







架构图模板
系统架构图是为了抽象的表示软件系统的整体轮廓和各个组件之间的相互关系和约束边界,以及软件系统的物理部署和软件系统的演进方向的整体视图。好的架构图可以让干系人理解、遵循架构决策,就需要把架构信息传递出去。那么,画架构图是为了:解决沟通障碍/达成共识/减少歧义。比较流行的是4+1视图和C4视图。
一:怎么画好架构图
一个好的架构图是不需要解释的,它应该是自描述的,并且要具备一致性和足够的准确性,前瞻性,能够与后面的设计相呼应。
架构方案的受众分析
架构方案,也要 千人千面
在画出一个好的架构图之前, 首先应该要明确其受众,再想清楚要给他们传递什么信息 ,一个方案,面向不同的受众,需要有不同的视图。不是为了画图而画图,而是应该差异化分析。要进行受众分析,应该根据受众的不同,传递的信息的不同,用图准确地表达出来,最后的图可能就是在这样一些分类里。
视图的分析维度
针对不同的受众,有不同的分析图。但是,也是层层深入的。大概有下面的 8个维度。
架构图1:场景视图
用于描述系统的参与者与功能用例间的关系,反映系统的最终需求和交互设计,通常由用例图表示;
场景分析图的受众:外部的技术或非技术人员,包括团队内部或外部的开发人员或运维人员,
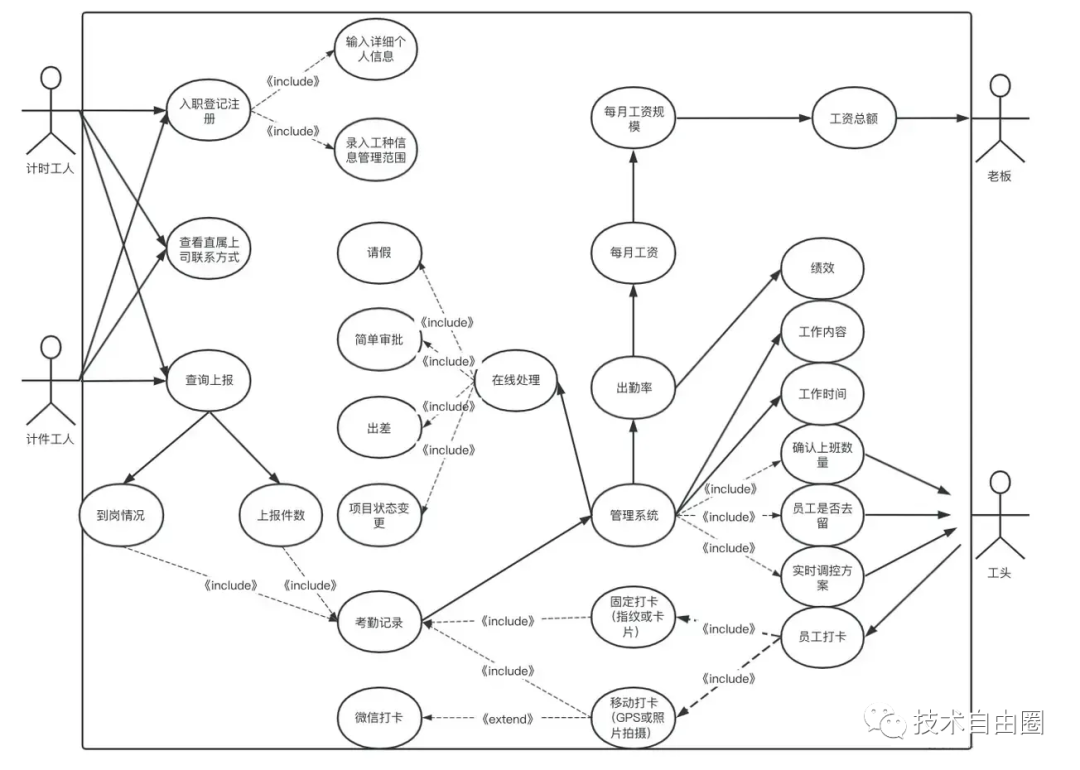
架构图2:系统架构分析
系统架构分析 用于描述系统软件功能拆解后的组件关系,组件约束和边界,反映系统整体组成与系统如何构建的过程,通常 子系统的 线框图表示。
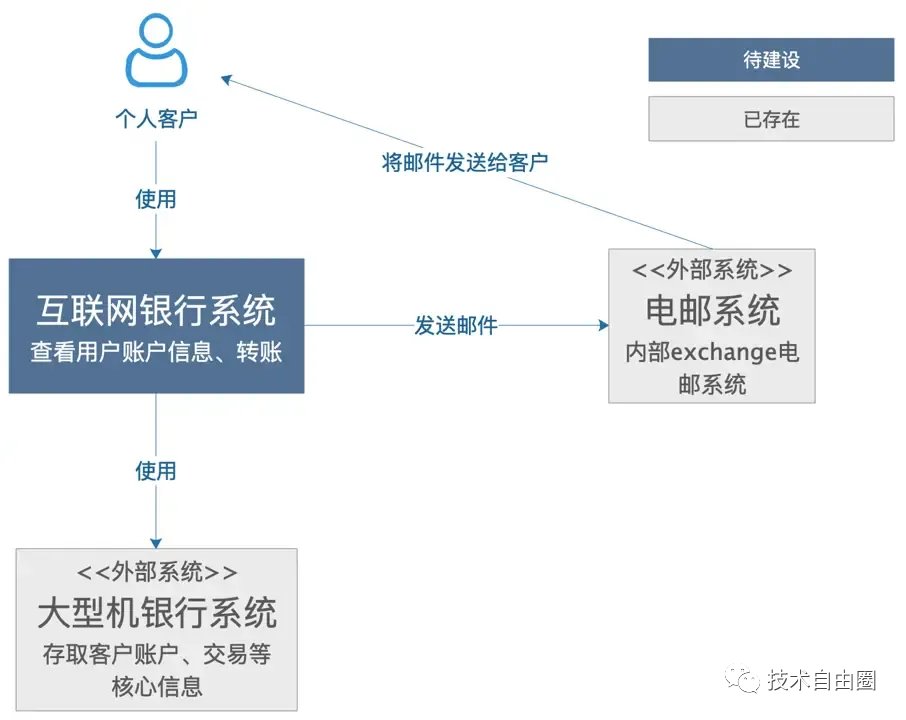
架构图3:系统依赖分析(System Context Diagram)
系统依赖分析(System Context Diagram)用于描述要我们要构建的系统是什么,子系统直接的依赖关系是什么,用户是谁,需要如何融入已有的IT环境。
系统依赖分析图的受众:外部的技术或非技术人员,包括团队内部或外部的开发人员或运维人员
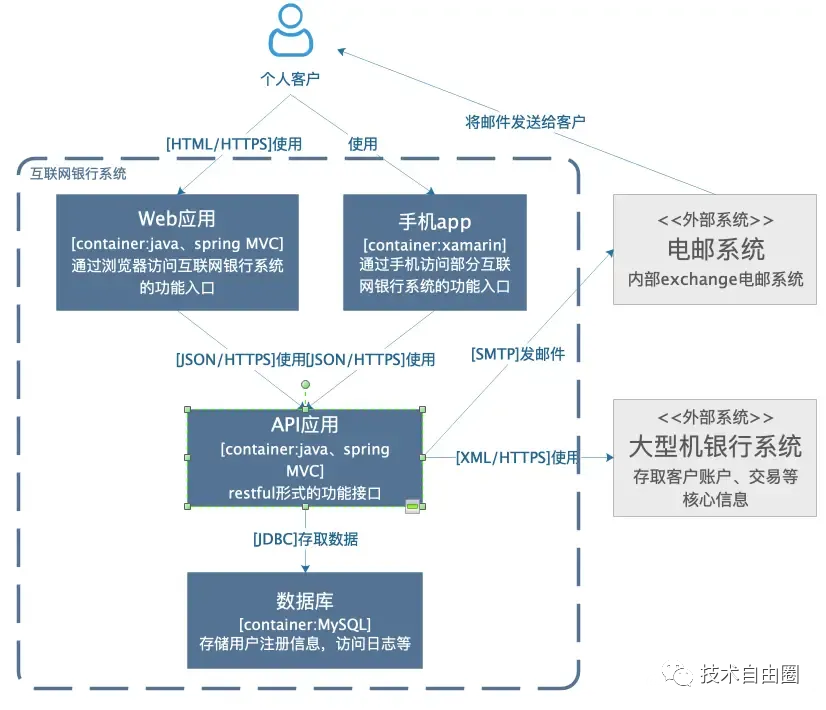
架构图4:子系统依赖分析(Container Diagram)
子系统依赖是系统依赖图里,对待建设的子系统做了一个内部依赖关系展开分析,子系统依赖分析 主要用来描述子软件系统的内部的依赖关系,分析系统中的职责是如何分布的,子系统是如何交互的。
子系统依赖分析的受众:外部的技术或非技术人员,包括团队内部或外部的开发人员或运维人员
架构图5:组件架构图(Component Diagram)
组件架构图是把针对某个子系统 进行组件设计、模块设计,组件架构图 用于 子系统 的模块关系,介绍 子系统由哪些组件/服务组成,了组件之间的关系和依赖,为软件开发如何分解交付提供了框架。组件架构图受众:主要是给内部开发人员看的。
组件架构图的作用:为代码的组织和模块架构,提供支撑
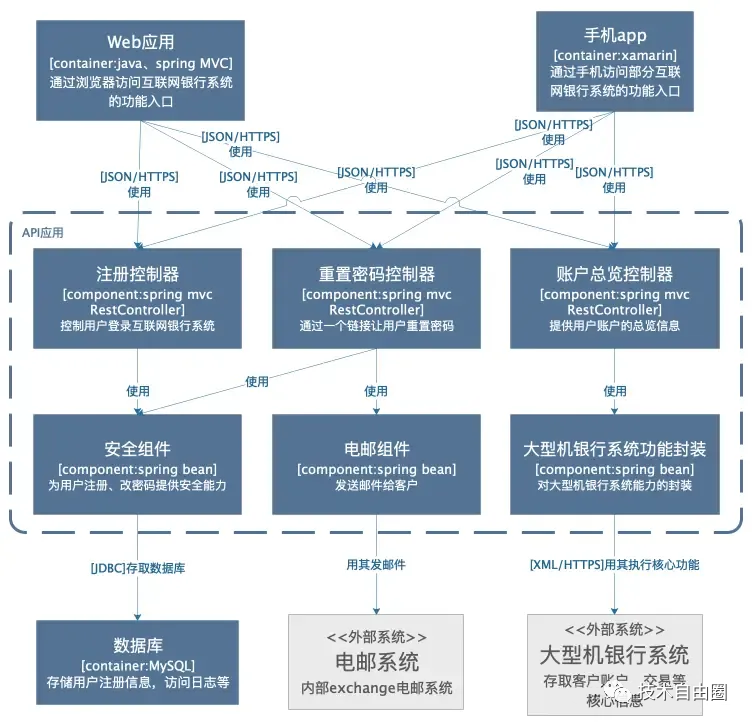
架构图6:模块架构图
从编码的维度来说,组件内部,很多模块。模块架构分析 ,是对组件的进一步 深入分析。
模块架构分析用于描述模块划分和组成。模块架构分析可以细化到内部包的组成设计,服务于开发人员,反映系统开发实施过程。
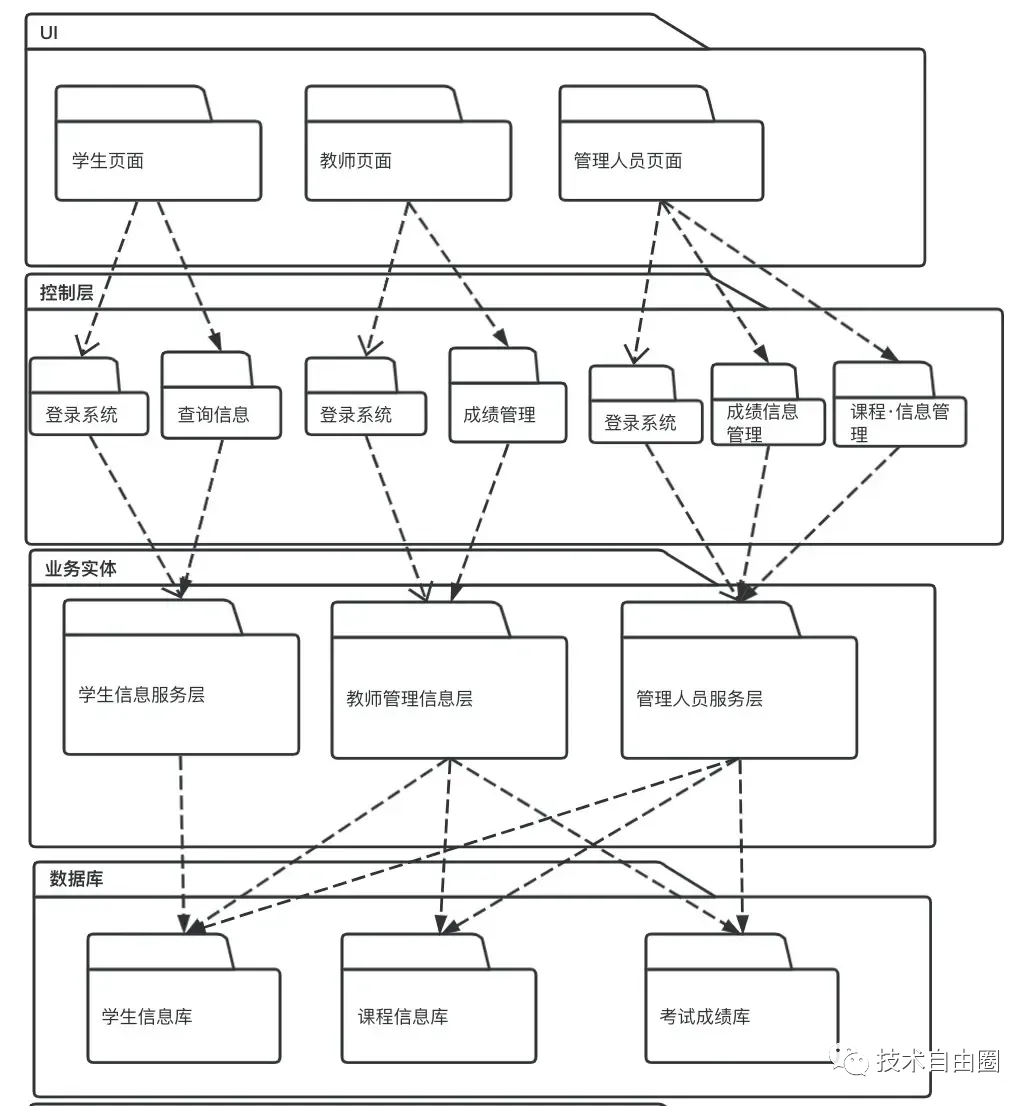
架构图7:逻辑架构视图
逻辑架构视图 用于描述系统模块内部的的通信时序,数据的输入输出,反映系统的功能流程与数据流程、通常由时序图和流程图表示。
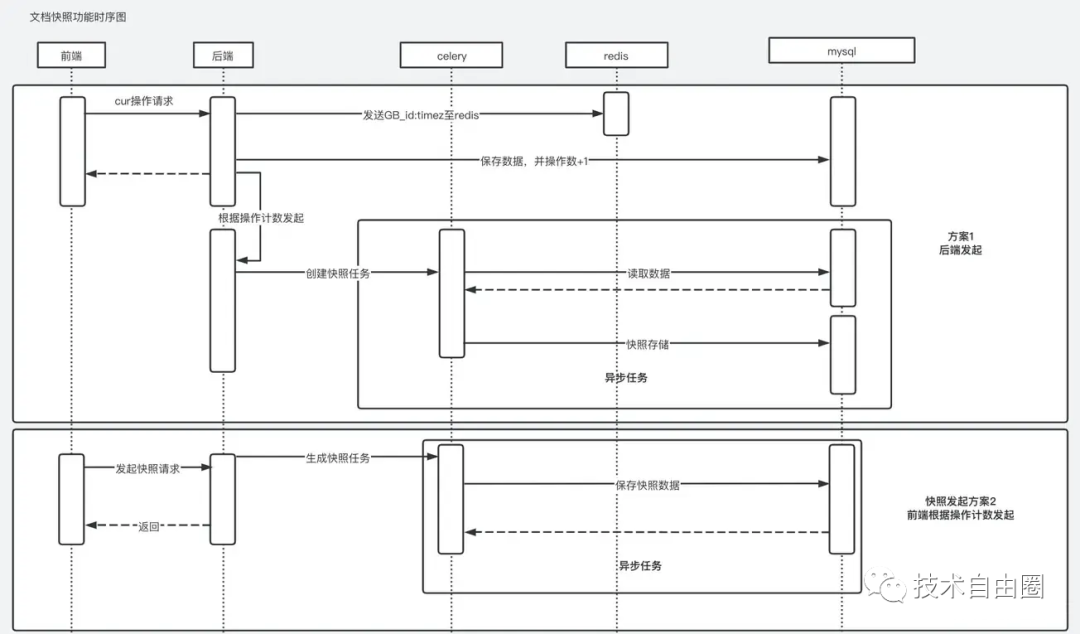
架构图8:部署架构分析
用于描述系统软件到物理硬件的映射关系,反映出系统的组件是如何部署到一组可计算机器节点上,用于指导软件系统的部署实施过程。
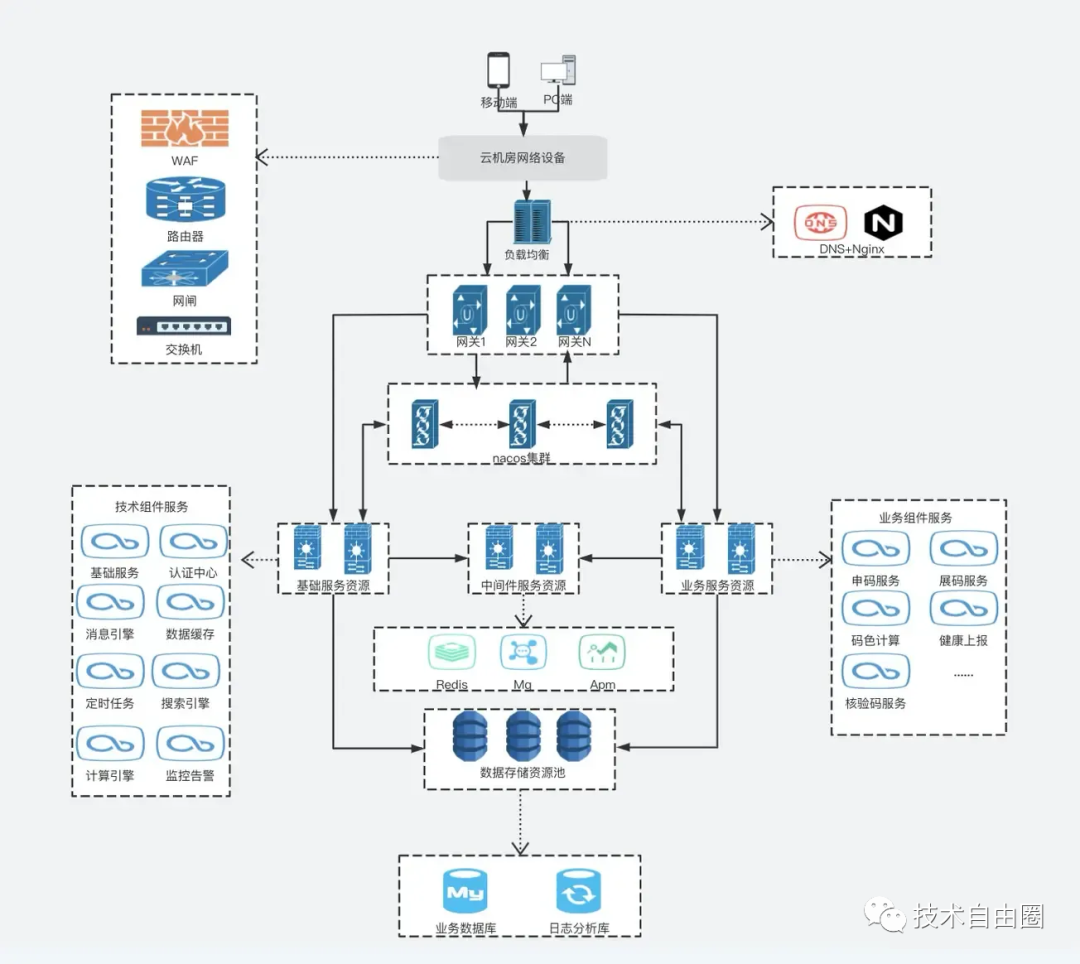
二:怎么做好架构方案?
2.1、现状
现状,主要是用来描述当前这个业务(项目)的一些基本情况介绍和相关的背景。方案设计出来之后,是需要给你的 leader 或者团队其他成员进行评审或者查看,一般来说,由技术委员会来评审。但是别人不可能都和你一样清楚你的项目,因此首先,你要把你项目的基本情况和背景都说清楚,让大家达成一个共识,大家站在同一个起点上,才能进行后面的方案评审和讨论。
业务背景
业务背景就是你这个业务的基本介绍,包括但不限于:
-
项目名称
-
业务描述
-
业务难点
技术背景
技术背景就是项目是基于什么样的技术背景下来构建的,可以是从 0 到 1 来构建,也能是基于现有的方案来优化,但是不管是什么场景,一定都会存在相关的技术背景,因此包括但不限于:
-
现有技术积淀
-
现有架构描述
-
现有系统的整体容量
2.2、需求
需求,很重要。不管你的技术有多牛逼,都一定为需求服务的,不管这个需求是技术需求,还是业务需求,一定都是要为需求服务。
注意:需求,这个需求可以是当下的需求,尽可能 包含未来潜在的需求。
需求越完善,后面会少走弯路。
业务需求
业务需求就是你这个业务具体要做的事情,包括但不限于:
-
业务的功能点
-
要提升改造的功能
业务痛点
-
涉及到的业务痛点有哪些
性能需求
除了业务需求,还要从这个业务需求里面考虑清楚我们满足这个业务之下的性能需求点,如果一个系统不考虑性能,可能流量一上来,服务就挂掉了。
性能需求包括但不限于:
-
预估系统平均容量
-
预估系统峰值容量
-
可伸缩性
-
其他的一些性能要求点,比如安全性等
2.3、方案描述
