







Redis怎么做高可用、高并发架构?
最简单的场景:Redis单机版
首先,我们从最简单的场景开始。
假设目前你正在开发一个业务应用,希望通过引入 Redis 来提升应用的性能。
在这种情况下,你可以选择部署一个单机版的 Redis 来使用,如下图所示:

这个架构非常简单:将 Redis 当做缓存来使用。
一般来讲,都是Cache Aside模式:从 MySQL 中查询数据,然后写入到 Redis 中,接着业务应用再从 Redis 中读取这些数据。
这个架构,也就是我们常用的缓存架构:由于 Redis 的数据都是存储在内存中的,因此这种数据读写速度非常快。
然而,在某一天,由于某些原因,你的 Redis 服务器突然宕机了。
这时你的所有业务流量,都会打到后端 MySQL 上,这会导致你的 MySQL 压力剧增,严重的话甚至会压垮 MySQL。
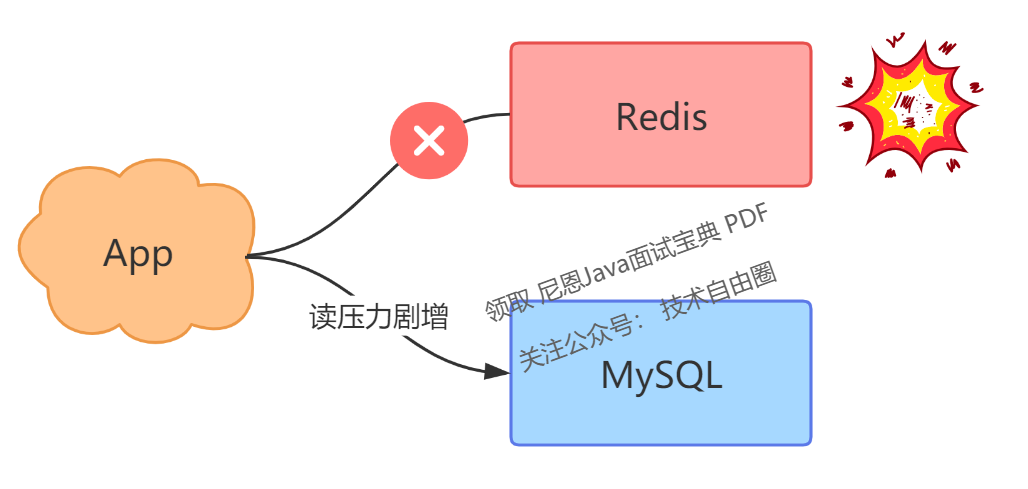
面对这种情况,你会如何应对呢?
首先应对措施是迅速重启 Redis,使其能够重新提供服务。
然而,由于先前 Redis 中的数据都存储在内存里,重新启动了 Redis,之前的数据也都丢失了。
尽管重启后的 Redis 能够正常运行,但由于其中没有任何数据,业务流量仍然会被导向后端 MySQL,导致 MySQL 的压力依然巨大。
面对这种困境,你该如何是好?你陷入了沉思。 有没有可行的方案来解决这个问题呢?
既然 Redis 只将数据保存在内存中,那么是否可以考虑将这些数据也写一份到磁盘上呢?
如果采用这种方式,当 Redis 重启时,我们把磁盘中的数据快速恢复到内存中,这样它就可以继续正常提供服务了。
是的,这是一个非常好的解决方案,将内存数据写入磁盘的过程,我们称之为「数据持久化」。
数据持久化:有备无患
现在,你设想的 Redis 数据持久化是这样的:
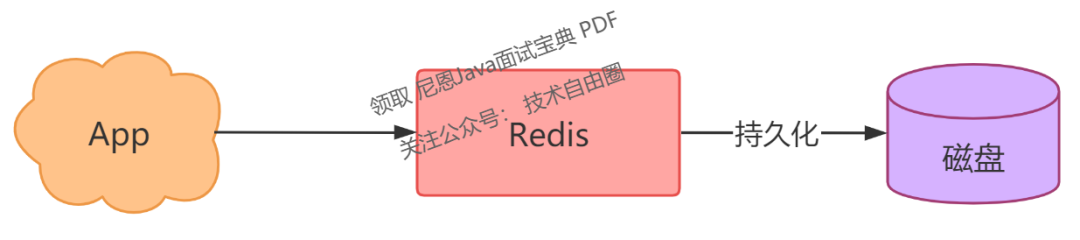
但是,数据持久化具体应该怎么做呢?
