,来判断是否存在其他事务获取了锁。
拿表锁来说,当事务要获取一张表的锁时,就会根据表名看一下其他锁结构,有没有获取当前这张表的锁,如果已经获取,看一下已经存在的表锁和目前要加的表锁,是否会存在冲突,冲突的话
is_waiting=1,反之is_waiting=0,而行锁也是差不多的过程。
释放锁的过程也比较简单,这个工作一般是由MySQL自己完成的,当事务结束后会自动释放,释放的时候会去看一下,内存中是否有锁结构,正在等待获取目前释放的锁,如果有则唤醒对应的线程/事务。
其实看下来之后大家会发现,MySQL的锁机制实现,与常规的锁实现有些不一样,一般的锁机制都是基于持有标识+等待队列实现的,而MySQL则是略微有些不一样。
三、事务隔离机制的底层实现
对于并发事务造成的各类问题,在不同的隔离级别实际上,是通过不同粒度、类型的锁以及MVCC机制来解决的,也就是调整了并发事务的执行顺序,从而避免了这些问题产生,具体是如何做的呢?
-
RU/读未提交级别:要求该隔离级别下解决脏写问题。 -
RC/读已提交级别:要求该隔离级别下解决脏读问题。 -
RR/可重复读级别:要求该隔离级别下解决不可重复读问题。 -
Serializable/序列化级别:要求在该隔离级别下解决幻读问题。
虽然DBMS中要求在序列化级别再解决幻读问题,但在MySQL中,RR级别中就已经解决了幻读问题,因此MySQL中可以将RR级别视为最高级别,而Serializable级别几乎用不到,因为序列化级别中解决的问题,在RR级别中基本上已经解决了,再将MySQL调到Serializable级别反而会降低性能。
当然,
RR级别下有些极端的情况,依旧会出现幻读问题,但线上100%不会出现。
3.1、RU(Read Uncommitted)读未提交级别的实现
对于RU级别而言,从它名字上就可以看出来,该隔离级别下,一个事务可以读到其他事务未提交的数据,但同时要求解决脏写(更新覆盖)问题,那思考一下该怎么满足这个需求呢?先来看看不加锁的情况:
SELECT * FROM `zz_users` WHERE user_id = 1;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
+---------+-----------+----------+----------+---------------------+
-- ----------- 请按照标出的序号阅读代码!!! --------------
-- ①开启一个事务T1
begin;
-- ③修改 ID=1 的姓名为 竹子
UPDATE `zz_users` SET user_name = "竹子" WHERE user_id = 1;
-- ⑥提交T1
commit;-- ②开启另一个事务T2
begin;
-- ④这里可以读取到T1中还未提交的 竹子 记录
SELECT * FROM `zz_users` WHERE user_id = 1;
-- ⑤T2中再次修改姓名为 黑熊
UPDATE `zz_users` SET user_name = "黑熊" WHERE user_id = 1;
-- ⑦提交T2
commit;假设上述两个事务并发执行时,都不加锁,T2自然可以读取到T1修改后但还未提交的数据,但当T2再次修改ID=1的数据后,两个事务一起提交,此时就会出现T2覆盖T1的问题,这也就是脏写问题,而这个问题是不允许存在的。
写操作加排他锁,读操作不加锁!
还是上述的例子,当写操作加上排他锁后,T1在修改数据时,当T2再次尝试修改相同的数据,也要获取排他锁,因此T1、T2两个事务的写操作会相互排斥,T2就需要阻塞等待。但因为读操作不会加锁,因此当T2尝试读取这条数据时,自然可以读到数据。
因为写-写会排斥,但写-读不会排斥,因此也满足了
RU级别的要求,即可以读到未提交的数据,但是不允许出现脏写问题。
MySQL-RU级别的实现原理,即写操作加排他锁,读操作不加锁。
3.2、RC(Read Committed)读已提交级别的实现
理解了RU级别的实现后,再来看看RC,RC级别要求解决脏读问题,也就是一个事务中,不允许读另一个事务还未提交的数据。
写操作加排他锁,读操作加共享锁。
以之前的例子来说,因为T1在修改数据,所以会对ID=1的数据加上排他锁,此时T2想要获取共享锁读数据时,T1的排他锁就会排斥T2,因此T2需要等到T1事务结束后才能读数据。
因为
T2需要等待T1结束后才能读,既然T1都结束了,那也就代表着T1事务要么回滚了,T2读上一个事务提交的数据;要么T1提交了,T2读T1提交的数据,总之T2读到的数据绝对是提交过的数据。
这种方式的确能解决脏读问题,但似乎也会将所有并发事务串行化,会导致MySQL整体性能下降,因此MySQL引入了一种技术,也就是MVCC机制,在每次select查询数据时,都会生成一个ReadView快照,然后依据这个快照去选择一个可读的数据版本。
因此对于
RC级别的底层实现,对于写操作会加排他锁,而读操作会使用MVCC机制。
但由于每次select时都会生成ReadView快照,此时就会出现下述问题:
-- ①T1事务中先读取一次 ID=1 的数据
SELECT * FROM `zz_users` WHERE user_id = 1;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
+---------+-----------+----------+----------+---------------------+
-- ②T2事务中修改 ID=1 的姓名为 竹子 并提交
UPDATE `zz_users` SET user_name = "竹子" WHERE user_id = 1;
commit;
-- ③T1事务中再读取一次 ID=1 的数据
SELECT * FROM `zz_users` WHERE user_id = 1;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 竹子 | 女 | 6666 | 2022-08-14 15:22:01 |
+---------+-----------+----------+----------+---------------------+此时观察这个案例,明明是在一个事务中查询同一条数据,结果两次查询的结果并不一致,这也是所谓的不可重复读的问题。
3.3、RR(Repeatable Read)可重复读级别的实现
在RC级别中,虽然解决了脏读问题,但依旧存在不可重复读问题,而RR级别中,就是要确保一个事务中的多次读取结果一致,即解决不可重复读问题。两种方案:
-
①查询时,对目标数据加上临键锁,即读操作执行时,不允许其他事务改动数据。
-
②
MVCC机制的优化版:一个事务中只生成一次ReadView快照。
相较于第一种方案,第二种方案显然性能会更好,因为第一种方案不允许读-写、写-读事务共存,而第二种方案则支持读写事务并行执行。其实也比较简单:
写操作加排他锁,对读操作依旧采用
MVCC机制,但RR级别中,一个事务中只有首次select会生成ReadView快照。
-- ①T1事务中先读取一次 ID=1 的数据
SELECT * FROM `zz_users` WHERE user_id = 1;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
+---------+-----------+----------+----------+---------------------+
-- ②T2事务中修改 ID=1 的姓名为 竹子 并提交
UPDATE `zz_users` SET user_name = "竹子" WHERE user_id = 1;
commit;
-- ③T1事务中再读取一次 ID=1 的数据
SELECT * FROM `zz_users` WHERE user_id = 1;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 竹子 | 女 | 6666 | 2022-08-14 15:22:01 |
+---------+-----------+----------+----------+---------------------+还是以这个场景为例,在RC级别中,会对于T1事务的每次SELECT都生成快照,因此当T1第二次查询时,生成的快照中就能看到T2修改后提交的数据。但在RR级别中,只有首次SELECT会生成快照,当第二次SELECT操作出现时,依旧会基于第一次生成的快照查询,所以就能确保同一个事务中,每次看到的数据都是相同的。
也正是由于
RR级别中,一个事务仅有首次select会生成快照,所以不仅仅解决了不可重复读问题,还解决了幻读问题,举个例子:
-- 先查询一次用户表,看看整张表的数据
SELECT * FROM `zz_users`;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
| 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 |
| 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 |
| 4 | 猫熊 | 女 | 8888 | 2022-09-27 17:22:59 |
| 9 | 黑竹 | 男 | 9999 | 2022-09-28 22:31:44 |
+---------+-----------+----------+----------+---------------------+
-- ①T1事务中,先查询所有 ID>=4 的用户信息
SELECT * FROM `zz_users` WHERE user_id >= 4;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 4 | 猫熊 | 女 | 8888 | 2022-09-27 17:22:59 |
| 9 | 黑竹 | 男 | 9999 | 2022-09-28 22:31:44 |
+---------+-----------+----------+----------+---------------------+
-- ②T1事务中,再将所有 ID>=4 的用户密码重置为 1111
UPDATE `zz_users` SET password = "1111" WHERE user_id >= 4;
-- ③T2事务中,插入一条 ID=6 的用户数据
INSERT INTO `zz_users` VALUES(6,"棕熊","男","7777","2022-10-02 16:21:33");
-- ④提交事务T2
commit;
-- ⑤T1事务中,再次查询所有 ID>=4 的用户信息
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 4 | 猫熊 | 女 | 1111 | 2022-09-27 17:22:59 |
| 6 | 棕熊 | 男 | 7777 | 2022-10-02 16:21:33 |
| 9 | 黑竹 | 男 | 1111 | 2022-09-28 22:31:44 |
+---------+-----------+----------+----------+---------------------+此时会发现,明明T1中已经将所有ID>=4的用户密码重置为1111了,结果改完再次查询会发现,表中依旧存在一条ID>=4的数据:棕熊,而且密码未被重置,这似乎产生了幻觉一样。
如果是
RC级别,因为每次select都会生成快照,因此会出现这个幻读问题,但RR级别中因为只有首次查询会生成ReadView快照,因此上述案例放在RR级别的MySQL中,T1看不到T2新增的数据,因此MySQL-RR级别也解决了幻读问题。
MVCC机制是否彻底解决了幻读问题呢?