前面把现状和需求说清楚后,终于到了我们的重头戏,方案描述这里了。一般,需要会有几个可选的方案,也就是说,尽可能把相关可能的方案都描述清楚,然后给出你认为的最合适的方案,然后让大家来评审和决策,看是否同意你的意见或者有其他更好的意见。
除非万不得已,最好,不要一只有个方案。
方案1
概述
说明一下方案的核心亮点、核心特色,核心目标,核心优势。
比如说:高性能、可扩展、双写、主从分离、分库分表、扩容等。
详细说明
详细说明这里需要图文结合,包括但不限于架构图、流程图 等。
把你整个方案的架构和模块、细节流程都描述清楚。
性能目标
性能一般来说可能包含以下部分:
-
DAU:日活跃用户数量。一般用于反映网站、互联网应用等运营情况。
-
平均QPS:可以参考淘宝的平均QPS 估算公式,进行估算。
-
峰值QPS:一般可以以QPS的2~4倍计算;
资源评估
给出方案的基准数据,并按性能需求评估需要使用的资源数量。
按照预估性能需求,预估资源数量
-
单节点并发量
-
单节点容量
-
应用服务器的单节点资源配置、节点数
-
缓存的单节点资源配置、节点数
-
数据存储的单节点资源配置、节点数
-
消息队列的单节点资源配置、节点数
-
反向代理的单节点资源配置、节点数
-
搜索引擎的单节点资源配置、节点数
-
伸缩方式
-
高可用方式
-
监控预警的方式
方案优缺点
列出方案的优缺点,这个需要通过量化的指标来支撑。
方案2
可选的另外一种方案,模板和上面一样。
方案对比
前面给出了多种可选的方案,那么这里就是进行一个简单的对比,然后,给出自己的觉得最优的方案,并且给出支撑的数据、理由。
有了你自己的决策(倾向)的方案后,当然,对于最优的方案,就应该提供更有支撑力的细化的方案和数据。
2.4、线上方案
线上方案是对上面你更倾向的方案的更为细致的描述。
架构图
整体架构是如何,把架构图画上。
关键设计点 和 设计折衷
把核心的关键点,用自己的 名词系统表达出来。这里有一个要求:整体是完备的、自洽的。用来确保你的方案的大体方向是 OK 的。
因为没有一个方案设计是最完美,方案设计都是逐步演进和优化的,但是,一定是完整的、系统的、没有大漏洞的。还有,方案设计是要最符合当前的背景的。
业务流程
对于业务的核心场景,弄一个整体流程图、核心流程图出来,然后分业务场景把各个业务场景的流程图也画出来,并且做好相关介绍。
模块划分
模块的划分需要考虑我们架构设计的一些原则,比如:架构分层、业务分模块、微服务化、高内聚低耦合 等。然后把每个模块的功能点都说清楚。
异常边界【重要】
异常边界是比较重要的,一般情况下,大部分人都能考虑到正常的处理流程,对于异常的边界考虑的比较少,但是线上出问题,大部分都是异常情况导致,因此这里非常重要。
我们可以通过一个 思维导图 去整理相关的异常边界,这样有助于自己在实现的时候有足够的把控度,也便于别人去 review 你的方案和具体实现(如 coding)。
异常边界需要考虑:
-
涉及到了哪些模块
-
涉及到了哪些流程
-
每个模块、流程出现了各种可能情况的处理是?
-
系统底层原因导致的异常的处理是 ?
监控、预警、统计
线上运行的项目,一定需要有各种监控,预警、指标统计。可以使用 公司内部的基建的监控外,还需要从业务内部,实现自定义的一些业务监控和相关技术统计。最终的目标、保证系统的高可用、支撑系统的高可用。
灰度、回滚策略
-
如何灰度?
-
如何回滚?
容灾方案
容灾就是当出现 IDC 异常的情况下,怎么容灾,这个可以根据实际情况去考虑。
2.5、部署架构
可以按照下面的方向,去做拓展:
-
线上部署拓扑什么,
-
各层的部署架构是什么
-
多活的部署架构是什么
-
公有云部署架构是什么
2.6、风险评估
标识所选方案的风险,提出解决此风险发生时候的应对策略,比如:上线失败时的回滚策略。
潜在风险
-
相关的改动有哪些风险点
-
不兼容点?
-
当前设计方案目前存在哪些问题?
-
潜在有哪些问题
2.7、阶段规划【架构演进规划】
架构怎么演进
阶段如何规划
每个阶段该达成什么目标
第一阶段
目标 XXXX
第二阶段
目标 XXXX
第三阶段
目标 XXXX
2.8、投入评估
最后,需要做投入的评估,作为投资回报分析的支撑,包括:
-
物理设备、云设备投入评估
-
工作量评估,
这里需要细化到每个模块、
工作量评估 一般按照时间进行,一定要同时包括开发时间、联调时间、测试时间。
最好比较细化,不要太粗,比如开发时间可以细化到接口的维度,每个接口的设计分别需要多长时间,
全链路异步,让性能优化10倍+
背景
随着业务的发展,微服务应用的流量越来越大,使用到的资源也越来越多。在微服务架构下,大量的应用都是 SpringCloud 分布式架构,这种架构,总体是全链路同步模式。同步编程模式不仅造成了资源的极大浪费,并且在流量发生激增波动的时候,受制于系统资源而无法快速的扩容。
全球后疫情时代,降本增效是大背景。如何降本增效?
可以通过技术升级,全链路同步模式 ,升级为 全链路异步模式。
全链路同步模式架构图
先回顾一下全链路同步模式架构图
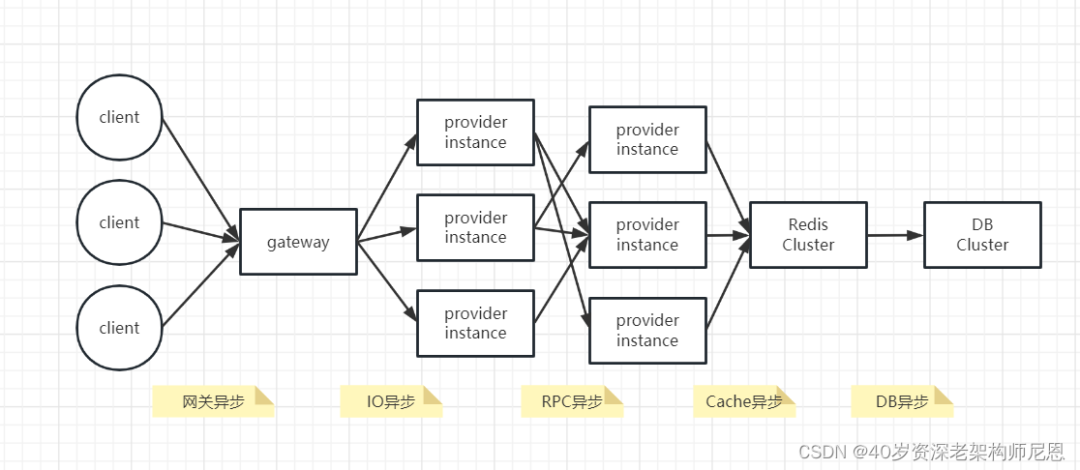
全链路同步模式 ,如何升级为 全链路异步模式, 就是一个一个 环节的异步化。
全链路异步模式
网关纯异步化(提升 9倍以上)
网关层的特点:
-
不需要访问业务数据库只做协议转换和流量转发
-
特点是 IO 密集型,特别适合纯异步的架构,可以极大的节省资源。
如何进行网关异步化?