我猜你最容易想到的一个方案是,Redis 每一次执行写操作,除了写内存之外,同时也写一份到磁盘上,就像这样:

没错,这是最简单直接的方案。
注意,这里用的是写后日志。
从架构的方法论上,保证数据的高可靠方式,一般有写前日志(Write Ahead Log, WAL) 和 写后日志 两种架构方案。
写前日志 VS 写后日志
写前日志(Write Ahead Log, WAL):先记录日志,再执行「写」指令请求,具体来说,在实际写数据之前,将修改的数据写到日志文件中,故障恢复得以保证。
写后日志:先执行「写」指令请求,将数据写入内存,再记录日志。
写前日志(Write Ahead Log, WAL)的案例:比如 MySQL Innodb 存储引擎 中的 redo log(重做日志)便是记录修改的数据日志,在实际修改数据前,先记录修改日志再执行修改数据。
与MySQL相反,Redis 用的是 写后日志 的架构方案。
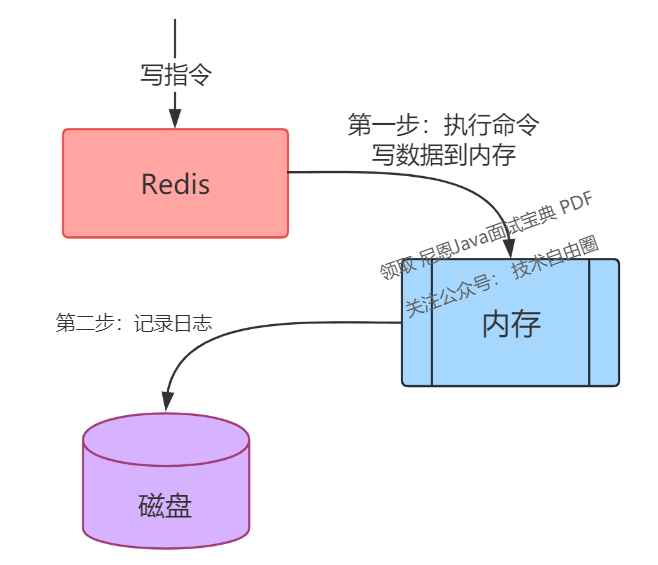
写后日志(先写内存,后写日志)的好处与风险
(1) 好处
-
不阻塞当前写操作;Redis 是 ap型的 组件, 性能第一, 写操作不能阻塞, 日志记录可以异步进行。
-
无需进行日志检查,往AOF写日志不需要检查命令正确性。若先写日志再执行命令,使用日志恢复时可能报错;
(2) 写后风险
-
命令执行完成后,如果写日志前宕机,则会丢数据;
但是,仔细考虑一下,这个方案存在一个问题:客户端的每次写操作,既要写内存,又要写磁盘,而磁盘写入的时间显然要比内存写入长得多!这无疑会对 Redis 的性能产生影响。
如何规避这个问题?
我们可以这样优化:采用异步架构, Redis 写内存由主线程来做,写内存完成后就给客户端返回结果,然后 Redis 用另一个线程去写磁盘,这样就可以避免主线程写磁盘对性能的影响。
这确实是一个好方案。
除此之外,我们还可以从另一个角度思考:有哪些其他方法可以实现数据持久化呢?
我们可以减少写入磁盘的次数,减少磁盘IO的次数,来提升性能。策略是:采用定期全量写入磁盘,这种方式,也叫「数据快照」。
那么,什么是数据快照呢?