先上定论,MVCC并没有彻底解决幻读问题,在一种奇葩的情况下依旧会出现问题,先来看例子:
-- 开启一个事务T1
begin;
-- 查询表中 ID>10 的数据
SELECT * FROM `zz_users` where user_id > 10;
Empty set (0.01 sec)因为用户表中不存在ID>10的数据,所以T1查询时没有结果,再继续往下看。
-- 再开启一个事务T2
begin;
-- 向表中插入一条 ID=11 的数据
INSERT INTO `zz_users` VALUES(11,"墨竹","男","2222","2022-10-07 23:24:36");
-- 提交事务T2
commit;此时T2事务插入一条ID=11的数据并提交,此时再回到T1事务中:
-- 在T1事务中,再次查询表中 ID>10 的数据
SELECT * FROM `zz_users` where user_id > 10;
Empty set (0.01 sec)结果很明显,依旧未查询到ID>10的数据,因为这里是通过第一次生成的快照文件在读,所以读不到T2新增的“幻影数据”。接着往下看:
-- 在T1事务中,对 ID=11 的数据进行修改
UPDATE `zz_users` SET `password` = "1111" where `user_id` = 11;
-- 在T1事务中,再次查询表中 ID>10 的数据
SELECT * FROM `zz_users` where user_id > 10;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 11 | 墨竹 | 男 | 1111 | 2022-10-07 23:24:36 |
+---------+-----------+----------+----------+---------------------+此时会发现,T1事务中又能查询到ID=11的这条幻影记录了,这是啥原因导致的呢?因为我们在T1中修改了ID=11的数据,在MVCC机制原理中MVCC通过快照检索数据的过程,这里T1根据原本的快照文件检索数据时,因为发现ID=11这条数据上的隐藏列trx_id是自己,因此就能看到这条幻影数据了。
但如若你实在不放心,想要彻底杜绝任何风险的出现,那就直接将事务隔离级别调整到Serializable即可。
3.4、Serializable序列化级别的实现
前面已经将RU、RC、RR三个级别的实现原理弄懂了,最后再来看看最高的Serializable级别,在这个级别中,要求解决所有可能会因并发事务引发的问题。比较简单:
所有写操作加临键锁(具备互斥特性),所有读操作加共享锁。
由于所有写操作在执行时,都会获取临键锁,所以写-写、读-写、写-读这类并发场景都会互斥,而由于读操作加的是共享锁,因此在Serializable级别中,只有读-读场景可以并发执行。
四、事务与锁机制原理篇总结
-
RU级别:读操作不加锁,写操作加排他锁。
-
RC级别:读操作使用
MVCC机制,每次SELECT生成快照,写操作加排他锁。 -
RR级别:读操作使用
MVCC机制,首次SELECT生成快照,写操作加临键锁。 -
序列化级别:读操作加共享锁,写操作加临键锁。
| 级别/场景 | 读-读 | 读-写/写-读 | 写-写 |
| RU级别 | 并行执行 | 并行执行 | 串行执行 |
| RC级别 | 并行执行 | 并行执行 | 串行执行 |
| RR级别 | 并行执行 | 并行执行 | 串行执行 |
| 序列化级别 | 并行执行 | 串行执行 | 串行执行 |
MySQL内存实现原理剖析
一、MySQL内存结构
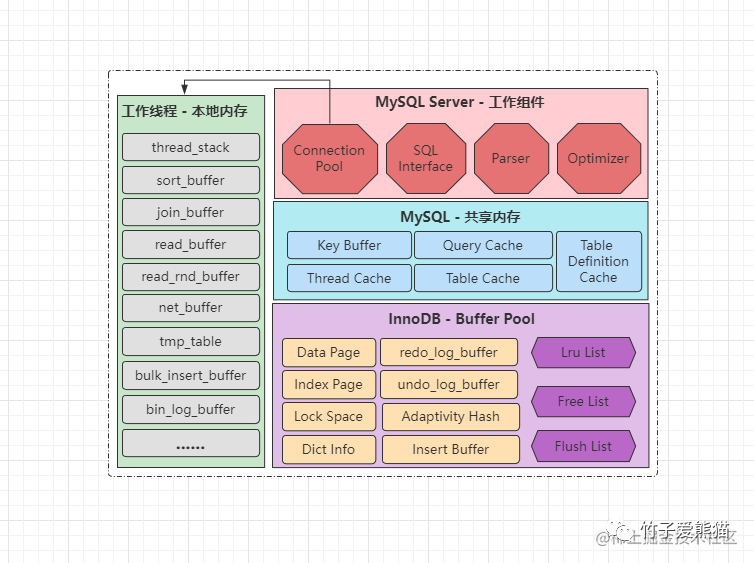
注意观察,实际MySQL启动后内存结构略显复杂,但大体可分为MySQL工作组件、线程本地内存、MySQL共享内存、存储引擎缓冲区四大板块。
实际上
MySQL内存模型和JVM类似,JVM内存主要会划分为线程共享区和线程私有区,而上图中的MySQL内存区域,左边则是线程私有区域,每条工作线程中都会分配的区域,各线程之间互不影响,而右边的三大板块,则属于线程共享区域,即所有线程都可访问的内存。
当然,线程共享区这块也会细分,右边上面的两个板块,都属于MySQL-Server层使用的内存,也就意味着这两块内存是所有引擎都共享的区域,而最下面这个区域,每个存储引擎都不相同,也就是InnoDB会构建自己的Buffer缓冲区,MyISAM也会构建自己的缓冲区。
1.1、MySQL Server - 工作组件
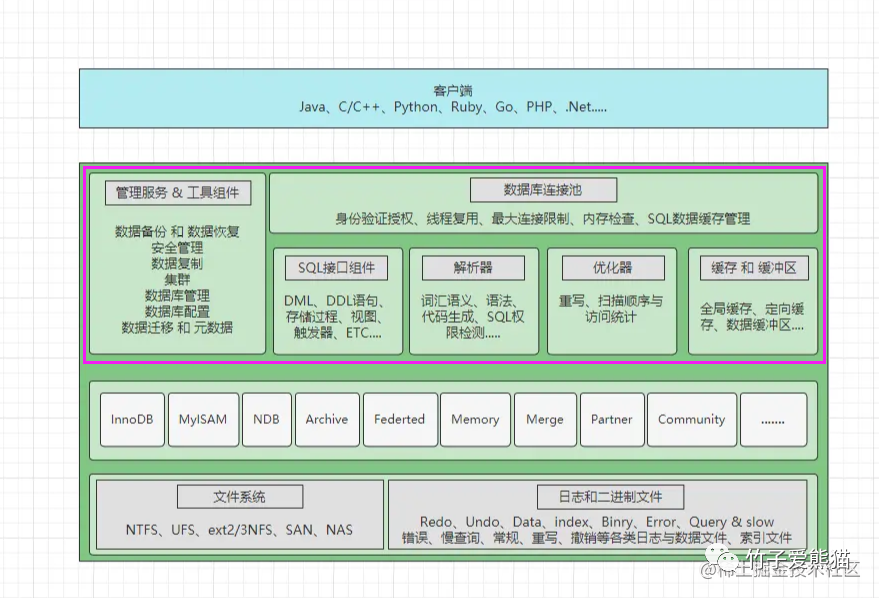
因为后续客户端连接时,都需要经过一系列的连接工作,处理SQL时也需要经过一系列的解析、验证、优化工作,所以MySQL会在启动时,会先将这些工作组件初始化到内存中,方便后续处理客户端的操作。