使用高性能的通信框架Netty,这是一个基于NIO 非阻塞IO+ Reactor 纯异步线程模型的纯异步化框架。网关的技术选型主要有 zuul,SpringCloud GetWay 。
-
zuul 1虽然使用的同步io,zuul2它也是使用异步的netty,但是没有和SpringCloud 框架集成
-
springcloud getway 它是基于spring 5.0 、spring boot 2.0 和spring reacter,为微服务提供一个简单有效的网关API路由接口。和SpringCloud 框架完美集成,目标是为了代替zuul
SpringCloud GetWay 是基于webFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。所以最终还是基于IO的王者组件Netty。
如果使用Zuul 1,那么升级为 SpringCloud GetWay,性能可以提升 9倍以上。总体来说,这个环节,是纯异步化最容易的。这个环节,大部分已经升级到了 springcloud getway 已经使用了纯异步的架构。
Web 服务异步化(2W并发场景提升 20倍以上)
Web 服务作为微服务体系内的重要组成,服务节点众多,Springboot的Web 服务默认为 Tomcat + Servlet 不支持纯异步化编程,Tomcat + Servlet模式的问题:总体上没有使用Reactor 反应器模式, 每一个请求是阻塞处理的,属于同步 Web 服务类型。
京东一面:20种异步,你知道几种?含协程Servlet 有异步的版本,可惜没有用起来,参考:京东一面:20种异步,你知道几种?含协程
所以:跑在生产环境上的,还是Tomcat + Servlet 同步 Web 服务。如何实现 Web 服务异步化:
-
方式一:基于Netty 实现web服务
-
方式二:使用 WebFlux (还是 Netty 实现web服务)
Spring WebFlux是一个响应式堆栈 Web 框架 ,它是完全非阻塞的,支持响应式流(Reactive Stream)背压,并在Netty,Undertow和Servlet 3.1 +容器等服务器上运行,看一下对于 WebFlux 的对比测试数据 (来自于参考文献1):
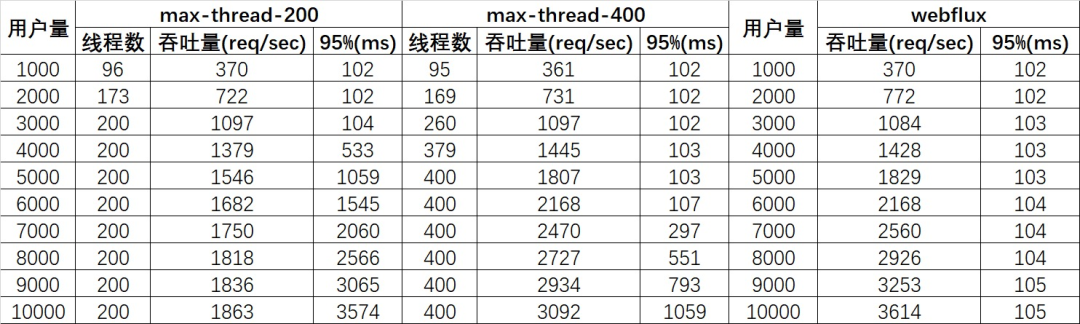
可见,非阻塞的处理方式规避了线程排队等待的情况,从而可以用少量而固定的线程处理应对大量请求的处理。直接测试一下20000用户的情况:
-
对 mvc 的测试由于出现了许多的请求fail,最终以失败告终;
-
而 WebFlux 应对20000用户已然面不改色心不慌,吞吐量达到7228 req/sec
注意:正好是10000用户下的两倍,绝对是真实数据!也就是说, 2W并发场景提升 20倍以上,
95%响应时长仅117ms。
最后,再给出两个吞吐量和响应时长的图,更加直观地感受异步非阻塞的WebFlux是如何一骑绝尘的吧:
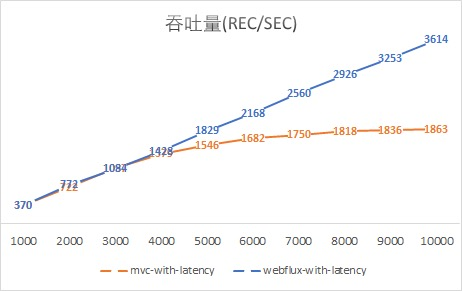
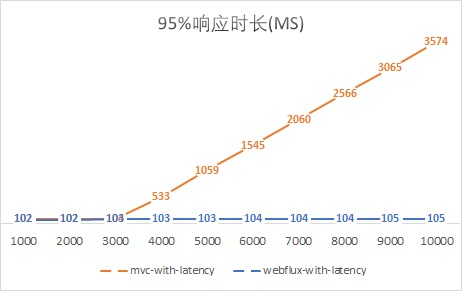
此时,我们更加理解了Nodejs的骄傲,不过我们大Java语言也有了Vert.x和现在的Spring WebFlux。
RPC 调用异步化(提升 9倍以上)
异步RPC 调用,等待upstream 上游 response 返回时,线程不处于block 状态,作为微服务架构中数据流量最大的一部分,RPC 调用异步化的收益巨大;RPC 调用主要的框架有:
特点是:
-
feign 是同步IO 、阻塞模式的同步 RPC框架
-
dubbo 是基于Netty的非阻塞IO + Reactor 反应堆线程模型的 异步RPC框架
SpringCloud + Dubbo RPC 的集成,在同一个微服务下,同时使用了Feign + Dubbo
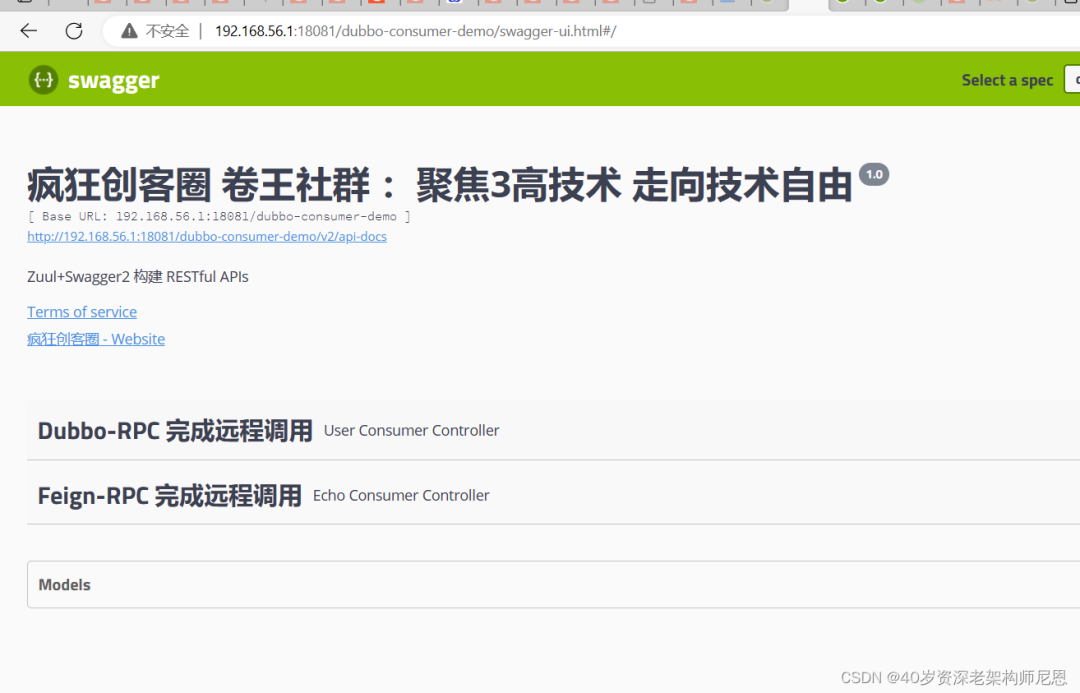
然后进行了性能的对比验证
dubbo 的压测数据
wrk -t8 -c200 -d30s --latency http://cdh1:18081/dubbo-consumer-demo/user/detail/v1?userId=1
[root@centos1 src]# wrk -t8 -c200 -d30s --latency http://cdh1:18081/dubbo-consumer-demo/user/detail/v1?userId=1
Running 30s test @ http://cdh1:18081/dubbo-consumer-demo/user/detail/v1?userId=1
8 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 30.10ms 45.68ms 644.45ms 95.43%
Req/Sec 1.12k 465.63 2.36k 66.87%
Latency Distribution
50% 18.94ms
75% 28.43ms
90% 46.21ms
99% 283.56ms
264316 requests in 30.07s, 148.47MB read
Requests/sec: 8788.96
Transfer/sec: 4.94MB

feign 的压测数据

wrk -t8 -c200 -d30s --latency http://cdh1:18081/dubbo-consumer-demo/echo/variable/11
[root@centos1 src]# wrk -t8 -c200 -d30s --latency http://cdh1:18081/dubbo-consumer-demo/echo/variable/11
Running 30s test @ http://cdh1:18081/dubbo-consumer-demo/echo/variable/11
8 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 321.50ms 294.59ms 2.00s 61.77%
Req/Sec 87.18 43.39 232.00 67.00%
Latency Distribution
50% 309.06ms
75% 503.06ms
90% 687.99ms
99% 1.21s
20495 requests in 30.10s, 7.64MB read
Socket errors: connect 0, read 0, write 0, timeout 49
Requests/sec: 680.90
Transfer/sec: 259.99KB
从数据来看, dubbo rpc 是feign rpc 性能10倍。
Cache异步化(提升2倍+)
Cache Aside 缓存模式,是大家通用的Cache使用方式,Cache纯异步的架构,必须使用异步存储层客户端,主要有:
-
Redisson
-
Lettuce
Jedis那么低性能,还在用?赶紧换上 lettuce 吧Redisson、Lettuce如何选型:Jedis那么低性能,还在用?赶紧换上 lettuce 吧
使用Lettuce的场景:
[root@centos1 ~]# wrk -t8 -c200 -d30s --latency http://192.168.56.121:7703/uaa-react-provider/api/userCacheAside/detail/v1?userId=1
Running 30s test @ http://192.168.56.121:7703/uaa-react-provider/api/userCacheAside/detail/v1?userId=1
8 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 18.29ms 13.56ms 213.57ms 89.56%
Req/Sec 1.51k 504.74 4.26k 72.86%
Latency Distribution
50% 14.56ms
75% 19.92ms
90% 31.20ms
99% 76.70ms
359546 requests in 30.10s, 53.15MB read
Requests/sec: 11945.39
Transfer/sec: 1.77MB

使用jedis的场景
wrk -t8 -c200 -d30s --latency http://192.168.56.121:7702/uaa-provider/api/user/detailCacheAside/v1?userId=1
[root@centos1 src]# wrk -t8 -c200 -d30s --latency http://192.168.56.121:7702/uaa-provider/api/user/detailCacheAside/v1?userId=1
Running 30s test @ http://192.168.56.121:7702/uaa-provider/api/user/detailCacheAside/v1?userId=1
8 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 42.20ms 44.79ms 1.11s 93.41%
Req/Sec 683.30 245.08 1.85k 67.39%
Latency Distribution
50% 32.65ms
75% 48.30ms
90% 72.32ms
99% 199.81ms
162271 requests in 30.09s, 71.96MB read
Requests/sec: 5393.75
Transfer/sec: 2.39MB
吞吐量从5000提升到10000, 99%响应时间从199.81ms降低到76.70ms。
DB的异步化(假装提升10倍)
数据操作是每个请求调用链的终点,纯异步的架构必须使用异步存储层客户端,比如说,可以使用纯异步化的框架 Spring Data R2DBC。
但是DB是一个低吞吐的物种,对于DB而已,请求太多,反而忙不过来,造成整体的性能下降。没有必要对DB进行纯异步化改造,反而是进行隔离和保护:
-
参考 Hystrix舱壁模式, 通过 DB 的操作进行 线程池隔离
-
使用 手写 Hystrix Command 的方式,进行 DB 操作的 高压防护。
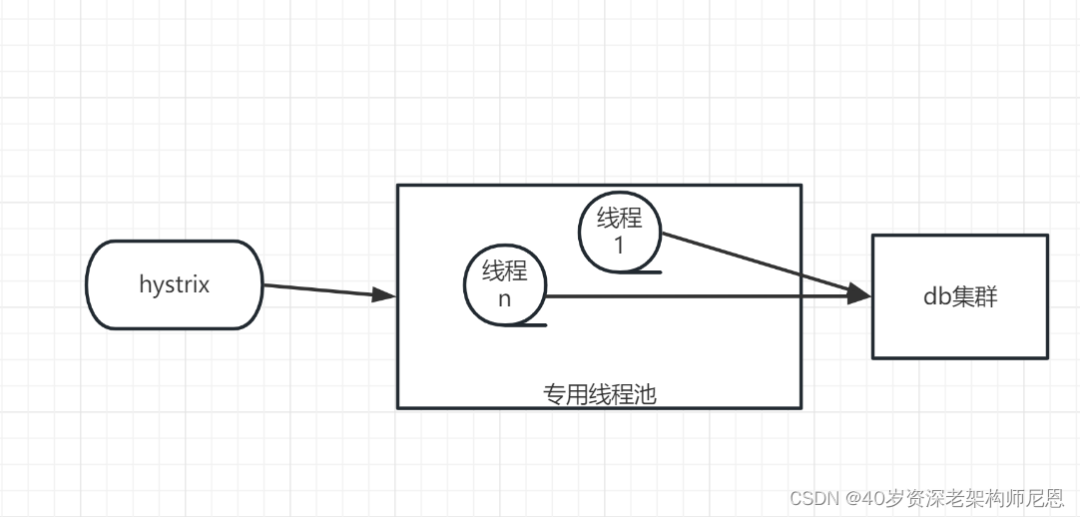
控制线程数和请求数,保护不至于拖垮DB。由于高压防护,在高并发场景能快速失败,所以肯定提升不止10倍,不过是假装提升10倍
纯异步与伪异步
异步调用目的在于防止当前业务线程被阻塞。伪异步将任务包装为Runnable 放入另一个线程执行并等待,当前Biz 线程不阻塞;纯异步为响应式编程模型,通过IO 实践驱动任务完成。
在全链路异步改造的过程中,大量使用了响应式编程。
参考文献
https://blog.csdn.net/get_set/article/details/79492439
https://blog.csdn.net/crazymakercircle/article/details/128899176
https://blog.csdn.net/crazymakercircle/article/details/124120506
1000亿数据、30W级qps如何架构?
点赞场景的业务分析
做系统架构,首先要需求分析。点赞的业务,已经足够的简单,极致的简要。
需求1:视频的点赞数
需求2:UP主维度的总获赞数
需求3:个人的点赞记录

需求N:细分的需求比较多
......