简单来说,你可以这样理解:
-
将 Redis 看作是一个水杯,向 Redis 写入数据,就相当于往这个杯子里倒水。
-
此时你用相机给这个水杯拍一张照片,拍照的瞬间,照片中记录的这个水杯中水的容量,就是这个水杯的数据快照。
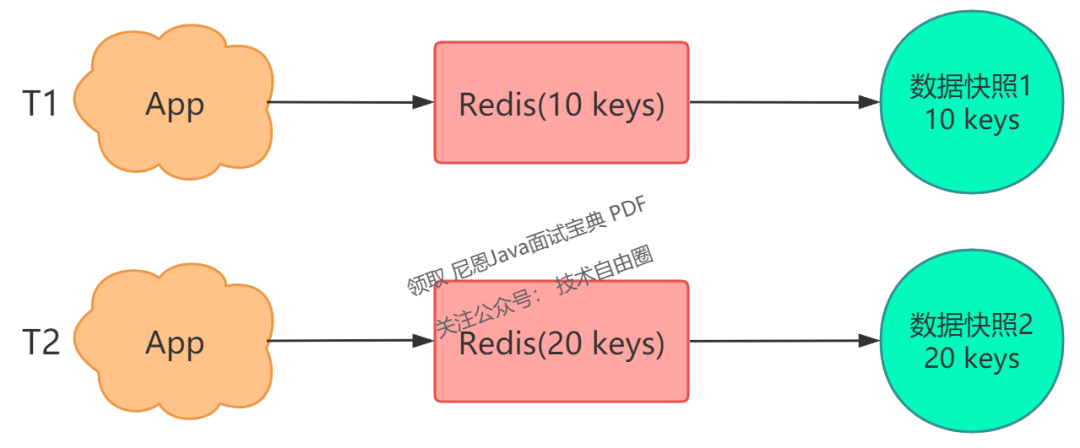
也就是说,Redis 的数据快照,是记录某一时刻下 Redis 中的数据,然后只需要把这个数据快照写到磁盘上即可。
它的优势在于,只有在需要持久化时,才会将数据「一次性」写入磁盘,其他时间则无需对磁盘进行操作。
基于这个方案,我们可以定时给 Redis 做数据快照,把数据持久化到磁盘上。
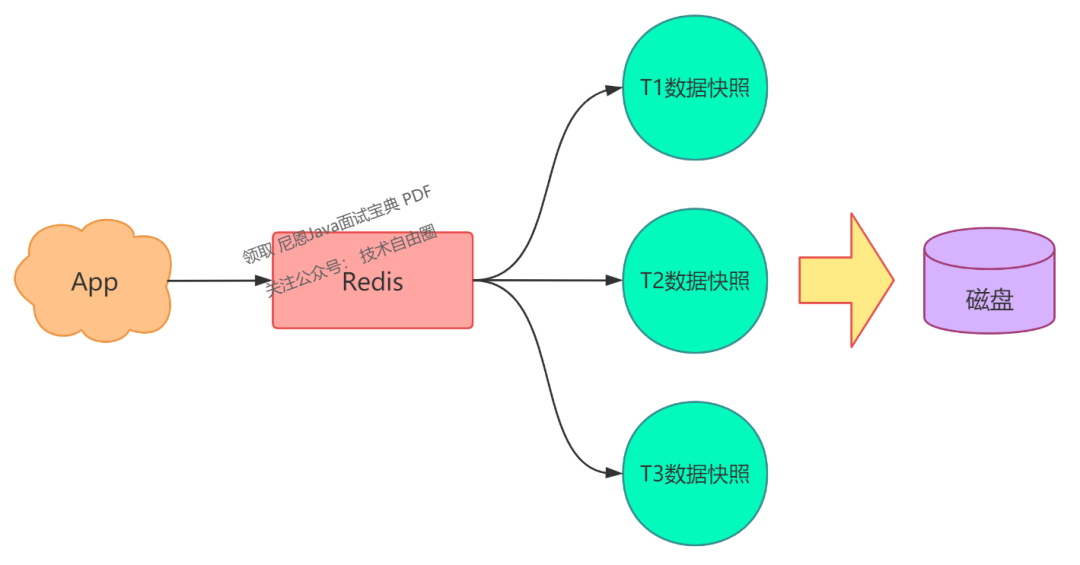
其实,上面说的这些持久化方案,就是 Redis 的「RDB」和「AOF」:
-
RDB:只将某一时刻的数据快照持久化到磁盘上(通过创建一个子进程来实现), 这个就是 数据快照架构
-
AOF:每次写操作都会持久化到磁盘上(主线程负责写内存,根据策略可以配置由主线程还是子线程来进行数据持久化), 这个是 写后日志 架构
另外,它们还有以下特点:
-
RDB 使用二进制 + 数据压缩的方式写入磁盘,因此文件体积较小,数据恢复速度也较快。
-
AOF 记录每次写命令,数据最完整,但文件体积较大,数据恢复速度较慢。
如果你需要选择持久化方案,可以根据以下原则进行选择:
-
如果你的业务对数据丢失不敏感,可以选择 RDB 方案来持久化数据。
-
如果你的业务对数据完整性要求较高,可以选择 AOF 方案来持久化数据。
假设你的业务对 Redis 数据完整性要求较高,选择了 AOF 方案,那么你可能会遇到以下问题:
-
AOF 记录每一次写操作,随着时间的推移,AOF 文件体积会逐渐增大。
-
这么大的 AOF 文件,在数据恢复时会变得非常缓慢。
这怎么办?
数据完整性要求变高了,恢复数据也变困难了?有没有什么方法,可以缩小文件体积?提升恢复速度呢?
我们继续来分析 AOF 的特点。
由于 AOF 文件中记录了每次写操作,但对于同一个 key 可能会发生多次修改,我们只保留最后一次修改的值是否可行呢?