数据库的连接池中,存的到底是什么?存的实际上就是数据库连接对象,MySQL内部的连接对象,其中包含了客户端连接信息,如客户端IP、登录的用户、所连接的DB....等这类信息,同时这些连接对象在内部会绑定一条工作线程,因此你也可以将它理解成是一个线程池。MySQL复用连接的本质,实则是在复用线程,出现一个新的客户端连接时,首先会根据客户端信息为其创建连接对象,然后再复用连接池中的空闲线程。
1.2、工作线程的本地内存
工作线程的本地内存区域,也被称之为线程私有区,即MySQL在创建每条线程时,都会为其分配这些内存:
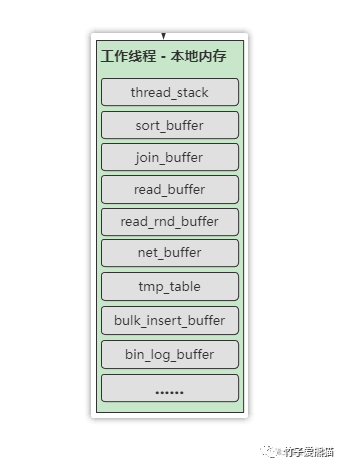
工作线程-本地内存,简单的说明一下其中每个区域的含义:
-
thread_stack:线程堆栈,主要用于暂时存储运行的SQL语句及运算数据,和Java虚拟机栈类似。 -
sort_buffer:排序缓冲区,执行排序SQL时,用于存放排序后数据的临时缓冲区。 -
join_buffer:连接缓冲区,做连表查询时,存放符合连表查询条件的数据临时缓冲区。 -
read_buffer:顺序读缓冲区,MySQL磁盘IO一次读一页数据,这个是顺序IO的数据临时缓冲区。 -
read_rnd_buffer:随机读缓冲区,当基于无序字段查询数据时,这里存放随机读到的数据。 -
net_buffer:网络连接缓冲区,这里主要是存放当前线程对应的客户端连接信息。 -
tmp_table:内存临时表,当SQL中用到了临时表时,这里存放临时表的结构及数据。 -
bulk_insert_buffer:MyISAM批量插入缓冲区,批量insert时,存放临时数据的缓冲区。 -
bin_log_buffer:bin-log日志缓冲区,bin-log的缓冲区被设计在工作线程的本地内存中。
可以看到,在工作线程的本地内存中,除开最基本的线程堆栈外,MySQL还往内部“塞了”一堆东西,这些东西在不同的SQL运行时,都有各自的作用,但基本上是为了更好的保存临时数据而设计的。
思考一个问题:对于上面列出的各类缓冲区,为什么要为每条线程都分配专属的内存,而不是直接在共享内存中搞一块大的空间,然后提供给所有线程来操作呢?其实答案很简单,因为这些数据本身就是一条线程在执行
SQL时产生的临时数据,其他线程压根不会去用到另一条线程的临时数据,所以这些临时数据没有必要被共享。
除开上述原因外,将这些缓冲区都放在线程本地内存中,还有一点最大的好处:能够提升多线程并发执行的性能。如果把上述的各个缓冲区放在共享内存中,然后提供给线程存放执行时的临时数据,因为多线程的缘故,所以同一时刻、同一快内存有可能出现多条线程一起操作,那就会出现线程不安全的问题,想要解决就只能加锁将多线程串行化,这自然会在很大程度上影响性能,因此将这些存临时数据的缓冲区,设计在本地内存中才最合适。
不过也并非所有数据都适合放在线程的本地内存中,有一些多条线程之间都会访问的数据,如果再放到本地内存中,就会造成很大的冗余性,比如典型的索引根节点数据,每条线程都有可能会通过索引查询数据,因此每条线程都“缓存”一份放在自己的内存中,就会占用大量的内存空间,这样反而弊大于利。
1.3、MySQL共享内存区
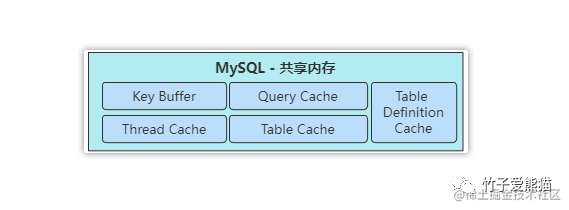
先简单介绍一下上述给出的几个内容:
-
Key Buffer:MyISAM表的索引缓冲区,提升MyISAM表的索引读写速度。 -
Query Cache:查询缓存区,缓冲SQL的查询结果,提升热点SQL的数据检索效率。 -
Thread Cache:线程缓存区,存放工作线程运行期间,一些需要被共享的临时数据。 -
Table Cache:表数据文件的文件描述符缓存,提升数据表的打开效率。 -
Table Definition Cache:表结构文件的文件描述符缓存,提升结构表的打开效率。
上面的这几个线程共享区域还比较容易理解,对于最后两个文件描述符缓存,大家可能存在些许疑惑,这里可以先看一下《FD-文件描述符的定义》,文件描述符本质上就是一个指针,指向一个具体的数据。这里为何要在内存中存放表数据文件、表结构文件的FD缓存呢?主要是为了提升性能,先来看一个问题:
比如我现在想要操作
zz_users表的数据,那首先是不是得找到这张表?但表的位置可能分布在磁盘的任何一处,总不能触发磁盘IO把整个磁盘检索一遍,然后确定表的位置吧?所以内存中直接设计了一个缓存区,专门缓存这些表数据文件的磁盘位置,要对某张表进行操作时,直接去文件描述符缓存中找,然后根据其中记录的地址,去磁盘中固定的位置上操作表数据。
表结构的文件描述符缓存,作用也是相同的,比如现在要增加一个索引,或者修改一个字段,也不会把磁盘全部扫描一遍,而是直接根据内存中的文件描述符,去操作磁盘中对应位置的表结构文件。
但是这两个文件描述符缓存,更多的是为MyISAM引擎设计的。
1.3.1、MySQL8.x为什么移除了查询缓存?