数据规模、流量规模分析
做系统架构,其次要确定 数据规模、流量规模, 为什么?不同的体量,架构的方式、方法、方案,都完全不一样。
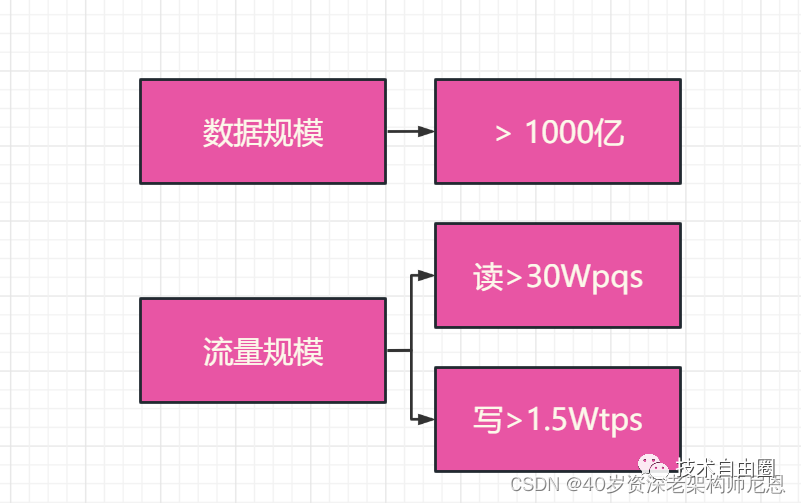
数据规模:千亿级别
流量规模:
读流量:30W QPS , 全站点赞状态查询、点赞数查询等【读流量】超过300k,
写流量:1.5W QPS ,点赞、点踩等【写流量】超过15K
大流量、大数据场景下点赞中台化诉求
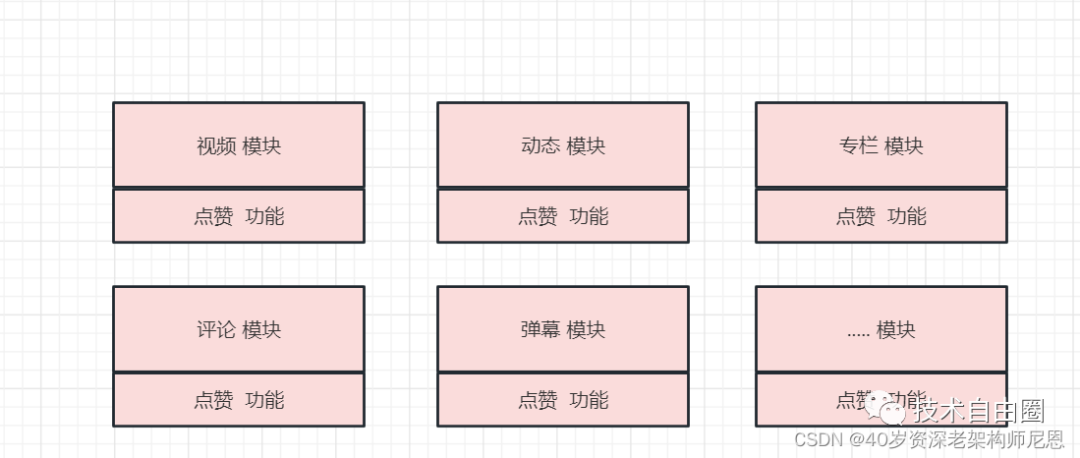
点赞功能,在中台化之前,是分散的。各大业务模块,都有点赞功能的存在,如以下模块:
稿件、视频、动态、专栏、评论、弹幕、等等
以 “稿件” 为例,点赞服务需要提供
-
对某个稿件点赞(取消点赞)、点踩(取消点踩)
-
查询是否对 单个 或者 一批稿件 点过赞(踩) - 即点赞状态查询
-
查询某个稿件的点赞数
-
查询某个用户的点赞列表
-
查询某个稿件的点赞人列表
-
查询用户收到的总点赞数
大流量、大数据场景下,需要进行中台化、平台化
-
进行业务聚合,提供多种实体维度数据查询、数据分析的能力
-
点赞作为一个与社区实体共存的服务,需要提供很强的容灾能力
-
提供业务快速接入的能力(配置级别)
-
数据存储上(缓存、DB),具备数据隔离存储的能力(多租户)
中台化 之后的架构图如下
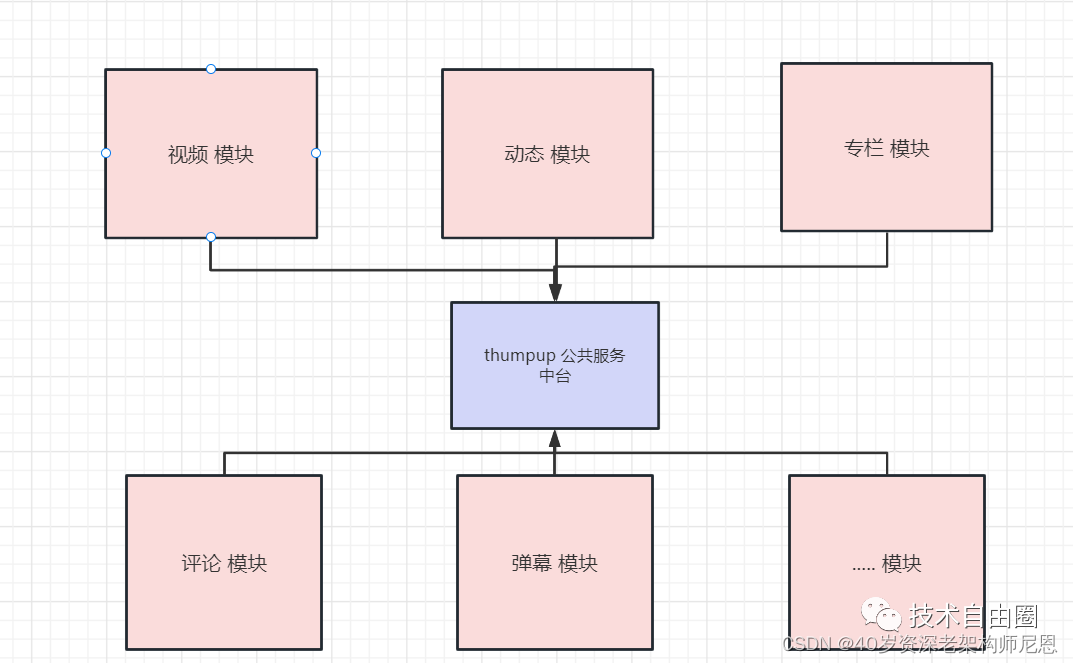
从此,各大业务模块,业务子系统,再也不用担心点赞的 海量数据问题, 巨量的流量问题, 点赞服务的不可用的问题。`这些问题,都交给中台解决了。各大业务模块,业务子系统,直接使用接口就行。
B赞点赞中台的整体架构
B站架构师给出的架构图
下面是哔哩哔哩资深开发工程师 芦文超, 给出的系统架构图
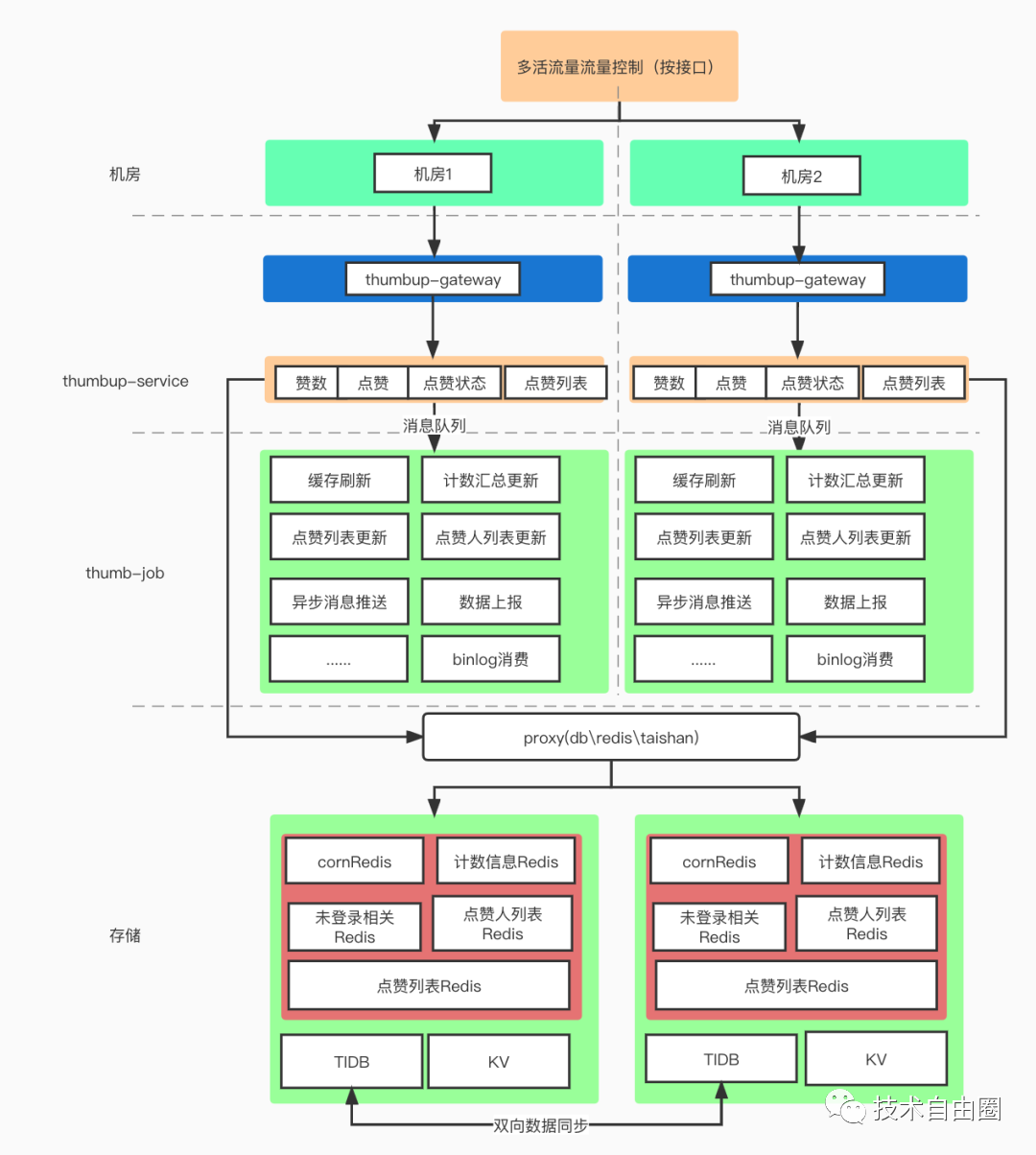
整个点赞服务的中台可以分为五个部分
-
流量路由层(决定流量应该去往哪个机房)
-
业务网关层(统一鉴权、反黑灰产等统一流量筛选)
-
点赞服务(thumbup-service),提供统一的RPC接口
-
点赞异步任务(thumbup-job)
-
数据层(db、kv、redis)
分层架构的二次梳理
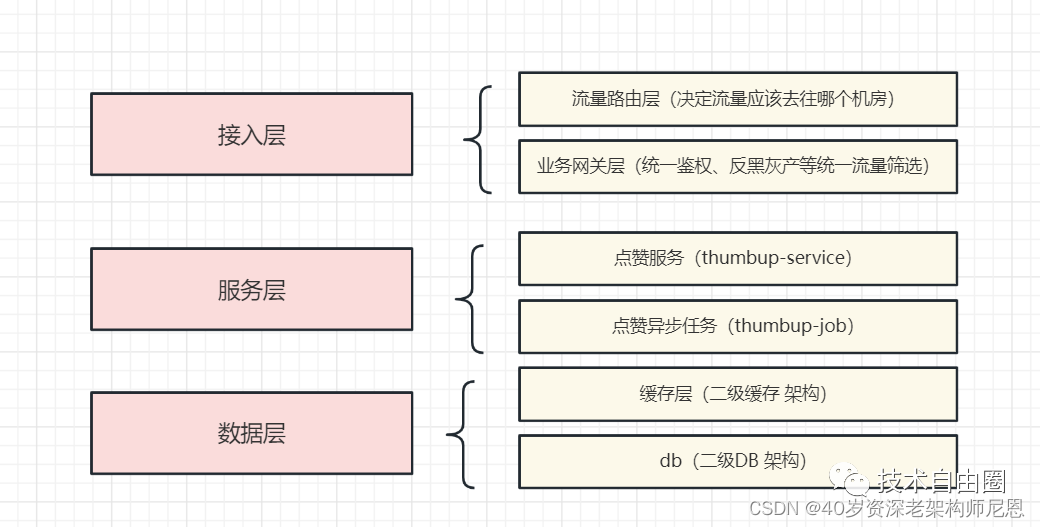
B赞点赞中台的接入层架构
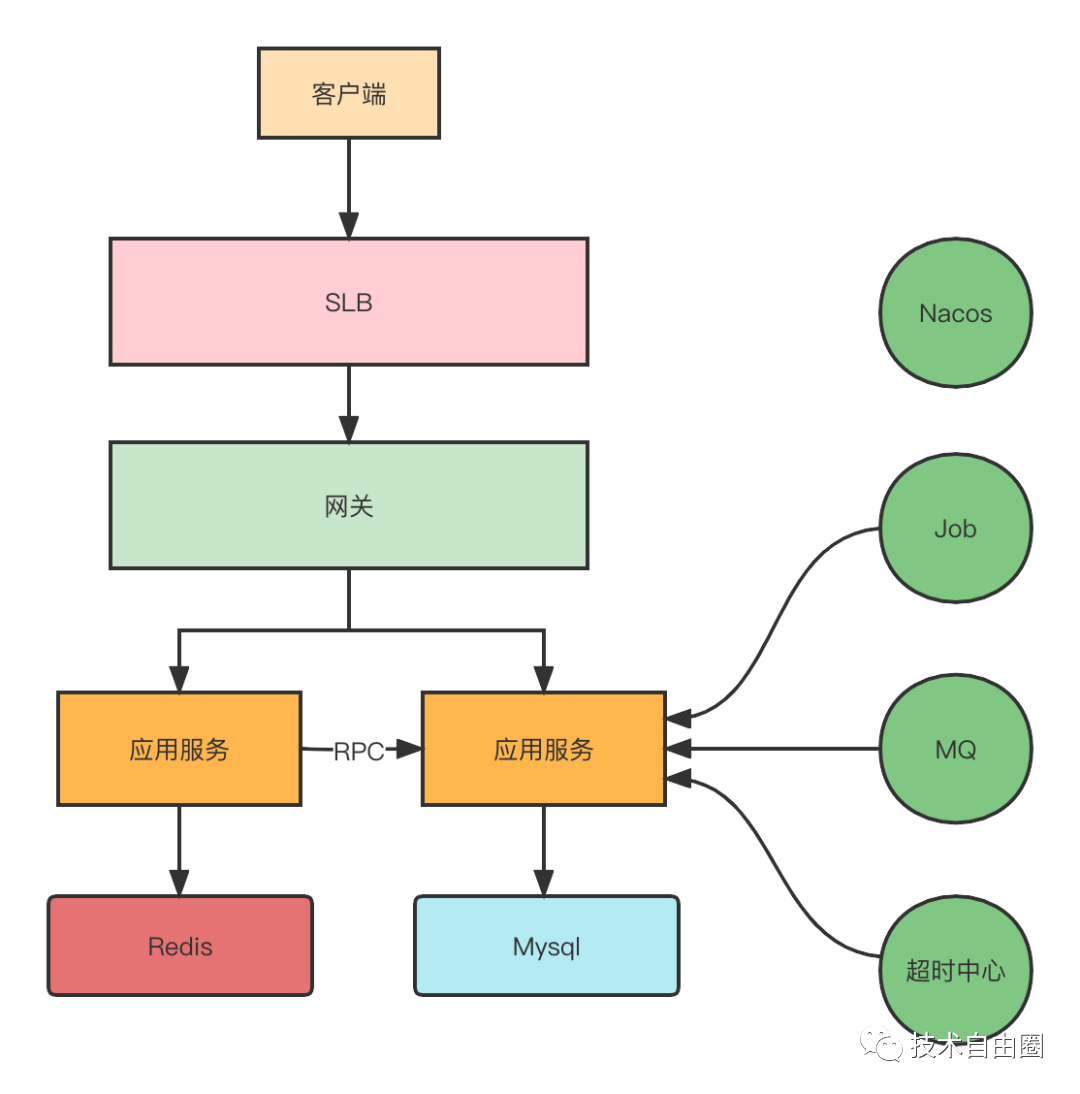
客户端的请求进来会先到SLB(负载均衡),然后到内部的网关,通过网关再分发到具体的业务服务。业务服务会依赖Redis、MySQL、 MQ、Nacos等中间件。
B站点赞中心做异地多活,在不同地区有不同的机房,他们的架构中,有两个机房。所以,他们的接入层的效果如下图所示:
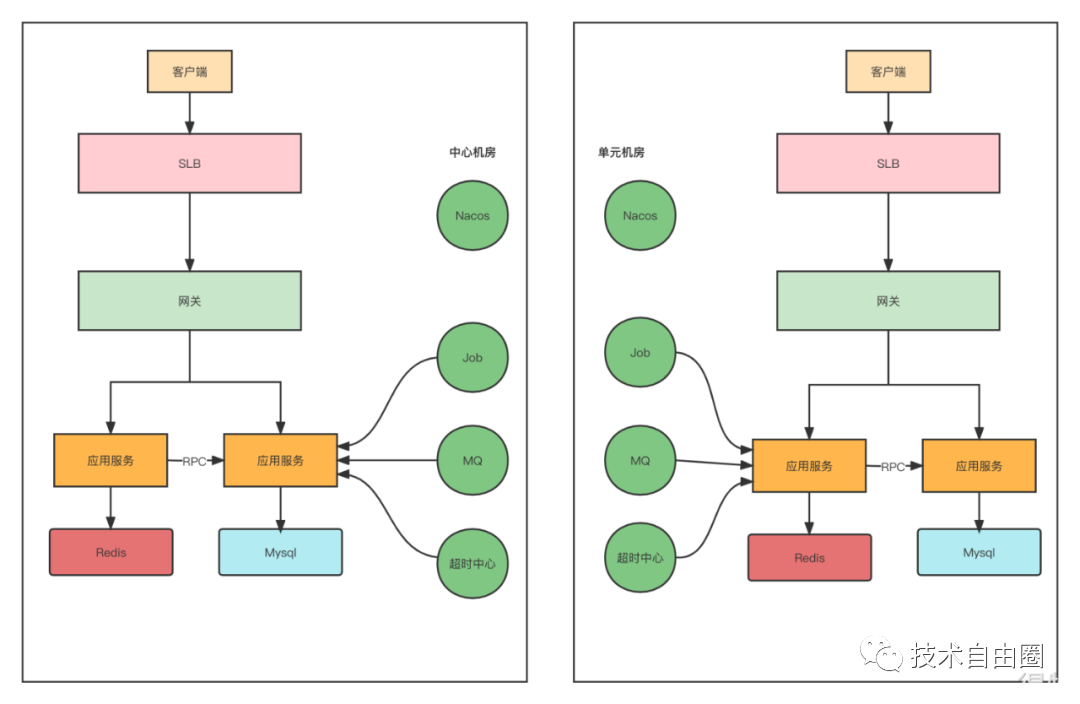
流量路由层
用户的请求,从客户端发出,这个用户的请求该到哪个机房,这是 流量路由层 决定的。
首先,用户需要尽量路由到同一个 机房。为什么呢?虽然服务之间的数据,是没有依赖的,但是服务内部依赖的存储是有状态的。不同的机房之间,虽然有数据同步,但是,毕竟会有延迟。如果用户修改了数据之后,再一查,查不到,感觉非常困惑。
如何 路由到同一个 机房?