是的,这就是我们常听到的「AOF rewrite」,你也可以将其理解为 AOF 的「瘦身」。
我们可以对 AOF 文件定时 rewrite,避免这个文件体积持续膨胀,这样在恢复时就可以缩短恢复时间了。
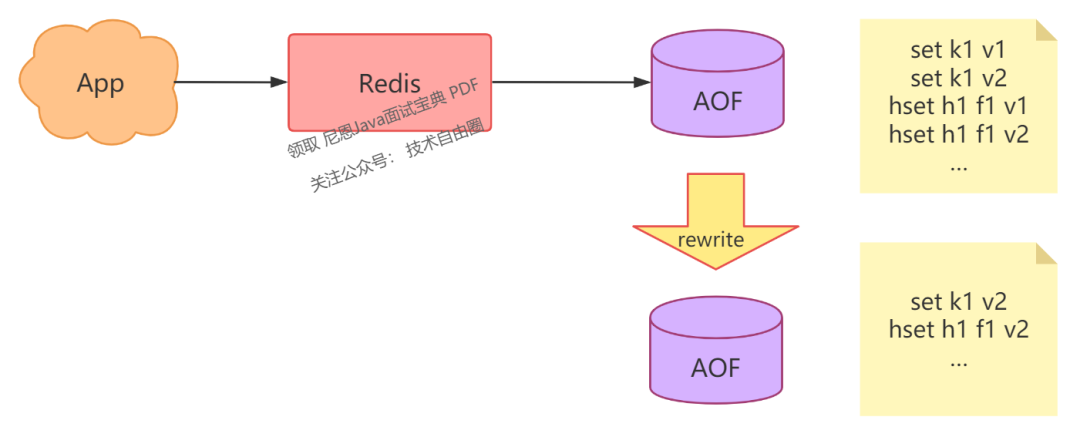
深入思考一下,能否找到方法进一步减小 AOF 文件?
回顾一下我们前面讲到的,RDB 和 AOF 各自的特点:
-
RDB 以二进制 + 数据压缩方式存储,文件体积小
-
AOF 记录每一次写命令,数据最全
我们能否充分利用它们各自的优势呢?
当然可以,这就是 Redis 的「混合持久化」。
具体来说,当 AOF rewrite 时,Redis 先以 RDB 格式在 AOF 文件中写入一个数据快照,再把在这期间产生的每一个写命令,追加到 AOF 文件中。
因为 RDB 是二进制压缩写入的,这样 AOF 文件体积就变得更小了。
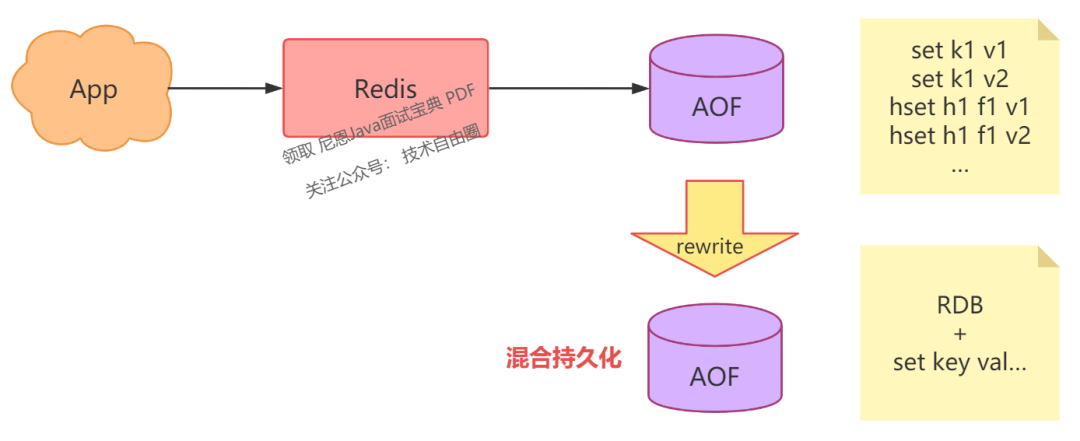
此时,你在使用 AOF 文件恢复数据时,恢复时间将会缩短!
需要注意的是,Redis 4.0 以上版本才支持混合持久化。
经过这样的优化,你的 Redis 再也无需担心实例宕机了,当发生宕机时,你就可以用持久化文件快速恢复 Redis 中的数据。
然而,这样就没问题了吗?
仔细想想,虽然我们已经将持久化文件优化到最小,但在恢复数据时仍需要时间,在这段时间内你的业务应用仍会受到影响,那该怎么办呢?