再简单聊一下QueryCahce查询缓存,这块的设计思想是非常好的,也就是利用热点探测技术,对于一些频繁执行的查询SQL,直接将结果缓存在内存中,之后再次来查询相同数据时,就无需走磁盘,而是直接从查询缓存中获取数据并返回。
select * from zz_users where user_id=1;
select * from zz_users where user_id = 1;比如上述这两条SQL语句,都是在查询ID=1的用户数据,MySQL的查询缓存会把它当做两条不同的SQL,也就是假如上面的第一条SQL,其查询结果被放入到了缓存中,第二条SQL依旧无法命中这个缓存,会继续走表查询的形式获取数据。
因为
MySQL查询缓存是以SQL的哈希值来作为Key的,上面两条SQL虽然一样,但是后面的查询条件有细微差别:user_id=1、user_id = 1,也就是一条SQL有空格,一条没有。
由于这一点点细微差异,会导致两条SQL计算出的哈希值完全不同,因此无法命中缓存,是不是很鸡肋?还有多种情况:user_id =1、user_id= 1,空格处于的前后位置不同,也会导致缓存失效。
也正是由于方方面面的原因,所以查询缓存在
MySQL8.0中被完全舍弃了,即移除掉了查询缓存区,各方面原因如下:
-
①缓存命中率低:几乎大部分
SQL都无法从查询缓存中获得数据。 -
②占用内存高:将大量查询结果放入到内存中,会占用至少几百
MB的内存。 -
③增加查询步骤:查询表之前会先查一次缓存,查询后会将结果放入缓存,额外多几步开销。
-
④缓存维护成本不小,需要
LRU算法淘汰缓存,同时每次更新、插入、删除数据时,都要清空缓存中对应的数据。 -
⑤
InnoDB引擎构建出的缓冲区中,也会类似的功能,因为与查询缓存也存在冲突。
因为上述一系列原因,再加上项目中一般都会使用Redis先做业务缓存,因此能来到MySQL的查询语句,几乎都是要从表中读数据的,所以查询缓存的地位就显得更加突兀,因此在高版本中就直接去掉了,毕竟弊大于利,带来的收益达不到设计时的预期。
1.4、存储引擎缓冲区
几乎任何存储引擎都会在启动时,向操作系统申请一块内存,用来作为缓冲区,每个引擎的缓冲区也并不相同,但有一点是共通的:即所有引擎的缓冲区,对于MySQL的工作线程而言,都是一块共享的内存区域。
现如今,MySQL众多存储引擎中,应用最为广泛的是InnoDB,所以我们就以InnoDB-Buffer Pool为例,可将其称之为「写入缓冲」,但要记住:BufferPool不仅仅只扮演「写入缓冲」的角色,其中主要包含了如下内容:
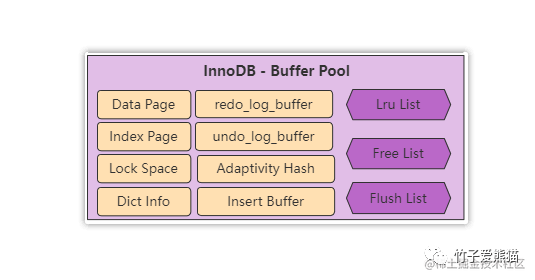
同样先简单介绍一下其中每个区域的作用:
-
Data Page:写入缓冲区,主要用来缓冲磁盘的表数据,将写操作转移到内存进行。 -
Index Page:索引缓冲页,对于所有已创建的索引根节点,都会放入到内存,提升索引效率。 -
Lock Space:锁空间,主要是存放所有创建出的锁对象。 -
Dict Info:数据字典,主要用来存储MySQL-InnoDB引擎自带的系统表。 -
redo_log_buffer:redo-log缓冲区,存放写SQL执行时写入的redo记录。 -
undo_log_buffer:undo-log缓冲区,存放写SQL执行时写入的undo记录。 -
Adaptivity Hash:自适应哈希索引,InnoDB会为热点索引页,创建相应的哈希索引。 -
Insert Buffer:写入缓冲区,对于insert的数据,会先放在这里,然后定期刷写磁盘。 -
Lru List:内存淘汰页列表,对于整个缓冲池的内存管理列表。 -
Free List:空闲内存列表,这里面记录着目前未被使用的内存页。 -
Flush List:脏页内存列表,这里主要记录未落盘的数据。
虽然
MySQL是基于磁盘存储数据的,但总不能每次读写操作都走磁盘吧?这样绝对会导致资源开销极大,同时性能也极低,因此各引擎都在内存中设计了一个缓冲池,用来提升数据库整体的读写性能。
而InnoDB引擎,是尤为特殊的存在,几乎将所有的操作都放在了内存中完成,因此慢慢的,InnoDB代替了MyISAM,成为了MySQL默认的存储引擎,不过还有其他方面的因素导致的。
二、InnoDB的核心 - Buffer Pool
InnoDB引擎几乎将所有操作都放在了内存中完成,这句话主要是跟它的Buffer Pool有关,但Buffer Pool到底会占用多大内存呢?这点可以通过show global variables like "%innodb_buffer_pool_size%";指令查询,如下:
show global variables like "%innodb_buffer_pool_size%";
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| innodb_buffer_pool_size | 44040192 |
+-------------------------+----------+
1 row in set (0.06 sec)在MySQL5.6版本以下,默认大小为42MB,而MySQL5.6以后的版本中,默认大小为128MB,这块内存是MySQL启动时向OS申请的一块连续空间。当然,我们也可以手动调整innodb_buffer_pool_size参数来控制,一般建议设置为机器内存的60~80%。
接下来咱们先把Buffer Pool中每个区域的具体作用说明白,也就是这张图:
2.1、数据页(Data Page)
InnoDB引擎为了方便读取,会将磁盘中的数据划分为一个个的「页」,每个页的默认大小为16KB,以页作为内存和磁盘交互的基本单位,而InnoDB的缓冲池也会以页作为单位,也就意味着:当InnoDB拿到申请的连续内存后,会按照16KB的尺寸将整块空间,划分成一个个的缓冲页。
在
MySQL运行之初,这些划分出的缓冲页,都属于空闲页,也就是未使用的内存,随着运行时长的慢慢增长,会将磁盘中的数据页,一点点的载入内存当中,因为磁盘中的表数据是以16KB作为单位划分的,而内存中的缓冲页也是这个大小,因此发生一次磁盘IO读到的数据(读一页磁盘数据),会放入到一个缓冲页中存储,而这些承载磁盘数据的缓冲页,就被称之为数据页,其过程如下:
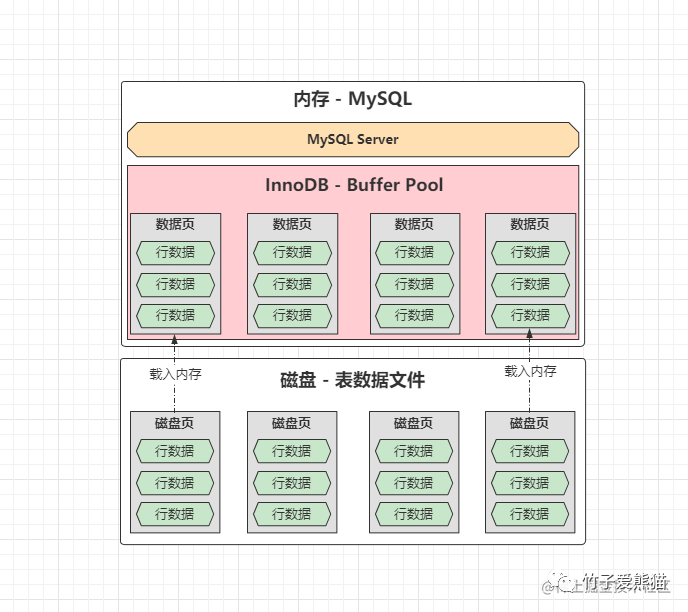
当磁盘中的数据被载入到内存之后,带来的优势会极为明显:
-
读数据时:如果在数据页中有,则直接会从内存中读取数据并返回,没有再去磁盘检索数据。
-
写数据时:会先修改数据页的数据,修改后会标记相应的数据页,然后直接返回,再由后台线程去完成数据的落盘工作。
此时有没有发现:InnoDB的缓冲池,其实也具备「查询缓存」的功能~
不过
MySQL会将哪些表数据放到缓冲池中呢?其实刚启动时里面并不会有数据,而是随着业务SQL的执行,一点点将磁盘中的数据加载进内存的,比如执行一条查询语句,因为最初内存中并没有加载数据页,因此会走磁盘检索数据,检索数据的过程中,不管此次IO读到的数据是不是目标数据,都会将它们放在内存中,而不是直接回收。
观察上述这个过程,这样做有什么好处呢?方便后续其他SQL要操作对应数据时,可以直接在内存中读到数据。
在条件允许,即内存充足的情况下,
InnoDB会试图将磁盘中的所有表数据全部载入内存。
不过一般的机器,磁盘空间都会比内存要大出很多倍,所以当表数据较大时,也不可能无限制的载入,因而InnoDB会有一套完善的内存管理与淘汰机制,以此防止内存溢出风险(对于这点后续再详细阐述)。
2.2、索引缓冲页(Index Page)