首先,使用普通dns是不行的,普通的dns,域名会随机解析到不同的机房中。
一个综合方案:智能DNS+ DLB流量网关
第一个维度是智能DNS,但是智能DNS也不是万能的,需要接入层进行流量矫正。所以针对同一个用户,尽可能在一个机房内完成业务闭环。
流量路由层 为了解决流量调度的问题,可以基于OpenResty二次开发出了DLB流量网关,DLB会对接多活控制中心,能够知道当前访问的用户是属于哪个机房,如果用户不属于当前机房,DLB会直接将请求路由到该用户所属机房内的DLB。
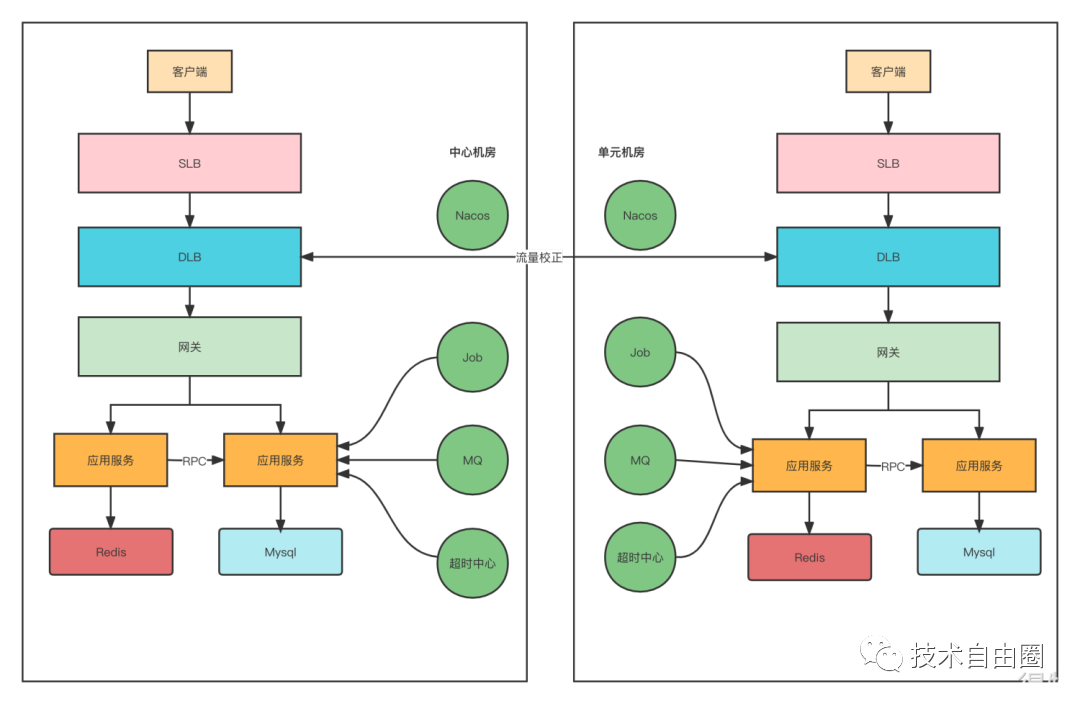
如果每次都随机到固定的机房,再通过DLB去校正,必然会存在跨机房请求,耗时加长。所以在这块也是结合客户端做了一些优化,在DLB校正请求后,可以将用户对应的机房IP直接通过Header响应给客户端。这样下次请求的时候,客户端就可以直接通过这个IP访问。如果用户当前访问的机房挂了,客户端需要降级成之前的域名访问方式,通过DNS解析到存活的机房。
接入层的业务网关
业务网关包括的功能:统一鉴权、反黑灰产等统一流量筛选。
接入层功能之一:统一鉴权
这一层,从架构的维度来说,可以在SpringCloud gateway 中, 使用 过滤器进行 统一鉴权
接入层功能2:流量筛选
黑灰产,又称非法产业、非法企业或非法经济。
所谓网络黑灰产,指的是电信诈骗、钓鱼网站、木马病毒、黑客勒索等利用网络开展违法犯罪活动的行为。稍有不同的是,“黑产”指的是直接触犯国家法律的网络犯罪,“灰产”则是游走在法律边缘,往往为“黑产”提供辅助的争议行为。
流量筛选这一层,从架构的维度来说, 可以在SpringCloud gateway 中, 使用 过滤器进行 风险ip、风险用户id的 动态探测,拦截。
动态探测可以使用成熟的动态探讨框架,如jd的hotkey, 也可以使用滑动窗口算法,实现类似的动态探测组件。
B赞点赞中台的服务层架构
点赞的业务比较简单,性能也可以很高。但是,之后的入库的操作,性能低。所以,采用消息队列进行异步消峰解耦。
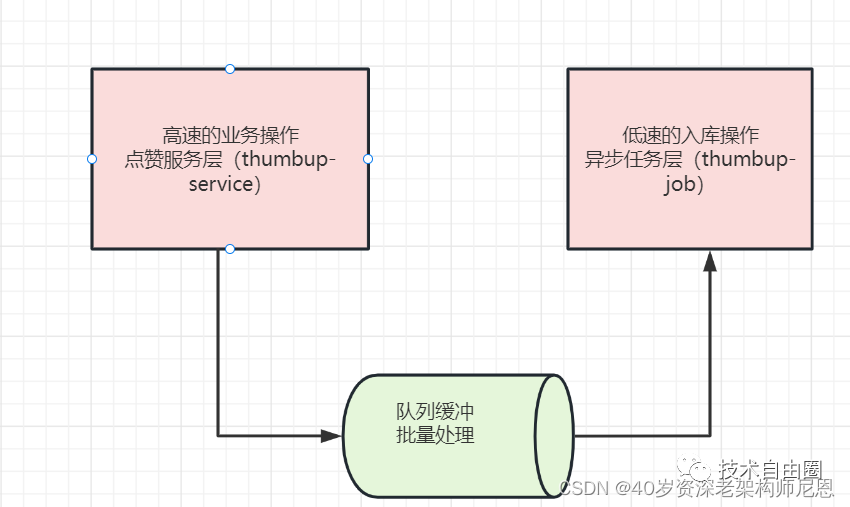
实际上,这里整体用的是异步+批量的架构,异步是一种即为重要的架构模式。B赞点赞中台的服务层架构,细分为两层:
1 点赞服务层
2 异步任务层
点赞服务层(thumbup-service)
点赞服务层接收到用户的点赞请求,完成点赞的业务计算:
-
点赞数
-
点赞状态
-
点赞列表
-
等等
具体的功能,参考下图
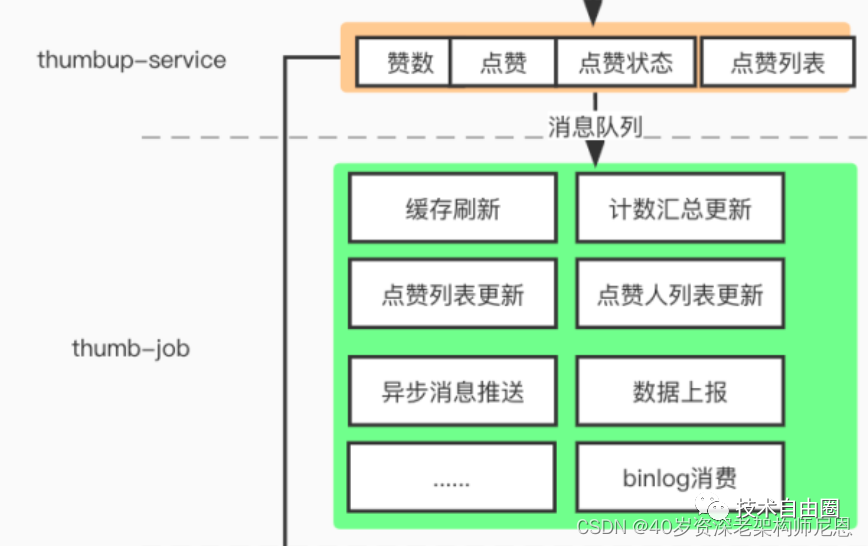
异步任务层(thumbup-job)
异步任务主要作为点赞数据写入、刷新缓存、为下游其他服务发送点赞、点赞数消息等功能
-
点赞数据写入:含用户行为数据(点赞、点踩、取消等)的写入
-
缓存刷新:点赞状态缓存、点赞列表缓存、点赞计数缓存
-
同步点赞消息
-
点赞事件异步消息、点赞计数异步消息
首先是最重要的用户行为数据(点赞、点踩、取消等)的写入。搭配对数据库的限流组件以及消费速度监控,保证数据的写入不超过数据库的负荷的同时,也不会出现数据堆积造成的C数据端查询延迟问题。
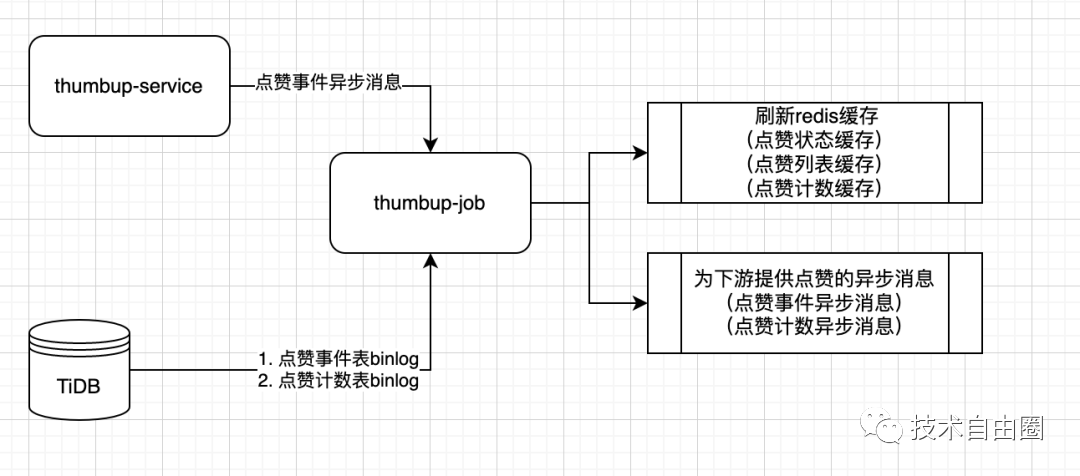
超高流量压力的异步批量处理
超高的全局流量压力:
超高并发读:全站点赞状态查询、点赞数查询等【读流量】超过300k
超高并发写:点赞、点踩等【写流量】超过15K
采用的策略是:异步写入+批量写入
异步写入
同时数据库的写入我们也做了全面的异步化处理,保证了数据库能以合理的速率处理写入请求。
批量写入(聚合写入)
针对写流量,为了保证数据写入性能,B站在写入【点赞数】数据的时候,在内存中做了部分聚合写入,比如聚合10s内的点赞数,一次性写入。
如此可大量减少数据库的IO次数。
B赞点赞中台的数据层架构
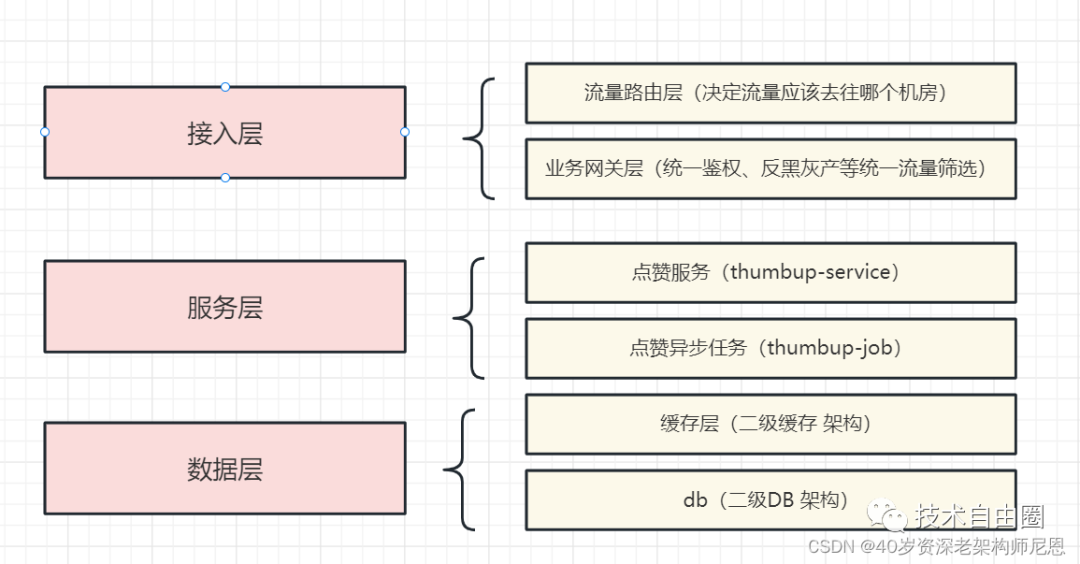
二级缓存架构
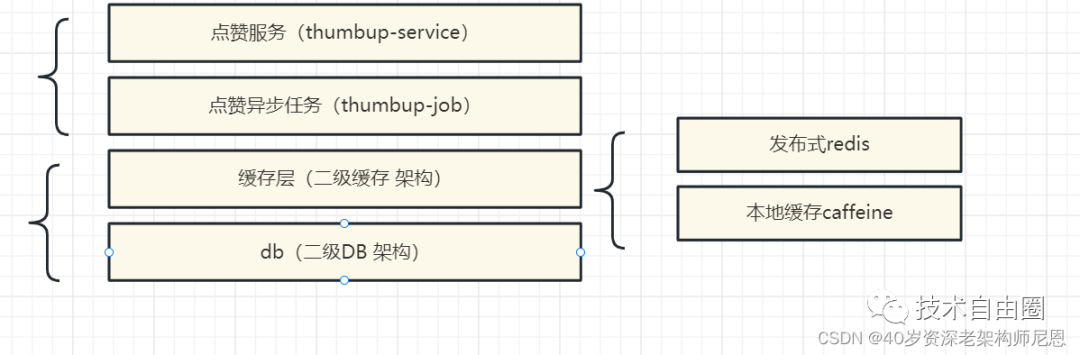
二级缓存:分布式 Cache 缓存架构
缓存层Cache:点赞作为一个高流量的服务,缓存的设立肯定是必不可少的。点赞系统主要使用的是CacheAside模式。
这一层缓存主要基于Redis缓存:以点赞数和用户点赞列表为例。
实体的点赞数的缓存设计
用业务ID和该业务下的实体ID作为缓存的Key,并将点赞数与点踩数拼接起来存储以及更新。
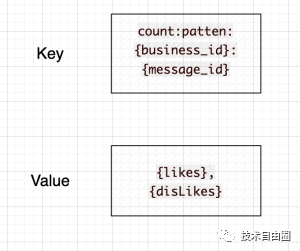
key-value = count:patten:{business_id}:{message_id} - {likes},{disLikes}
business_id 代表 业务id
message_id 代表 实体 id
用户的点赞列表缓存设计
一个用户,在一个业务下的 所有点赞 的列表
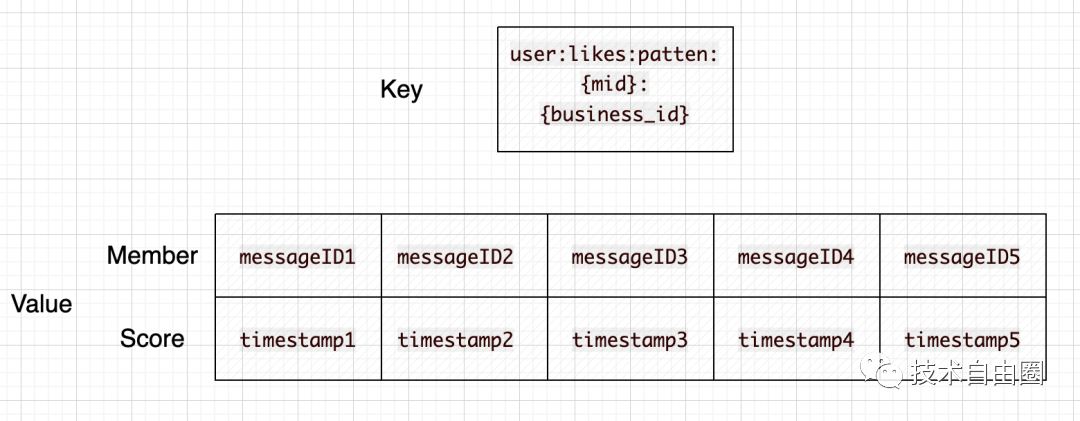
key = user:likes:patten:{mid}:{business_id}
value = zset , member(messageID)-score(likeTimestamp)
key为mid与业务ID,mid代表用户,business_id代表业务id。value则是一个ZSet,member为被点赞的实体ID,score为点赞的时间。
当该业务下某用户有新的点赞操作的时候,被点赞的实体则会通过 zadd 的方式,把最新的点赞记录加入到该ZSet里面来。
为了维持用户点赞列表的长度(不至于无限扩张),需要在每一次加入新的点赞记录的时候,按照固定长度裁剪用户的点赞记录缓存。
该设计也就代表用户的点赞记录在缓存中是有限制长度的,超过该长度的数据请求需要回源DB查询。
一级本地存储架构
LocalCache - 本地缓存
本地缓存的建立,目的是为了应对缓存热点问题。 本地缓存主要解决缓存击穿的问题。
在Java应用中,本地缓存建议选用命中率最高的caffeine组件, 其内存淘汰算法 wtiny-lfu,集合了 lrf与lfu的精华。
热点探测
热门事件、稿件等带来的系统热点问题,包括DB热点、缓存热点。当一个稿件成为超级热门的时候,大量的流量就会涌入到存储的单个分片上,造成读写热点问题。此时需要有热点探测机制来识别该热点,并将数据缓存至本地,并设置合理的TTL。