我们来探讨一下是否有更好的解决方案。
一个实例宕机,只能用恢复数据来解决,那我们是否可以部署多个 Redis 实例,然后让这些实例数据保持实时同步,这样当一个实例宕机时,我们可以在剩下的实例中选择一个继续提供服务。
没错,这个方案就是接下来要讲的「主从复制:多副本」。
主从复制:多副本
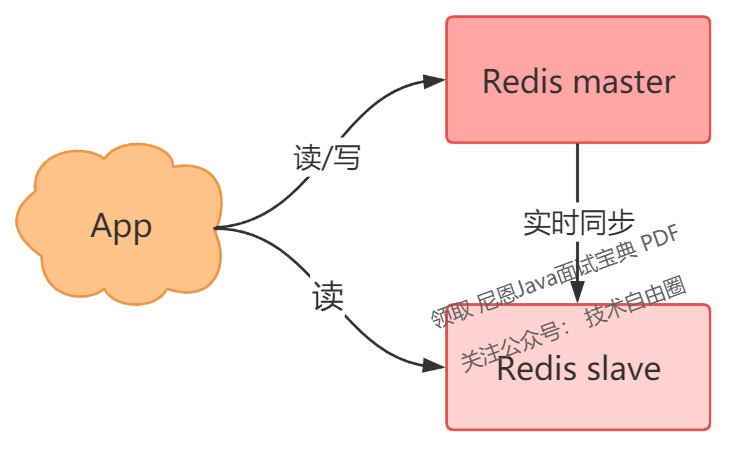
此时,你可以部署多个 Redis 实例,架构模型就变成了这样:
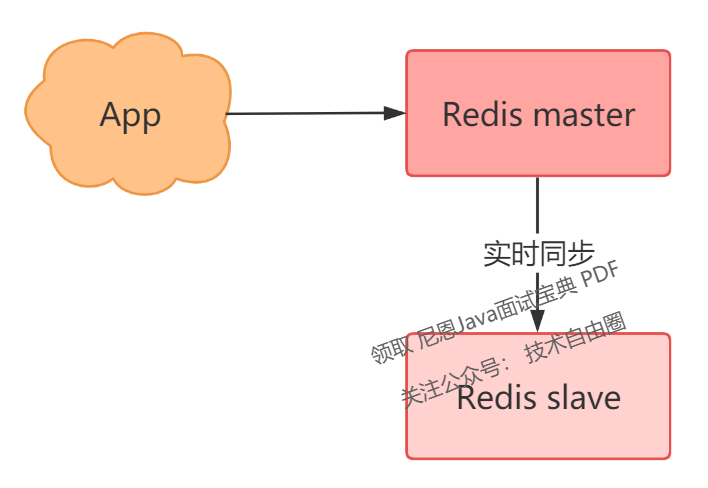
我们这里把实时读写的节点叫做 master,另一个实时同步数据的节点叫做 slave。
采用多副本的方案,它的优势是:
-
缩短不可用时间:master 发生宕机,我们可以手动把 slave 提升为 master 继续提供服务
-
提升读性能:让 slave 分担一部分读请求,从而提高应用的整体性能。
这个方案看起来不错,既节省了数据恢复时间,又提高了性能。
那么它有什么问题吗?
它的问题在于:当 master 宕机时,我们需要「手动」把 slave 提升为 master,这个过程也是需要花费时间的。
虽然比恢复数据要快得多,但还是需要人工介入处理。一旦需要人工介入,就必须要算上人的反应时间、操作时间,所以,在这期间你的业务应用依旧会受到影响。
那么如何解决这个问题呢?
我们是否可以把这个切换的过程,变成自动化呢?
针对这种情况,我们需要一个「故障自动切换」机制,这正是我们经常听到的「哨兵」所具备的能力。
哨兵:故障自动切换
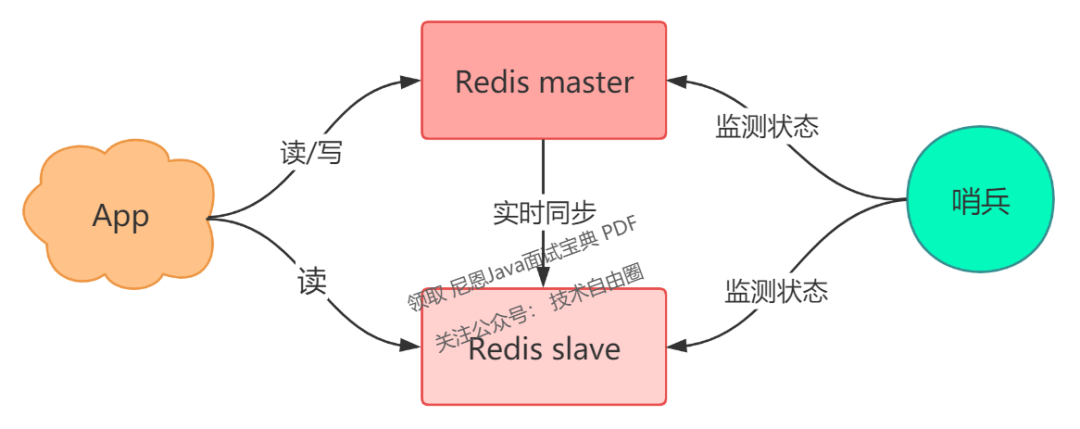
现在,我们可以引入一个「观察者」,让这个观察者去实时监测 master 的健康状态,这个观察者就是「哨兵」。
那么,具体如何实施呢?