上面讲到了,InnoDB会将部分乃至所有表数据载入内存,以此达到提升性能的目的,但不可能无限制载入,比如现在机器的内存为16GB,但磁盘中有30GB表数据,这显然无法放入进内存,所以无可避免的一点:在运行过程中,MySQL会走磁盘读数据。
比如一条查询语句要读的数据,在内存中没有相关的缓冲数据页,因此需要触发磁盘
IO检索数据,但此时这条SQL可以命中索引,那会通过索引去查找数据,但问题来了。索引的根节点可能位于磁盘的任意位置,难道把磁盘的所有位置全部走一遍吗?这显然并不现实,所以InnoDB也会有对应的优化机制,即内存中也会缓冲索引页。
在MySQL启动时,就会将当前库中所有已存在的索引,其根节点放入到内存缓冲区中,因为索引的根节点只有16KB,因此就算目前库中就算创建了1000个索引,所有索引的根节点加起来占用的内存空间,也不过才15MB左右。将索引的根节点载入内存后,对于需要走索引查询的SQL,就会直接以相应的索引根节点为起始,然后去走索引查找数据,这样就避免了全盘查找索引根节点的这步操作。
Buffer Pool中有一块专门的区域:Index Page,专门用来存放载入的索引数据,存储这些数据的缓冲页,则被称之为索引页。随着运行时间的增长,也会将一些非根节点的索引页载入内存中,这是一种对于访问频率较高的索引页,专门推出的优化机制。
2.3、锁空间(Lock Space)
对于锁空间,锁机制的实现原理,聊到过锁是基于事务实现,每个事务会生成自己的锁结构,而这些锁结构也同样需要空间来存储,而锁空间就是专门用来存储锁结构的一块内存区域。
但锁空间也不仅仅只会存储锁结构,还会存储一些并发事务的链表,例如死锁检测时需要的「事务等待链表、锁的信息链表」等。
锁空间一般都是有大小限制的,当锁空间内存不足时,就会导致行锁粗化成表锁,以此来减少锁结构的数量,释放一定程度上的内存,但此时并发冲突就会变高。
2.4、数据字典(Dict Info)
对于数据字典估计大家很少有人接触过,毕竟这个是用来辅助InnoDB运行用的,咱们先思考一个问题,为啥我们可以通过SQL语句查询到库中的表信息、查询一张表的索引、约束等信息呢?如下:
-- 查询当前库中的所有表
show tables;
-- 查询一张表的全部索引
show index from `tableName`;这些语句执行后都能查询出对应的信息,但这些信息咋来的呢?这首先跟MySQL的系统表有关,在InnoDB引擎中主要存在SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS这四张系统表,主要是用来维护用户定义的所有表的各种信息,如下:
-
SYS_TABLES:这张表中会存储所有引擎为InnoDB的表信息。-
ID:一张表的ID号。 -
NAME:一张表的名称。 -
N_COLS:一张表的字段数量。 -
TYPE:一张表所使用的存储引擎、编码格式、压缩算法、排序规则等。 -
SPACE:一张表所位于的表空间。
-
-
SYS_COLUMNS:这张表用来存储所有用户定义的表字段信息。-
TABLE_ID:表示一个字段属于那张表。 -
POS:一个字段在一张表中属于第几列。 -
NAME:一个字段的名称。 -
MTYPE:一个字段的数据类型。 -
PRTYPE:一个字段的精度值。 -
LEN:一个字段的存储长度限制。
-
-
SYS_INDEXES:这张表用来存储所有InnoDB引擎表的索引信息。-
TABLE_ID:表示这个索引属于哪张表。 -
ID:一个索引的ID号。 -
NAME:一个索引的名称。 -
N_FIELDS:一个索引由几个字段组成。 -
TYPE:一个索引的类型,如唯一、联合、全文、主键索引等。 -
SPACE:一个索引的数据所位于的表空间位置。 -
PAGE_NO:这个索引对应的B+Tree根节点位置。
-
-
SYS_FIELDS:这张表用来存储所有索引的定义信息。-
INDEX_ID:当前这个索引字段属于哪个索引。 -
POS:当前这个索引字段,位于索引的第几列。 -
COL_NAME:当前索引字段的名称。
-
这四张表也被称为InnoDB的内部表,这四张表在载入内存前,位于.ibdata文件中,在MySQL启动时会开始加载,载入内存后就会放入到Dict Info这块区域,当利用show语句查询表的结构信息时,就会在字典信息中检索数据。
2.5、日志缓冲区(Log Buffer)
InnoDB的缓冲池中,主要存在两个日志缓冲区,即undo_log_buffer、redo_log_buffer,分别对应着撤销日志和重做日志,它俩的作用主要是用来提升日志记录的写入速度,因为日志文件在磁盘中,执行SQL时直接往磁盘写日志,其效率太低了,因此会先写缓冲区,再由后台线程去刷写日志。
2.6、自适应哈希索引(Adaptivity Hash)
自适应哈希索引又是一个比较有趣的技术点,这种技术可以算的上是一种AI技术,哈希算法查找数据的效率非常高,在没有哈希冲突的情况下复杂度为O(1),而B+Tree检索数据的效率,取决于树的高度。建立索引时,只能选用一种数据结构来作为索引的底层结构:
-
如果选择哈希结构,虽然效率高,但数据是无序的,因此不方便做排序查询。
-
如果选择
B+Tree结构,虽然有序,但查询的效率会受到树高的影响。
两种结构各有优劣,但一般为了满足业务按序查询的需求,所以会折中选择B+Tree结构,虽然没有哈希索引那么快,但速度也还可以。
而正是由于此原因,InnoDB创始人在研发时,就实现了一种名为自适应哈希索引的技术,在MySQL运行过程中,InnoDB引擎会对表上的索引做监控,如果某些数据经常走索引查询,那InnoDB就会为其建立一个哈希索引,以此来提升数据检索的效率,并且减少走B+Tree带来的开销,由于这种哈希索引是运行过程中,InnoDB根据B+Tree的索引查询次数来建立的,因此被称之为自适应哈希索引。
自适应哈希索引和普通哈希索引的区别在哪儿呢?普通哈希索引是在创建索引时将结构声明为
Hash结构,这种索引会以索引字段的整表数据建立哈希,而自适应哈希索引是根据缓冲池的B+树构造而来,只会基于热点数据构建,因此建立的速度会非常快,毕竟无需对整表都建立哈希索引。
自适应哈希索引在InnoDB中是默认开启的,可以通过手动调整innodb_adaptive_hash_index参数来控制关闭,但一般尽量不要去关闭它,因为该技术能让MySQL的整体性能翻倍。
在
MySQL8.0以下的版本中,如果同时删除一张大表的很多数据,有可能会因为自适应哈希索引的原因,造成线上MySQL出现抖动,不过该问题在MySQL8.x版本中已经被修复,但如若你的MySQL版本在此之下,那尽量不要在业务高峰期删除大量数据。
对于自适应哈希索引的使用情况,可以通过show engine innodb status \G;命令查看,但哈希索引由于自身特性的原因,因此也仅只能用于等值查询的场景,无法支持排序、范围查询。
2.7、写入缓冲区(Insert Buffer)
「Change Buufer写入缓冲」属于InnoDB的一大特性,其实「写入缓冲」在一开始被称之为「Insert Buffer插入缓冲」,也就是只对insert操作生效,到了MySQL5.5之后的版本中,才正式改为「写入缓冲」,对于insert、delete、update语句都可生效。
结合前面聊过的「数据缓冲页」,如果要变更的数据页在缓冲区中存在,则会直接修改缓冲区中的数据页,然后标记一下变更过的数据页,但如果要操作的数据页并未被加载到缓冲区,那依旧会走磁盘去操作数据,走磁盘显然会影响性能,因此InnoDB就创造了一个「写入缓冲」。
以
insert语句为例,不管在MySQL的任何版本中,执行一条插入语句之前,因为这条数据在磁盘中都不存在,因此缓冲区中自然也不可能会有对应的数据页,按照前面的说法,似乎必须走磁盘插入数据了对不?