例如,UP主 【杰威尔音乐】发布第一个稿件的时候就是一次典型热点事件。所以,本地缓存一般要结合热点探讨框架使用。
二级DB架构

结构化DB+NoSql结合的二级架构模式:
-
结构化DB,为业务计算提供数据支撑,如mysql、tidb等等
-
NoSql DB,提供历史数据支撑,全量数据支撑,大数据计算支撑,如hbase,mongdb等
B站的二级DB架构,也是这种经典的二级架构。
结构化数据存储
基本数据模型:
-
点赞记录表:记录用户在什么时间对什么实体进行了什么类型的操作(是赞还是踩,是取消点赞还是取消点踩)等
-
点赞计数表:记录被点赞实体的累计点赞(踩)数量
①、第一层存储:DB层 - (TiDB)
点赞系统中最为重要的就是点赞记录表(likes)和点赞计数表(counts),负责整体数据的持久化保存,以及提供缓存失效时的回源查询能力。
表1:点赞记录表 - likes
字段:用户Mid、被点赞的实体ID(messageID)、点赞来源、时间 等等
索引:联合索引(Mid、messageID ) ,用于满足业务请求。
表2:点赞数表 - counts
字段:业务ID(BusinessID) 、实体ID(messageID) 、实体的点赞数、点踩数等。
索引:以业务ID(BusinessID)+ 实体ID(messageID)为主键
并且按照messageID维度建立满足业务查询的索引。
结构化DB的分库分表方案
由于DB采用的是分布式数据库TiDB,所以对业务上无需考虑分库分表的操作。如果选用mysql,可以使用 shardingjdbc 进行客户端分片的计算,这种方案,非常普遍。
NoSql解决全量数据的数据存储压力
点赞数据的规模:超过千亿级别
如何高效的利用存储介质存放这些数据才能既满足业务需求,也能最大程度节省成本,也是一个点赞服务正在努力改造的工程 - KV化存储。
针对TIDB海量历史数据的迁移归档。迁移归档的原因(初衷),是为了减少TIDB的存储容量,节约成本的同时也多了一层存储,可以作为灾备数据。
作为一个典型的大流量基础服务,点赞的存储架构需要最大程度上满足两个点。
①最大的可靠性:满足业务读写需求的同时具备最大的可靠性
②最小化存储成本: 选择合适的存储介质与数据存储形态,最小化存储成本
从以上两点出发,考虑到KV数据在业务查询以及性能上都更契合点赞的业务形态,选用 TaiShan(B站自研的KV数据库) 作为NoSql的存储方案。
数据一致性架构
采用的是非常经典的 cannal+binlog的架构,具体如下:
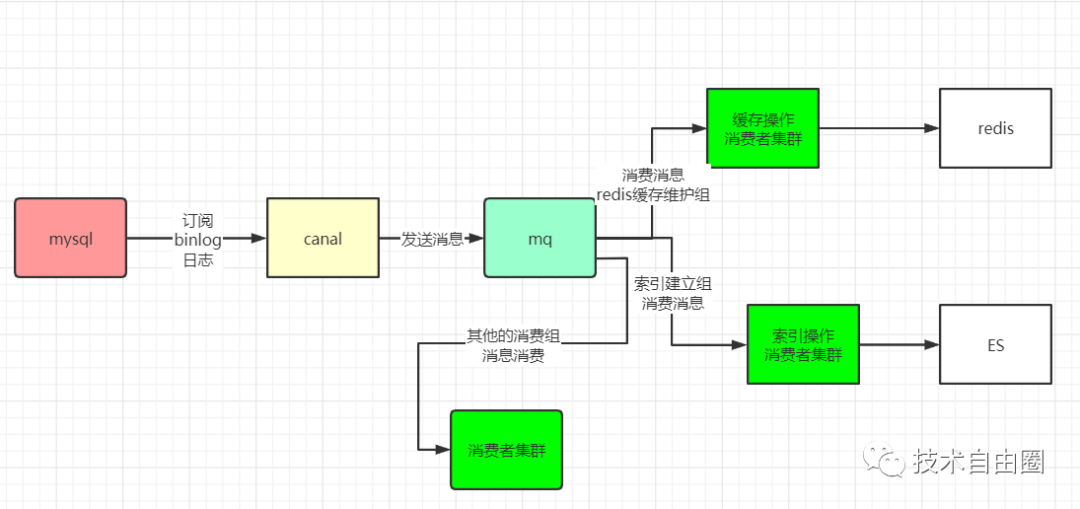
容灾架构
1、存储不可用
-
例如当DB不可用时,需要依托缓存尽可能提供服务。
-
同理当缓存不可用时,DB也需要保证自己不宕机的情况下尽可能提供服务。
2、消息队列不可用
-
当消息队列不可用时,依托B站自研的railgun,通过RPC调用的方式自动降级
3、机房灾难
-
切换机房, 通过流量路由层实现
4、数据同步容灾
比如点赞就遇到过因为cannal+binlog的数据同步问题(断流、延迟)导致的点赞计数同步延迟问题。
5、服务层的容灾和降级
1、存储(db、redis等)的容灾设计(同城多活)
作为面对C端流量的直接接口,在提供服务的同时,需要思考在面对各种未知或者可预知的灾难时,如何尽可能提供服务。
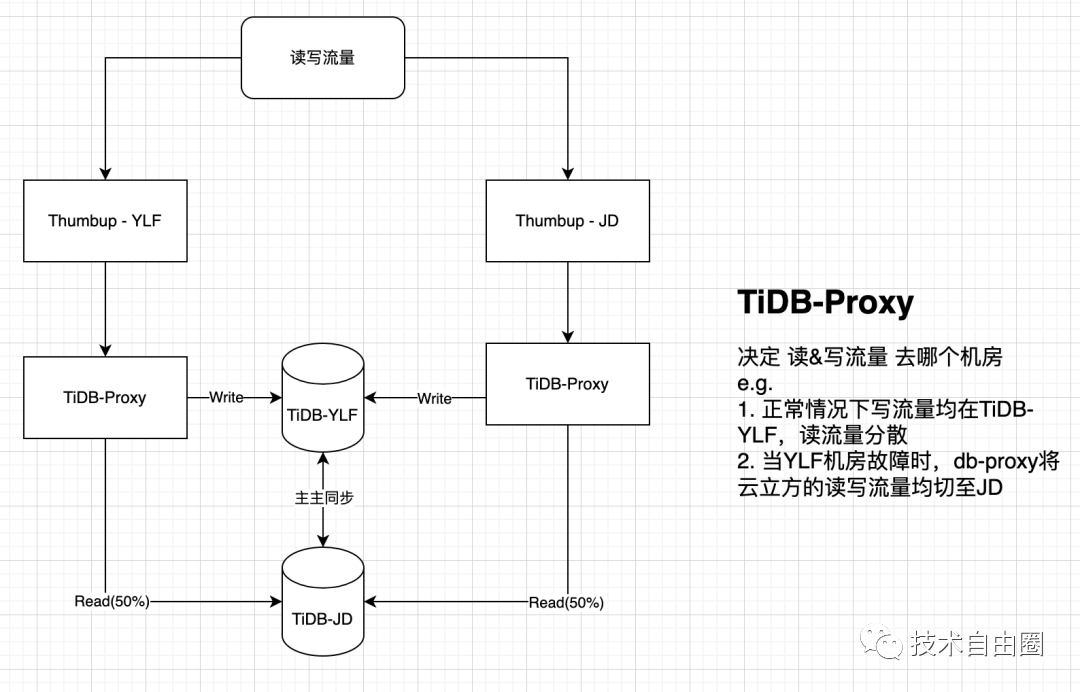
在DB的设计上,点赞服务有两地机房互为灾备,设计专用的proxy代理层,db-proxy(sidecar), 业务通过db-proxy(sidecar)访问 redis和db。
正常情况下,机房1承载所有写流量与部分读流量,机房2承载部分读流量。当DB发生故障时,通过db-proxy(sidecar)的切换可以将读写流量切换至备份机房继续提供服务。
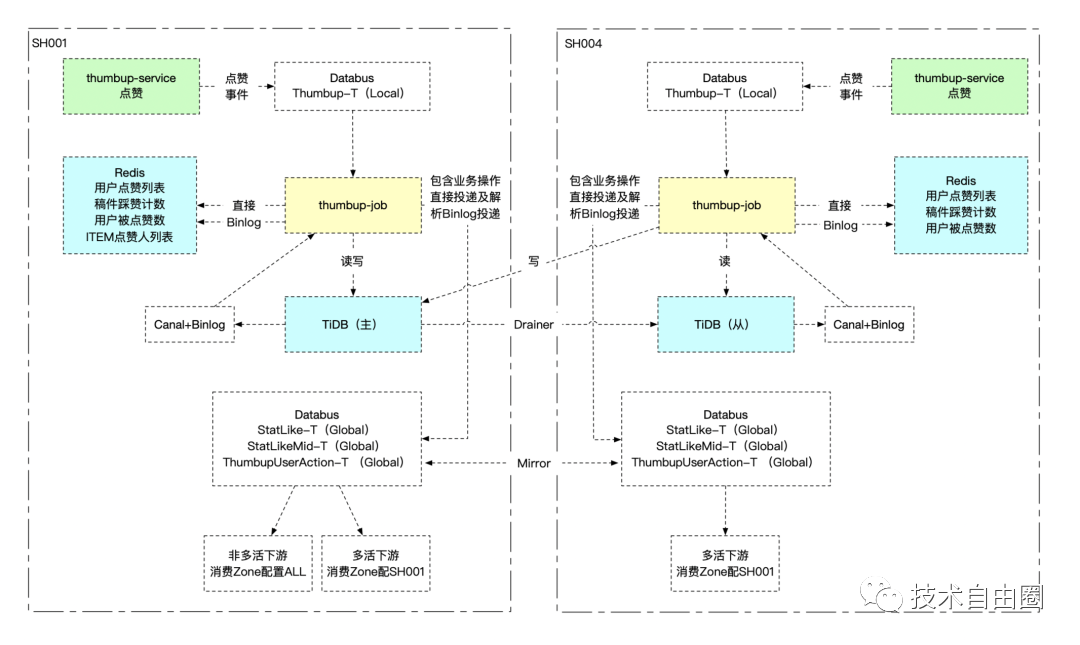
在缓存(Redis)上,点赞服务也拥有两套处于不同机房的集群,并且通过异步任务消费TiDB的binLog维护两地缓存的一致性。可以在需要时切换机房来保证服务的提供,而不会导致大量的冷数据回源数据库。
2、数据同步容灾
点赞job对binLog的容灾设计
由于点赞的存储为TiDB,且数据量较大。在实际生产情况中,binLog会偶遇数据延迟甚至是断流的问题。为了减少binLog数据延迟对服务数据的影响。服务做了以下改造。
-
监控:
首先在运维层面、代码层面都对binLog的实时性、是否断流做了监控
-
应对
脱离binlog,由业务层(thumb-service)发送重要的数据信息(点赞数变更、点赞状态事件)等。
当发生数据延迟时,程序会自动同时消费由thumbup-service发送的容灾消息,继续向下游发送。
3、服务层的容灾与降级
以点赞数、点赞状态、点赞列表为例,点赞作为一个用户强交互的社区功能服务,对于灾难发生时用户体验的保证是放在第一位的。所以针对重点接口,B站都会有兜底的数据作为返回。
多层数据存储互为灾备
-
点赞的热数据在redis缓存中存有一份。
-
kv数据库中存有全量的用户数据,当缓存不可用时,KV数据库会扛起用户的所有流量来提供服务。
-
TIDB目前也存储有全量的用户数据,当缓存、KV均不可用时,tidb会依托于限流,最大程度提供用户数据的读写服务。
-
因为存在多重存储,所以一致性也是业务需要衡量的点。
-
首先写入到每一个存储都是有错误重试机制的,且重要的环节,比如点赞记录等是无限重试的。
-
另外,在拥有重试机制的场景下,极少数的不同存储的数据不一致在点赞的业务场景下是可以被接受的
多地方机房互为灾备
-
点赞机房、缓存、数据库等都在不同机房有备份数据,可以在某一机房或者某地中间件发生故障时快速切换。
点赞重点接口的降级
-
点赞数、点赞、列表查询、点赞状态查询等接口,在所有兜底、降级能力都已失效的前提下也不会直接返回错误给用户,而是会以空值或者假特效的方式与用户交互。
-
后续等服务恢复时,再将故障期间的数据写回存储。
架构的演进方向
架构方案,没有最优,只有更优。 B站的点赞中台后续的演进方向大致为:
1、点赞服务单元化:要陆续往服务单元化的方向迭代、演进。
2、点赞服务平台化:在目前的业务接入基础上增加迭代数据分库存储能力,做到服务、数据自定义隔离。
如何保障 MySQL 和 Redis 数据一致性?