-
哨兵每间隔一段时间,询问 master 是否正常
-
master 正常回复,表示状态正常,回复超时表示异常
-
哨兵发现异常,发起主从切换
有了这个方案,就无需人去介入处理了,一切就变得自动化了,是不是很棒?
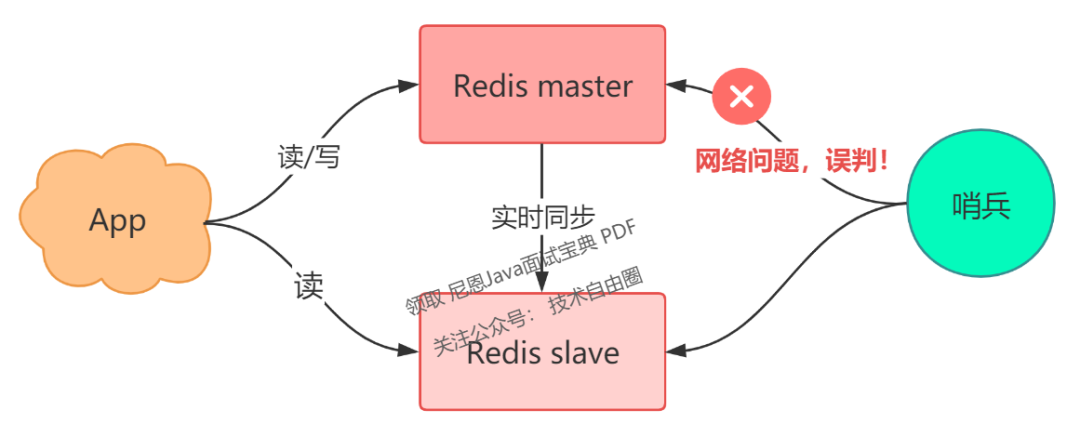
然而,还存在一个问题:
如果 master 状态正常,但这个哨兵在询问 master 时,它们之间的网络发生了问题,那这个哨兵可能会误判。
那么,如何解决这个问题呢?
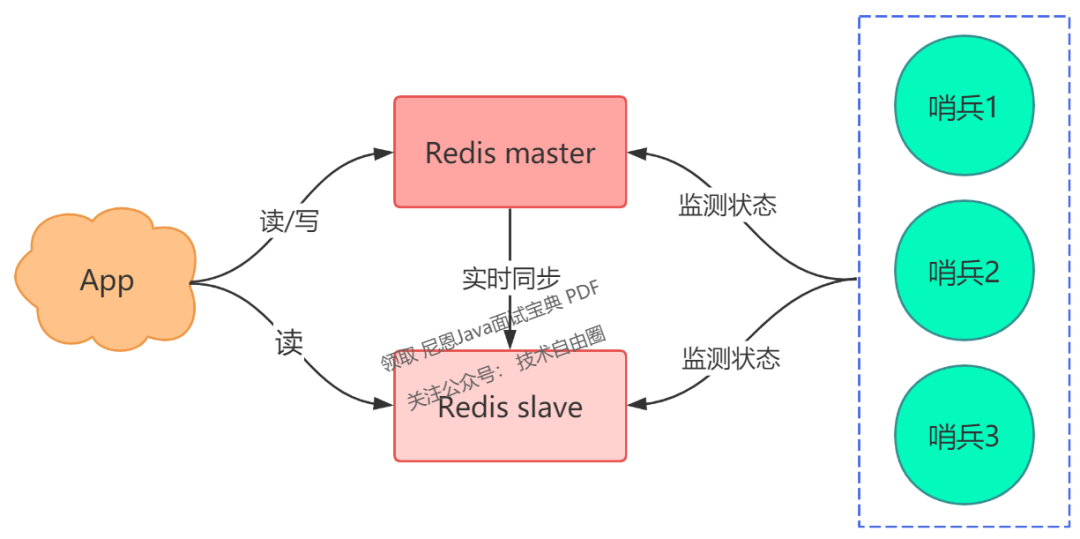
答案是,我们可以部署多个哨兵,让它们分布在不同的机器上,它们一起监测 master 的状态,流程就变成了这样:
-
多个哨兵每间隔一段时间,询问 master 是否正常
-
master 若正常回复,则表示其状态良好,若回复超时,则表示存在异常
-
一旦有一个哨兵判定 master 异常(不管是否是网络问题),就询问其它哨兵,如果多个哨兵(设置一个阈值)都认为 master 异常了,这才判定 master 确实发生了故障
-
多个哨兵经过协商后,判定 master 故障,则发起主从切换
因此,我们用多个哨兵互相协商来判定 master 的状态,这样一来,就可以大大降低误判的概率。
在哨兵协商判定 master 异常后,这里还有一个问题:由哪个哨兵来发起主从切换呢?