「写入缓冲」出现的原因,就是为了解决此问题,当一条写入语句执行时,流程如下:
-
①判断要变更的数据页是否被载入到内存。
-
②如果内存中有对应的数据页,则直接变更缓冲区中的数据页,完成标记后则直接返回。
-
③如果内存中没有对应的数据页,则将要变更的数据放入到「写入缓冲」中,然后返回。
此时会发现,不管内存中是否存在相应的数据页,InnoDB都不会走磁盘写数据,而是直接在内存中完成所有操作,但是要注意:并不是所有的写入动作,都可以在内存中完成,「写入缓冲」是有限制的,如下:
-
插入的数据字段不能具备唯一约束或唯一索引。
因为如果存在唯一字段的表,在插入数据前必须要先判断表中是否存在相同值,一张表的数据不可能全部都载入数据,所以这个判断重复值的工作必须依赖磁盘中的表数据来完成,所以插入具备唯一性的数据时,就必须要走磁盘。
表中会有一个主键,默认会存在一个主键索引,主键索引也是一种特殊的唯一索引,那不就意味着所有具备主键的表,都不能通过「写入缓冲」来插入数据呀?这点不一定,如果表的主键声明了是一个自增
ID,那这个自增序列会由MySQL-Server自己来维护,因此ID会由MySQL来生成,是绝对不会出现重复值的,因此对于这种情况,会将要插入的数据放到「写入缓冲区」中。
那如果表中存在唯一索引、或者表的主键未声明是自增ID,难道插入数据时就不会用到这个「写入缓冲区」吗?答案是NO,依旧会用。一条插入语句的执行过程如下:
-
①先向聚簇索引中,插入一条相应的行记录(数据)。
-
②对于非聚簇索引,都插入一个新的索引键,并将值指向聚簇索引中插入的主键值。
发现没有?插入数据时还需额外维护表中的次级索引,会为插入的新数据构建次级索引的索引键,并且将索引键插入到次级索引树当中,而这个过程就会用到「写入缓冲区」。
因为首先需要走一次磁盘,先插入行记录,插入完成后,假设表中存在三个非聚簇索引(次级索引),那难道再写三次磁盘维护次级索引吗?
NO,对于不具备唯一性的索引,都会将要插入的索引键放在「写入缓冲区」。
对于修改、删除语句的执行,也是同理,那「写入缓冲区」中的数据究竟啥时候会真正写入到磁盘呢?
-
当一条
SQL需要用到对应的索引键查询数据时,会触发后台线程执行刷盘工作。 -
当「写入缓冲区」内存空间不足时,会触发后台线程执行刷盘工作。
-
当距离上一次刷盘的时间,间隔达到一定程度(默认
10s),会触发后台线程执行刷盘工作。 -
MySQL-Server正在关闭时,也会触发后台线程执行刷盘工作。
上述这四种情况,都会导致后台线程执行刷盘工作,从而将数据真正的落入磁盘中存储。
三、InnoDB缓冲池的内存是如何管理的?
InnoDB虽然在启动时,会将连续的内存划分为一块块的缓冲页,但这仅是逻辑上的划分,本质上所有的缓冲页之间,也是连续的内存。但随着MySQL在线上运行的时间越来越长,自然会导致这片连续的缓冲页变得七零八落,如下:
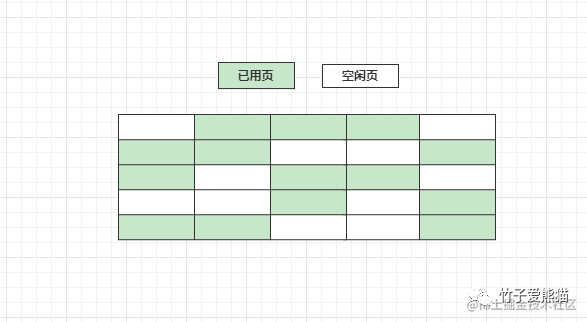
当从磁盘加载一个数据页时,总不能将所有的缓冲页全部遍历一次,然后找到其中的空闲页放数据吧?这样难免有些影响性能,所以为了更好的管理缓冲池,InnoDB会为每个缓冲页创建一个控制块。
3.1、缓冲页的控制块
控制块是专门用于管理缓冲页而设计的一种结构,其中会包含:数据页所属的表空间、页号、缓冲页地址、链表节点指针等信息,所有的控制块都会放在缓冲池最前面,如下:
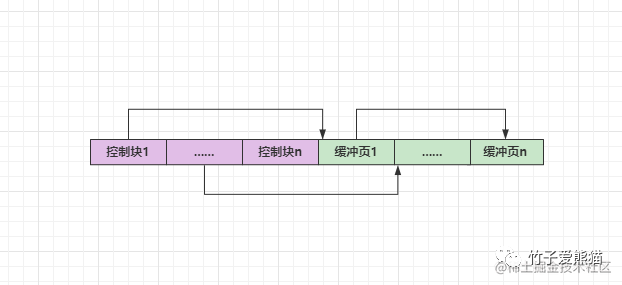
当然,控制块也会占用缓冲池的内存空间,InnoDB会为每一个缓冲页都分配一个对应的控制块,后续InnoDB可以基于控制块去管理每一块缓冲页。
3.2、空闲页的管理
首先来聊聊对于空闲缓冲页的管理,为了能够更快的找到缓冲池中的空闲页,InnoDB会以控制块作为节点,将所有空闲的缓冲页组成一个空闲链表,也就是之前的Free链表,示意图如下:
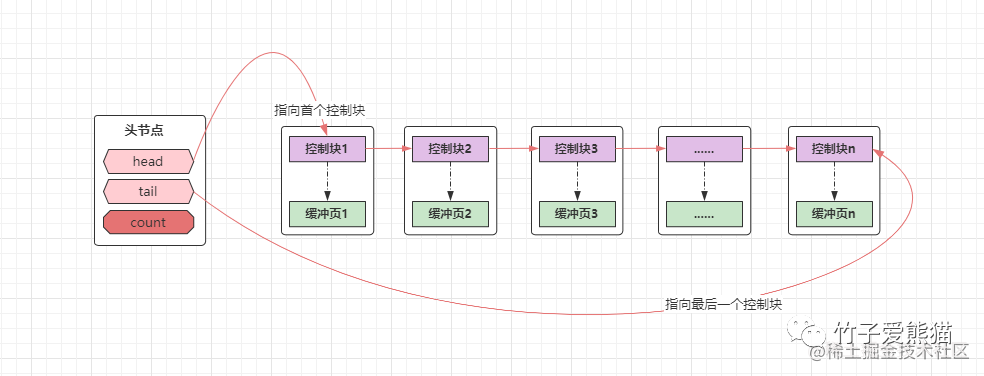
因为控制块对应着一个个的缓冲页,以控制块作为链表节点,也就等价于是由缓冲页组成的链表,在链表中会存在一个头结点,内部主要有三个值:
-
head:这是一根指针,指向空闲链表的第一个控制块。 -
tail:同样是一根指针,指向空闲链表的最后一个控制块。 -
count:这是一个数字,用来记录空闲链表的节点数量。
有了空闲链表后,会有什么好处呢?十分明显,当需要一块新的缓冲页存储磁盘数据时,不需要再去遍历所有缓冲页找一块空闲的出来了,而是直接找到空闲链表,根据空闲链表的指针,从中拿一块空闲缓冲页使用即可。
3.3、标记页的管理
当线程变更了内存中的数据页之后,会先对这个数据页做个标记,然后直接给客户端返回「执行成功」的响应。在这个过程中,被线程变更并标记过的数据页,则被称之为标记页,不过在有些地方也被称之为“脏页”。
对于内存中变更过的数据页,最终绝对是需要刷写到磁盘中的,这个工作会由
MySQL的后台线程完成,但问题又来了:当后台线程要刷盘时,它咋知道哪些数据页是变更过的呢?