什么是Cache-Aside Pattern(旁路缓存模式)?
Cache-Aside Pattern(旁路缓存)模式,又叫旁路路由策略,在这种模式中,读取缓存、读取数据库和更新缓存的操作都是在应用程序中完成。此模式是业务系统最常用的缓存策略。
旁路缓存又模式分为读缓存和写缓存。
旁路缓存模式在读的时候,先读缓存,缓存命中的话,直接返回数据;如果缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
Cache-Aside Pattern(旁路缓存)模式读操作流程,具体如下:
-
step 1:应用程序接收用户的数据查询的请求;
-
step 2:应用程序优先从缓存查找数据;
-
step 3:如果存在(cache hit),从缓存上查询出来,返回查询到数据;
-
Step 4:如果不存在(cache miss),从数据库中查询数据并存入缓存中,返回查询到数据。
Cache-Aside Pattern(旁路缓存)模式读操作流程,具体如下图所示:
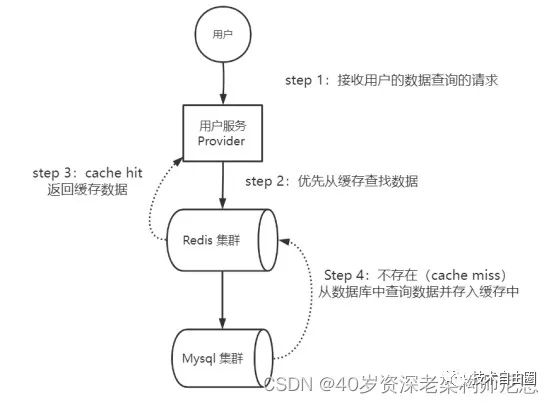
图:Cache-Aside Pattern(旁路缓存)模式读操作流程
Cache-Aside Pattern(旁路缓存)模式写操作流程,具体如下:
-
step 1:接收用户的数据写入的请求;
-
step 2:先写入数据库;
-
step 3:再写入缓存。
Cache-Aside Pattern(旁路缓存)模式写操作流程,具体如下图所示:
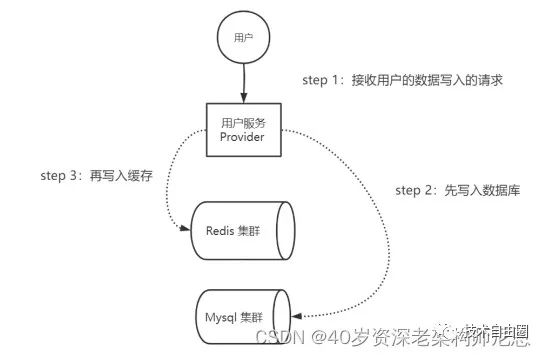
图:Cache-Aside Pattern(旁路缓存)模式写操作流程
数据什么时候从数据库(如MySQL集群)加载到缓存(如Redis集群)呢?有以下两种加载模式可被选择:懒汉模式、饿汉模式。懒汉模式、饿汉模式可以理解为及时加载模式、延迟加载模式。
所谓懒汉模式,就会在使用时临时加载缓存。具体来说,就是当需要使用数据时,就从数据库中把它查询出来,然后写入缓存。第一次查询之后,后续的请求都能从缓存中查询到数据。
所谓饿汉模式,就是提前预加载缓存。具体来说,在项目启动的时候,预加载数据到缓存。当需要使用数据时,能直接从缓存获取数据,而不需要从数据获取。
饿汉模式,提前预加载数据到缓存的时机,能极大地提升请求处理的性能力,极大地提升系统的吞吐量。此模式,适合于缓存那些不是经常变更的数据(例如商品类目数据),或者那些访问非常频繁的极热数据(例如秒杀商品数据)。
懒汉模式、饿汉模式这组名词来自于Java的单例模式。
Cache-Aside如何保证双写的数据一致性?
Cache-Aside是日常开发中使用最多的缓存层高并发访问模式。Cache-Aside在写入的时候,为什么是删除缓存而不是更新缓存?Cache-Aside如何保证DB和Cache双写的数据一致性?
要完美的回答这个问题,把Cache-Aside模式(旁路缓存模式)下的DB和Cache双写的策略,做一个系统化的梳理,大概分为如下五大策略。
-
策略一:先更数据库,再更缓存
-
策略二:先删缓存,再更新数据库
-
策略三:先更数据库,再删缓存
-
策略四:延迟双删策略
-
策略五:逻辑删除策略
-
策略六:先更数据库,再基于队列删缓存
策略一:先更数据库,再更缓存
在实际的业务场景中,一种常见的并发场景是:微服务Provider实例A、B同时进行同一个数据的更新操作。按照先更数据库,再更缓存的策略,则微服务Provider实例A、B可能会出现下面的执行次序:
-
step 1:微服务A去执行update DB
-
step 2:微服务B去执行update DB
-
step 3:微服务B去执行update Cache
-
step 4:微服务A去执行update Cache
上面的执行流程,具体如下图所示:
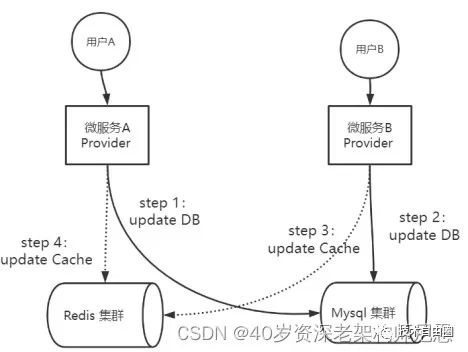
图:先更数据库,再更缓存的并发执行案例
上面的执行流程,是典型的并发写入场景。在图中的并发写入的场景中,Provider A进行数据的写入,Provider B也进行数据的写入。最终的结果是:DB中的数据是Provider B的数据,Cache中的数据是Provider A的数据,出现DB和Cache数据不一致问题。
具体的原因是:Provider B的更新在Cache中的数据,被Provider A的更新在Cache中的数据覆盖了。DB的更新次序先A后B,理论上Cache中的数据更新也应该是先A后B。理论上,最终Cache中的数据应该是Provider B的数据,而不是Provider A的数据。所以,在流程执行完毕后,缓存中的Provider A的数据为脏数据。
而之出现这个问题,是因为以上流程中step 3与step 4的执行均为操作缓存,都是高并发的操作,很难保证先后次序,所以缓存出现脏数据的概率很大。
为何不更新缓存而是删除缓存?
一个非常高频的问题是:Cache-Aside在写入的时候,为什么是删除缓存而不是更新缓存呢?
回到上一节的例子,在图中的并发写入的场景中,Provider A进行数据的写入,Provider B也进行数据的写入。
在这个例子中,写入DB的次序如下:
-
Provider A先发起一个写操作,第一步先更新数据库
-
Provider B再发起一个写操作,第二步更新了数据库
现在,由于分布式系统,无法保证并发操作的有序性,写入Cache的次序可能如下:
-
Provider B先发起一个Cache写操作,第一步先更新Cache
-
Provider A再发起一个Cache写操作,第二步更新了Cache
这时候,Cache保存的是Provider A的数据(老数据),DB保存的是B的数据(新数据),于是发生了DB和Cache数据不一致,Cache中出现脏数据。
如果使用删除操作取代更新操作,则Cache不会出现上面的脏数据问题。具体如下图所示:
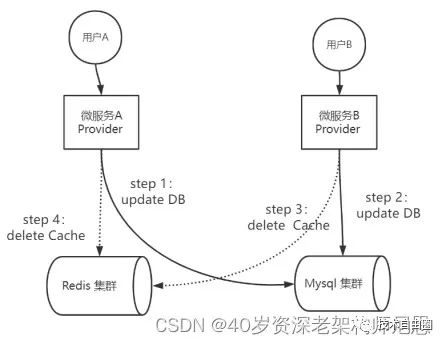
图:为何不更新缓存而是删除缓存
除了能够减少脏数据之外,更新缓存相对于删除缓存,还有两点劣势:
(1)如果写入Cache的值,是经过复杂计算才得到的话。更新缓存频率高的话,就会大大降低性能。
(2)及时更新缓存属于饿汉模式,适用于数据读取高频的场景。在写多读少的情况下,数据很多时候还没被读取到,又被更新了,这也浪费了Cache的空间,也降低了性能。
策略二:先删缓存,再更新数据库
在实际的业务场景中,一种常见的并发场景是:微服务Provider实例A进行数据的写入,而服务Provider实例 B同时进行同一个数据的读取操作。按照先删缓存,再更新数据库的策略,则微服务Provider实例A、B可能会出现下面的执行次序:
-
step 1:微服务A去执行delete Cache
-
step 2:微服务B去执行load from DB
-
step 3:微服务B去执行update Cache
-
step 4:微服务A去执行update DB
上面的执行流程,具体如下图所示:
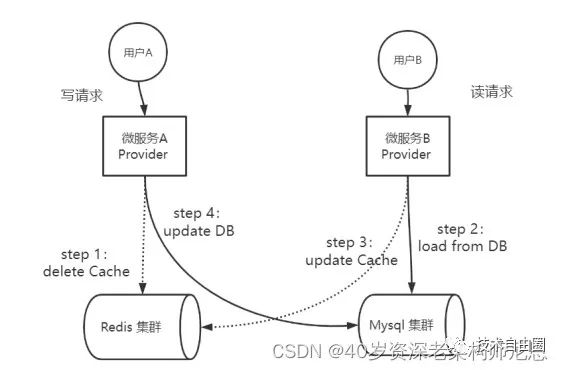
图:先删缓存,再更新数据库的并发执行案例
上面的执行流程,是典型的并发读写场景。在图中的并发读写的场景中,Provider A进行数据的写入,Provider B进行数据的查询。最终,DB中的数据是Provider A的更新数据,Cache中的数据是Provider B从DB加载的数据,而这个数据已经过时,出现DB和Cache数据不一致问题。
具体的原因是:Provider B查询Cache的时候,Cache中的数据被删除,Provider B只能去DB查找,然后将数据更新在Cache。而Provider A在Provider B查完之后,竟然更新了DB,导致了DB和Cache的不一致。
出现这个DB和Cache的不一致问题的根本原因,大致如下:
写操作是先删Cache(操作1)再写DB(操作2),如果在此期间发生并发读,读取的动作很容易发生操作1、操作2的中间,从而读取到过时的数据,最终导致Cache和DB不一致。更为严重的时候,读操作把过期数据刷入Cache后,会导致后面比较长时间的不一致。这个时间,一直持续到缓存过期,如说4个小时(以项目中的配置时间为准)。
上面的Cache和DB不一致,将导致一个严重的后面:后续的读取操作,都会使用Cache中的数据,所以,后面的读取操作都会使用过时数据。
策略三:先更数据库,再删缓存
先更数据库,再删缓存,基本上可以解决并发读写场景中,Cache和DB数据不一致的问题。但是,在一些特殊的场景中,还是会存在数据不一致的问题。
一种非常特殊的并发场景是:
微服务Provider实例A进行数据的写入操作,先写DB(操作1),再删Cache(操作2),如果由于某种原因出现了卡顿,没有及时把数据放入Cache,或者说放入Cache的操作,简单的说,操作2发生了滞后。
此时,服务Provider实例 B进行一个数据的读取操作,读取的次序仍然是先读Cache,再读DB,很容易发生DB和Cache的不一致性。
按照先更数据库,再删缓存的策略,则微服务Provider实例A、B可能会出现下面的执行次序:
-
step 1:微服务A去执行update DB
-
step 2:微服务B去执行load from Cache
-
step 3:微服务A去执行delete Cache,但是发生了延迟
上面的执行流程,具体如下图所示:
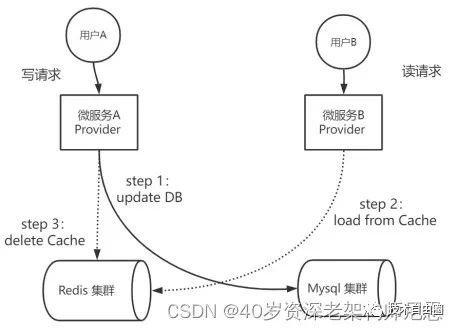
图:先更数据库,再删缓存的并发执行案例
在图中的并发读写的场景中,Provider A进行数据的写入,Provider B进行数据的查询。微服务Provider实例A先写DB(操作1),再删Cache(操作2),如果Provider实例A发生卡顿、或者网络延迟等异常的问题,导致操作2严重滞后。在操作2执行完成之前,DB和Cache的数据是不一致的。
在此期间,其他的数据读取操作,都会读取Cache中的过期数据,出现DB和Cache数据不一致问题。
出现这个DB和Cache的不一致问题的根本原因,大致如下:
写操作是先写DB(操作1)再删Cache(操作2),如果在此期间发生并发读,读操作很容易发生操作1、操作2的中间,从而,并发读操作从Cache读取到过时的数据,最终导致Cache和DB不一致。
但是等到写操作删除Cache(操作2)的动作执行完成之后,Cache和DB的数据,会恢复一致性。
无论如何,策略三(先写DB再删Cache),比策略二(先删Cache再写DB)发生数据不一致的时间短。相比较而言,推荐大家使用策略三,而不是策略二。
那么,策略三的问题是啥呢?