答案是,选出一个哨兵「领导者」,由这个领导者进行主从切换。
问题又来了,这个领导者怎么选?
设想一下,在现实生活中,选举是怎么做的?是的,投票。
在选举哨兵领导者时,我们可以制定这样一个选举规则:
-
每个哨兵都询问其它哨兵,请求对方为自己投票
-
每个哨兵只投票给第一个请求投票的哨兵,且只能投票一次
-
首先拿到超过半数投票的哨兵,当选为领导者,发起主从切换
其实,这个选举的过程就是我们经常听到的:分布式系统领域中的「共识算法」。
分布式系统领域中的「共识算法」
什么是共识算法?
我们在多个机器部署哨兵,它们需要共同协作完成一项任务,所以它们就组成了一个「分布式系统」。
在分布式系统领域,多个节点如何就一个问题达成共识的算法,就叫共识算法。
在这个场景下,多个哨兵共同协商,选举出一个都认可的领导者,就是使用共识算法完成的。
这个算法还规定节点的数量必须是奇数个,这样可以保证系统中即使有节点发生了故障,剩余超过「半数」的节点状态正常,依旧可以提供正确的结果,也就是说,这个算法还兼容了存在故障节点的情况。
共识算法在分布式系统领域有很多,例如 Paxos、Raft,哨兵选举领导者这个场景,使用的是 Raft 共识算法,因为它足够简单,且易于实现。
现在,我们用多个哨兵共同监测 Redis 的状态,这样一来,就可以避免误判的问题了,架构模型就变成了这样:
好了,到这里我们先小结一下。
你的 Redis 从最简单的单机版,经过数据持久化、主从多副本、哨兵集群这一系列优化,你的 Redis 不管是性能还是稳定性,都越来越高,即使节点出现故障,也无需担心。
你的 Redis 以这样的架构模式部署,基本上就可以稳定运行很长时间了。
…
然而,随着业务的发展,你的业务量开始迅速增长,此时你的架构模型,还能承受这么大的流量吗?
我们一起来分析一下:
-
稳定性:Redis 故障宕机,我们有哨兵 + 副本,可以自动完成主从切换
-
性能:读请求量增长,我们可以再部署多个 slave,实现读写分离,分担读压力
-
性能:写请求量增长,但我们只有一个 master 实例,这个实例达到瓶颈怎么办?
当你的写请求量越来越大时,单个 master 实例可能无法承受这么大的写流量。
要解决这个问题,此时你需要考虑使用「分片集群」。
分片集群:横向扩展
什么是「分片集群」?
简而言之,如果一个实例扛不住写压力,那我们是否可以部署多个实例,然后把这些实例按照一定规则组织起来,把它们当成一个整体,对外提供服务,这样不就可以解决集中写一个实例的瓶颈问题吗?
所以,现在的架构模型就变成了这样:
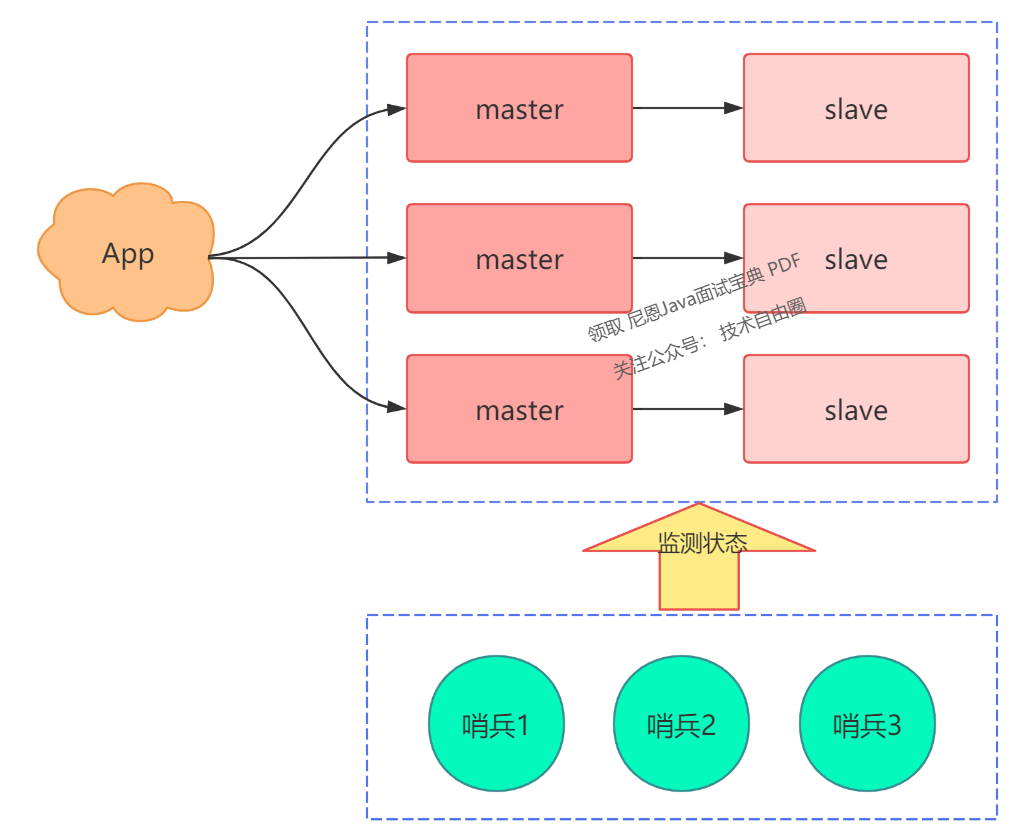
现在问题又来了,那么多实例应该如何组织呢?