有人也许会说,前面工作线程在执行完SQL之后,不是对数据页做了标记嘛?确实没错,但问题在于:缓冲池中的缓冲页那么多,后台线程难道去把所有缓冲页全部找一次,看看它有没有被标记嘛?
这样做确实可以,但还不够,因为每次刷盘都需遍历所有缓冲页,其过程的开销必然不小,比如刷盘时,缓冲池中就只有几个数据页发生了变更,为了刷写这几个页的数据就找一次所有页,这有点用迫击炮打鸟的意思。
因此为了后台线程刷盘时效率更高,InnoDB同样又创造了一个Flush链表,它的结构和Free链表一模一样,因此就不再画图了,两者的不同点在于:
-
Free链表:记录空闲缓冲页,为了使用时能更快的找到空闲缓冲页。 -
Flush链表:记录标记过的缓冲页,为了刷盘时能够更快的找到变更数据页。
当后台线程开始刷盘工作时,会直接找到Flush链表,然后直接将该链表中对应的缓冲页,其变更过的数据刷写到磁盘。
注意:标记页的刷盘时机与「写入缓冲」的刷盘时机相同,也包括「写入缓冲」也归属在
Buffer Pool中,因此当「写入缓冲区」中有数据需要刷盘时,相应的缓冲页,同样会被加入Flush链表。
3.4、内存中的数据页是如何淘汰的?
Buffer Pool的内存空间是有限的,因此无法支撑所有数据源源不断的载入内存,所以InnoDB内部绝对有一套自己的淘汰机制,但先设想一个问题:所有数据都可以被淘汰吗?可以是可以,毕竟就算内存中的数据没了,磁盘中也会有数据,但是随机淘汰显然并不妥,我们希望做到是:那些频繁被访问的数据页可以长期驻留在内存中,一些很少被访问的数据页能够淘汰掉。
与Free空闲链表、Flush刷写链表相同,对于要可淘汰的数据页,也会被组合成一个LRU淘汰链表,但淘汰链表会由哪些缓冲页组成呢?首先对于空闲页和标记页是不会纳入淘汰范围内的,为啥?
-
空闲页:本身这些缓冲页都没有被使用,内存都是空白的,淘汰空闲页没有任何意义。
-
标记页:被标记过的缓冲页中,由于存在数据还未落盘,所以淘汰掉之后代表数据会丢失。
因此LRU链表是由已使用、但未曾变更过的缓冲页组成的,不过要注意:有些数据页会在Flush、LRU两个链表之间“跳动”:
-
当
LRU链表中的一个数据页发生变更后,会从LRU链表转到Flush链表。 -
当标记页中的变更数据落盘后,此时标记页又会从
Flush链表回到LRU链表。
有些地方会存在些许误区,也就是标记页(脏页)也会被放入LRU链表中,这显然是不对的,为啥?因为所有的链表都是由控制块作为节点构建的,而一个控制块中只有一根指针,也意味着一个控制块同时只能加入一个链表中,所以就不可能出现一个缓冲页,既处于LRU链表,又位于Flush链表中。
淘汰是指将一个已使用的缓冲页,其中的所有数据清空,使其变为一个空闲页。
3.4.1、末尾淘汰机制
-
当一条线程来读写数据时,命中了缓冲区中的某个数据页,那就直接将该页挪到
LRU链表最前面。 -
当未命中缓冲数据页时,需要走磁盘载入数据页,此时内存不够的情况下,会淘汰链表末尾的数据页。
从磁盘载入的数据会直接插入到LRU链表头部,也就是直接将其设置为链表的第一个节点。
这里也许有小伙伴会疑惑:似乎缓冲区中的数据页会一直频繁移动呐,这不会影响性能吗?答案是并不会,为啥呢?因为这里是链表结构而并非数组结构,将一个缓冲页移动到其他链表中,或将一个缓冲页移动到链表最前面,实际上只需要改一下指针即可,无需真正的触发数据挪动的工作。
假设此时LRU链表由8个缓冲页组成,并且此时缓冲区空间已满。此时假设一条查询语句,命中了其中的第6个数据页,此时这个数据页会被挪到最前面:
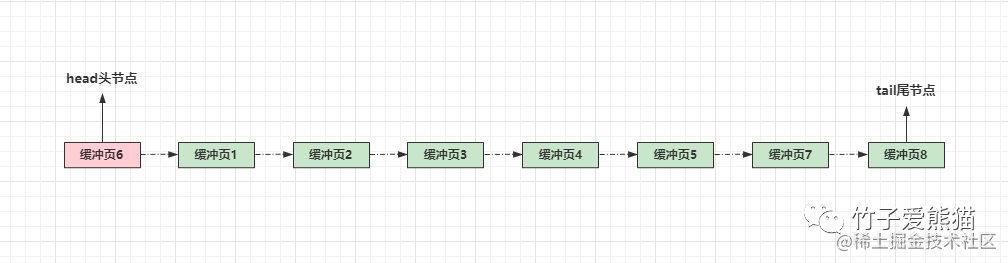
此时又来了一条SQL,要操作的数据在缓冲区不存在,因此会从磁盘读取数据并载入内存,但因为目前缓冲区已经满了,所以需要淘汰一个缓冲页,用来存放载入的新数据,此时就会将末尾的数据页淘汰,如下:
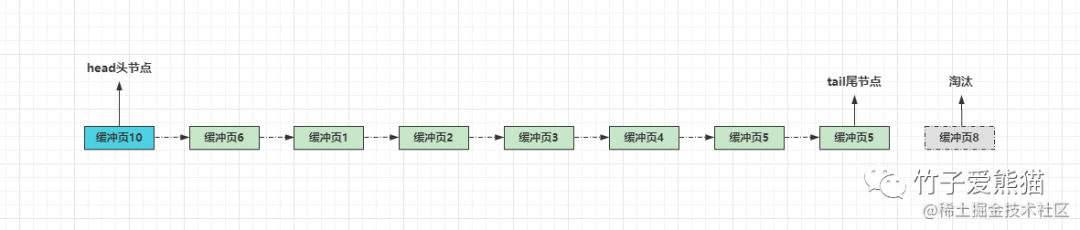
上面这个过程列出了最简单的末尾淘汰机制,但这种方式会存在两个较为致命的问题:
-
①利用局部性原理预读失效时,会导致数据页常驻缓冲区。
-
②查询数据量过大时,会导致缓冲区中的热点数据全部被替换,导致缓冲池被“污染”。
3.4.2、预读失效问题
一般来说,当程序读取某块数据时,这块区域附近的数据也很有可能被读取,因为程序在存储数据时,都会将一个数据保存在一块连续的空间中,因此MySQL在读取数据时,默认会使用局部性思想预读数据,也就是读取一个数据时,默认会将其附近的16KB数据一次性全部载入内存。
当数据载入内存后会分配一个缓冲页来存放,并且会将相应的数据页放在LRU链表的最前面,记住!这个数据页一共是有16KB数据的,也就意味着里面会有多行表数据,假设此时程序只读取了这页数据中的一行记录,对于其他数据并不需要读取,这也就是所谓的预读失效问题。
预读失效:即
MySQL利用局部性原理预读载入的数据,在接下来时间内并未被使用。
如果按照前面列举的那种末尾淘汰机制去载入数据,一页数据被载入后会放到链表的头部,那想要淘汰这个数据页还需要等很长很长一段时间,毕竟MySQL实际会划分出几千几万个缓冲页,把这个没用的数据页放在了最前面,也就意味着该数据页会占用缓冲页很长时间。