(1)写DB(操作1)和删Cache(操作2)之间,存在短时间的数据不一致;
(2)如果删Cache失败,存在较长时间的数据不一致,这个时间会一直持续到Cache过期;
如何解决策略三中Cache删除失败所导致的DB和Cache较长时间的数据不一致呢?可以使用策略四:延迟双删。
策略四:延迟双删策略
什么是延迟双删呢?延迟双删是基于策略二进行改进,就是先删Cache,后写DB,最后延迟一定时间,再次删Cache。
在实际的业务场景中,一种常见的并发场景是:微服务Provider实例A进行数据的写入,而服务Provider实例 B同时进行同一个数据的读取操作。按照先删Cache,后写DB,最后延迟一定时间,再次删Cache策略,则微服务Provider实例A、B可能会出现下面的执行次序:
-
step 1:微服务A去执行delete Cache
-
step 2:微服务B去执行load from DB
-
step 3:微服务B去执行update Cache
-
step 4:微服务A去执行update DB
-
step 5:微服务A去执行 delay delete Cache
上面的执行流程,具体如下图所示:
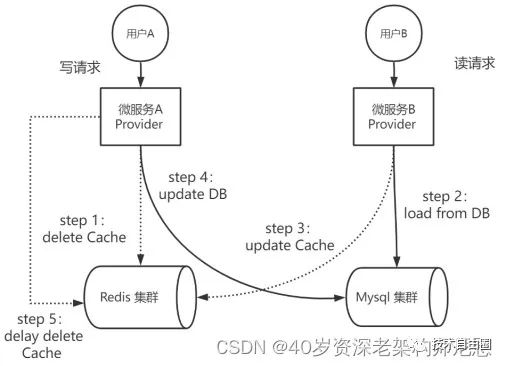
图:先删Cache,后写DB,再次延迟删Cache的并发执行案例
在图中的并发读写的场景中,Provider A进行数据的写入,Provider B进行数据的查询。微服务Provider实例A先删Cache(操作1),再写DB(操作2),最后再二次延迟删除Cache(操作3)。在操作2之前,如果发生并发读,从DB读取到过时数据,可能出现DB和Cache数据不一致问题。
出现这个DB和Cache的不一致问题的根本原因,大致如下:
写操作是先删Cache(操作1)再写DB(操作2),如果在此期间发生并发读,读操作容易发生操作1、操作2的中间,从DB读到过时数据,最终导致Cache和DB不一致。但是,这一轮的数据不一致,持续时间不会太长。为啥呢?写操作还有一个兜底的动作:二次延迟删除Cache(操作3),从而保证数据一致。
所以,延迟双删也会存在数据不一致,不过是持续时间比较短而已。
那么,策略四的问题是啥呢?
(1)如果写操作比较频繁,可能会对Redis造成一定的压力;
(2)极端情况下,第二次延迟删Cache失败,操作的效果退化到策略二。DB和Cache存在较长时间的数据不一致,这个时间会一直持续到Cache过期,比如说4个小时(以项目中的配置时间为准)。
如何解决策略四的以上两个问题呢?可以使用策略五:先更数据库,再基于队列删缓存。
策略五:逻辑删除/逻辑过期的问题
首先什么是逻辑过期时间呢。逻辑代表什么,假的删除,不是真正的删除。而是空间换时间,设置一些额外的标志。
比如:在存储数据的时候加个字段,比如 logicExpireTime 给它设置值。这个值,跟我们缓存key的有效时间肯定不一样。比如,永不过期。比如,当前时间再加上 几个小时 转为时间戳的方式跟数据一起存入redis。
逻辑过期时间 = 业务过期时间
物理过期时间 = 逻辑过期时间 + 高并发冗余时间
查询的时候,检查 logicExpireTime ,如果发现到时间了,另外有一个缓存的重建线程,进行异步重建。更新的时候, 更改逻辑过期时间 = 当前时间
策略六:先更数据库,再基于队列删缓存
来到策略六:先更数据库,再基于队列删缓存。那么,如何基于任务队列删缓存呢?实质上,策略六是基于策略三进行改进。首先回顾一下策略三的问题?
(1)写DB(操作1)和删Cache(操作2)之间,存在短时间的数据不一致;
(2)如果删Cache失败,存在较长时间的数据不一致,这个时间会一直持续到Cache过期;
策略六主要的操作次序,和策略三保持一致,依然是先写DB后删除Cache。不同的是,策略六引入队列,把删Cache的操作加入队列,后台会有一个异步线程、或者进程去异步消费队列中的删除任务,去执行删Cache的操作。
基于队列删缓存,可以细分为:
-
第1种细分的方案:基于内存队列删除缓存
-
第2种细分的方案:基于消息队列删除缓存
-
第3种细分的方案:基于binlog+消息队列删除缓存
首先来看第一种细分的方案:基于内存队列删除缓存。
此策略把删Cache的操作加入任务队列,后台会有一个异步线程去异步消费任务队列里面的删除任务,去执行删Cache的操作,如果缓存删除失败,可以重试多次,确保删除成功。
在实际的业务场景中,一种常见的并发场景是:微服务Provider实例A进行数据的写入,而服务Provider实例 B同时进行同一个数据的读取操作。Provider实例A先写DB,然后将删Cache加入任务队列;Provider实例 B则是先读缓存,没有数据再读DB。微服务Provider实例A、B可能会出现下面的执行次序:
-
step 1:微服务A去执行update DB
-
step 2:微服务A将delete Cache操作进入任务队列
-
step 3:微服务B去执行load from Cache
-
step 4:消费线程从任务队列提取delete Cache操作,执行删除Cache的操作,直到删除成功。
上面的执行流程,具体如下图所示:
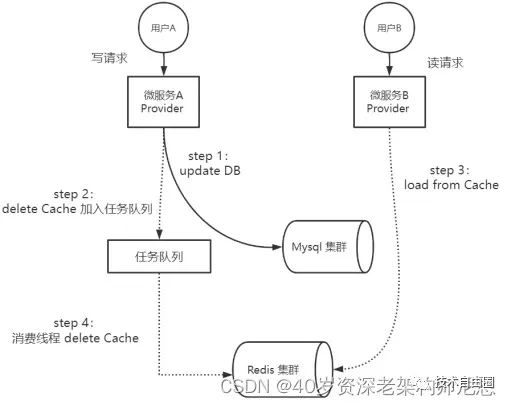
图:先更数据库,后基于内存队列删缓存的并发执行案例
在图中的并发读写的场景中,Provider A进行数据的写入,Provider B进行数据的查询。微服务Provider实例A先写DB(操作1),再将删Cache操作加入任务队列(操作2)。在删除Cache操作真正执行完成之前,其他的数据读取操作,都会读取Cache中的过期数据,出现DB和Cache数据不一致问题。但是这种不一致,是短暂的。任务队列的消费线程,会异步执行删除Cache的任务,并且会不断重试确保成功,删除Cache之后,DB和Cache数据不一致问题就会得到解决。
说 明
保存删除Cache任务的队列,建议使用阻塞队列。任务队列的消费线程,可参考Rocketmq源码中的ServiceThread异步服务线程,其设计思想和执行性能都非常优越。
策略六也会出现这个DB和Cache的不一致问题,尤其是如果写操作非常频繁,队列的任务比较多,可能消费会比较慢,导致DB和Cache的不一致的时间会延长。在这种情况下,可以根据任务队列的拥塞程度,开启多个线程,提升并发执行的效率。
与策略四相比,策略六的优势是:
(1)在写操作比较频繁的场景,策略四有两次删Cache操作,可能会对Redis造成一定的压力;策略六只有一次删Cache操作,Redis压力小一半。
(2)策略四如果删Cache失败,没有引入重试策略;策略六会多次重试,确保删Cache成功,如果重试多次仍然不成功,可以执行运维预警。
(3)策略四将写DB、删Cache这两个操作耦合在了一起,没有很好的做到单一职责;策略六将写DB、删Cache两个操作解耦,模块职责更加单一。
那么,策略六的问题是啥呢?
(1)如果写操作非常频繁,队列的任务比较多,可能消费会比较慢;需要引入多线程机制,加快消费速度。
(2)程序复杂度成倍上升,引入消费线程、任务队列,并且还需要不断进行性能优化。
(3)内存队列是JVM进程的内部队列,如果JVM崩溃,内存队列没有来得及处理的Cache记录删除任务会丢失,这些数据的Cache记录和DB记录会长时间不一致。
其次,来看第二种细分的方案:基于消息队列删除缓存。
在前面的第一种细分方案中,将删除Cache的任务保存在内存队列,并不是高可靠的。
为了保证高可靠的删除Cache记录,这里引入高可用的独立组件—Rocketmq消息队列。需要注意的是,这里引入的RocketMq消息队列是高可用的类型消息队列,不是单节点的类型消息队列,从而保障消息记录的高可用,保障Cache的删除操作只要没有被执行成功,就不会丢失。
引入高可用RocketMq消息队列之后,执行双写操作的Provider A的操作流程,有小幅度的调整。Provider A需要将删除Cache的操作,序列化成Rocketmq消息,然后写入高可用Rocketmq消息队列中间件即可。然后,由专门的消费者(Cache Delete Consumer)进行消息的消费,根据消息内容执行Cache记录删除工作。
DB和Redis双写的场景下,Provider A先更数据库,后基于消息队列删缓存的并发执行案例的执行流程,具体如下图所示:
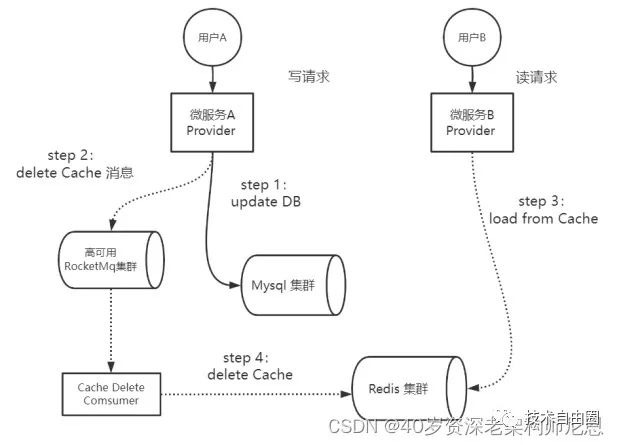
图:先更数据库,后基于消息队列删缓存的并发执行案例
引入高可用的独立组件RocketMq消息队列之后,Provider A的写入逻辑变得很简单,删Cache的时候,只需要发送消息到RocketMq即可,大大简化了Provider A程序的写入逻辑。只是为了保证消息的高可靠传递,这里Provider A在发送消息的时候,需要使用同步发送模式,而不能使用异步发送的模式。
在消息投递的环节,由RocketMq高可用组件的ACK机制保证消息的高可靠投递。如果消息第一次消费失败,RocketMq会重复多次进行投递,确保消息被正常消费,如果一直不能被成功消费,在重复投递一定的次数之后(默认16次),消息会进入死信队列。系统的监控程序会对死信队列进行监控,一旦发现死信消息,监控程序会进行运维告警,由运维人员解决最终的缓存删除问题。除非Redis集群崩溃,一般都不会出现这样的极端情况。
和基于内存队列删除缓存,基于消息队列删除缓存的方案的优势是:增加了Cache删除的可靠性,避免了因JVM崩溃所导致的内存队列中的记录丢失的问题。
那么,Provider在执行DB和Cache双写时,能不能进一步减少双写的负担,将发送删除Cache消息的操作,从双写逻辑中剥离,交给其他的组件去完成呢?答案是可以的。具体来说,就是使用基于基于binlog+消息队列去删除Cache的方案。
最后,来看第三种细分的方案:基于binlog+消息队列删除缓存。
以MySQL为例,可以使用阿里的Canal中间件,采集在数据写入MySQL时生成的binlog日志,然后将日志发送到RocketMq队列。在消费端,可以编写一个专门的消费者(Cache Delete Consumer)完成缓存binlog日志订阅,筛选出其中的更新类型log,解析之后进行对应Cache的删除操作,并且通过RocketMq队列ACK机制确认处理这条更新log,保证Cache删除能够得到最终的删除。
DB和Redis双写的场景下,Provider A先更数据库,后基于基于binlog+消息队列删除缓存的并发执行案例的执行流程,具体如下图所示:
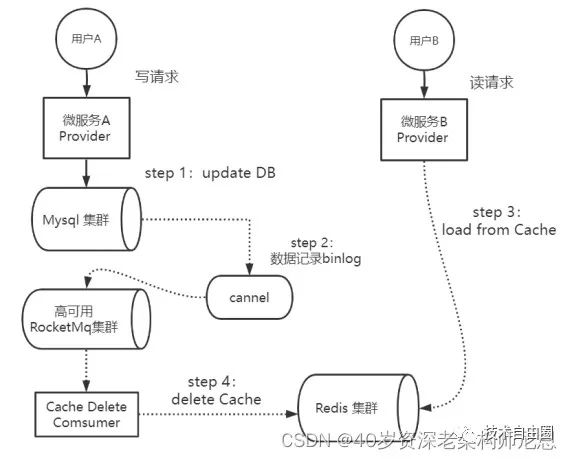
图:先更数据库,后基于消息队列删缓存的并发执行案例
基于binlog+消息队列去删除Cache的方案的优势是:
微服务Provider在执行DB和Cache双写时,只需要执行写入DB的操作就可以了,大大简化了微服务Provider的业务逻辑。Cache的删除工作已经完全被Canal、RocketMq、专门的消费者(Cache Delete Consumer)三者相互结合去接管了。
如何选型呢?
这么多的Cache-Aside如何保证双写的数据一致性方案,改如何选型呢?只有更合适、没有最合适。根据项目和团队的情况选择最合适的。
基于队列的方案,主要有两种:
-
第2种细分的方案:基于消息队列删除缓存
-
第3种细分的方案:基于binlog+消息队列删除缓存
从CAP视角分析DB与Cache的数据一致性
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
-
一致性(Consistency)
-
可用性(Availability)
-
分区容错性(Partition tolerance)
分布式系统最多满足其中的两个特性:要么满足CA,要么CP,要么AP,无法同时满足CAP。也就是说AP和CP是一组天敌,要满足AP高性能,只能舍弃CP。
在DB和Cache的分布式架构中,加入分布式Cache的目的是为了获得高性能、高吞吐,就是为了获得分布式系统的AP特性。所以,如果需要数据库和缓存数据保持强一致(强CP特性),就不适合使用缓存。所以,从CAP的理论出发,使用缓存提升性能,就是会有数据更新的延迟,就会产生数据的不一致。
使用分布式Cache,可以通过一些方案优化,保证弱一致性,最终一致性的。我们只能通过不断的方案迭代,减少不一致性的时间长度。这需要Cache设计时:结合业务仔细思考是否适合用缓存;结合业务仔细思考缓存过期时间。
缓存一定要设置过期时间,这个时间太短、或者太长都不好。
如果过期时间太短,请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。如果过期时间太长,缓存中的脏数据会使系统长时间处于一个延迟的状态,而且,系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
为啥DB和Cache没有办法强一致呢?
主要是写DB和删Cache是两个独立的操作,两个操作并没有保证原子性。如果一定要强CP,就需要非常复杂的低性能方案保证写DB和删Cache两个操作的原子性,比如引入分布式锁,并且需要引入CP类型的Zookeeper分布式锁,或者引入CP类型的Redis RedLock,而不是引入AP类型的普通Redis分布式锁。
所以,如果一定要强CP,就需要非常复杂的低性能方案,有点得不偿失。















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