为了解决这个问题,InnoDB并未采用最基本的末尾淘汰算法,而是对其做了些许优化,会将整个LRU算法划分为old、young两个区域组成。
young、old两个区域在LRU链表中的占比,默认为63:37,你也可以通过innodb_old_blocks_pc这个参数,来手动调整old区在整个LRU链表中的占比。
默认不改的情况下,假设LRU链表中由100缓冲页构成,那么前63个属于young区,后37个属于old区,示意图如下:
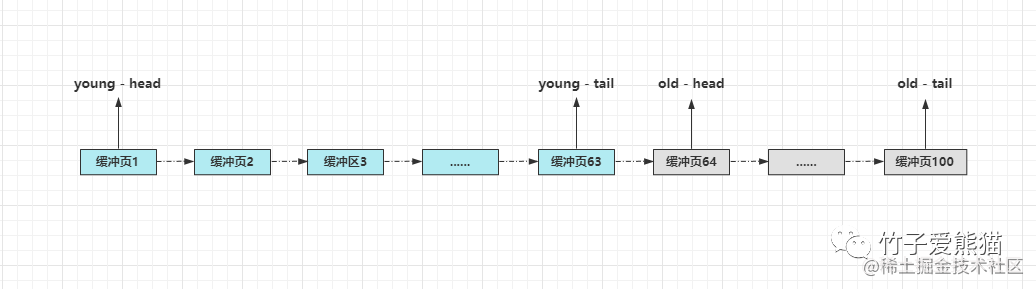
LRU链表被划分为两个区域后,从磁盘中预读的数据页,就只需要加入到old区域的头部,当这个数据页被真正访问时,才会将其插入young区的头部。如果预读的这页在后续一直没有被访问,就会从old区域移除,从而不会影响young区域中的热点数据。
也就是说,在划分为两个区域后,
young区域是用来存储真正的热点数据页,而old区则是用来存放有可能成为热点数据页的“候选人”,当需要淘汰缓冲页时,会优先淘汰old区中的数据页,毕竟young区中留下的都是久经考验的精英!
3.4.3、缓冲池污染问题
InnoDB将LRU链表划分为两个区域后,改善了预读失效带来的问题,但还不够,因为还有可能会出现缓冲池污染的问题。
此时假设一条线程在执行
SQL语句,目前是需要查询一张百万级别的所有表数据,由于Buffer Pool空间有限,所以如果按照原本的淘汰规则来清理内存,这次查询过程可能会导致Buffer Pool里面的所有热点数据全部被换出。等这次查询结束后,内存中只剩下了这次查询载入的数据页,当有线程访问原本哪些热点数据时,由于缓冲区中的数据页被换出了,因此就会产生大量的磁盘IO。
上述这个过程,则被称之为Buffer Pool污染问题,但要注意:并不是需要查询大量结果才会导致这个问题出现,而是当扫描的数据过多时,都会引发此问题,比如典型的对大表执行了全表扫描,因为在扫描的过程,会不断从磁盘载入新的数据页放在内存中。
InnoDB为了解决该问题,又引入了一种新的技术,名为young区晋升限制,是不是有点耳熟?在JVM中,为了防止新生代过早晋升年老代,从而频繁触发FullGC的问题,在设计时也有晋升条件限制,默认情况下,一个对象只有达到了15岁之后,才能从新生代晋升年老代,毕竟能够熬过16轮新生代GC的对象,也绝对不会无缘无故突然挂掉。
而
InnoDB中的young区晋升限制,同样是这个原理,毕竟上面的全表扫描案例中,很多数据页只会被访问一次,但是由于需要访问它,所以才被载入了内存,最终导致old区放不下,从而导致了young区的热点数据被替换。
而加入了young区的晋升限制后,就能有效避免这种访问一次的数据页过早进入young区,InnoDB是怎么做的呢?其实很简单,就是加了一个停留时间的限制,如果一个数据页想从old区晋升到young区,必须要在old区中存活一定时间,这个时间默认为1s/1000ms,也可以通过参数innodb_old_blocks_time调整。
思考一下,由于存在这个时间限制,所以
old区的数据页,想要进入young区,就必须达成两个条件:
①在old区中停留的时间超过了1000ms。
②在old区中,一秒后有线程再次访问了这个数据页。
上面的第一条还比较容易理解,但第二条估计有些懵,啥意思啊?其实很简单,结合前面的淘汰算法:一个刚被载入的数据页,会先放到old区的头部,当该数据页被二次访问后才会挪到young区的头部。
通过这种晋升限制的方式,就能完美的解决全表扫描引起的缓冲池污染问题,这也是InnoDB最终的淘汰机制,当一个缓冲页的数据被淘汰后,也就是一个缓冲页的数据被清空后,会将其再次加入到Free空闲链表中等待分配。
四、MySQL内存总结
**InnoDB引擎几乎将所有的操作都放在了内存中进行**,比如写日志、写数据、查数据等,只有逼不得已的情况下,才会走磁盘读写数据。
假设你部署
MySQL的机器内存足够大,并且为Buffer Pool分配的内存空间也足够大,比如机器的内存有128GB,此时为Buffer Pool分配了100GB,而整个库的所有表数据加起来仅有80GB,此时要记住,InnoDB几乎会将所有的表数据全部载入内存,后续所有的读写操作都会基于内存+后台线程刷盘的方式进行。
到这里大家会发现,虽然InnoDB是一款基于磁盘研发的存储引擎,但它几乎将内存的使用开发到了极致,能在内存完成的就压根不会走磁盘,在最大程度上提升MySQL的整体性能。
总结一下InnoDB内存管理这块的内容,InnoDB采用三个链表结构来管理所有的缓冲页:
-
Free链表:统一管理、分配所有未使用的缓冲页。 -
Flush链表:统一管理、刷写所有被标记过的缓冲页。 -
Lru链表:统一管理、淘汰所有已使用、未变更过的缓冲页。
在内存的淘汰机制方面,InnoDB基于末尾淘汰机制做了两点改善:
-
①将
Lru链表划分为了young、old两个分区,用来解决预读失效导致的内存占用问题。 -
②引入了
young区的晋升限制,解决了全表扫描时,young区的热点数据页被换出的问题。















 981
981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