我们制定规则如下:
-
每个节点各自存储一部分数据,所有节点数据之和才是全量数据
-
制定一个路由规则,对于不同的 key,把它路由到固定一个实例上进行读写
而根据路由规则所在的位置,分片集群可以分为两大类:
-
客户端分片
-
服务端分片
客户端分片指的是,将 key 的路由规则放在客户端来做,就是下面这样:
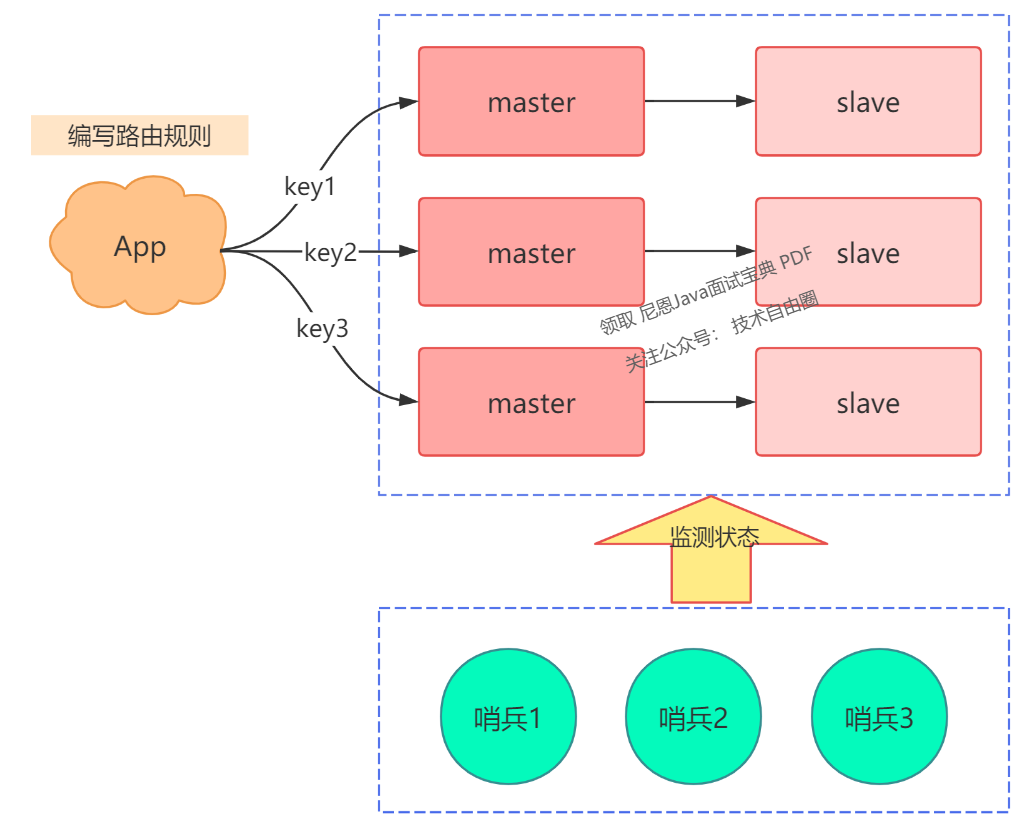
这个方案的缺点是,客户端需要维护这个路由规则,也就是说,你需要将路由规则写到你的业务代码中。
如何在不将路由规则与业务代码耦合的情况下实现?
你可以这样优化,将这个路由规则封装成一个模块,当需要使用时,集成这个模块就可以了。
这正是 Redis Cluster 的采用的方案。

Redis Cluster 内置了哨兵逻辑,无需额外部署哨兵。
在使用 Redis Cluster 的过程中,你的业务应用需依赖相应的 Redis SDK,该 SDK 已内置路由规则,无需手动编写。
接下来,我们来看服务端分片的实现。
该方案是指将路由规则不放在客户端处理,而是在客户端与服务端之间添加一个「中间代理层」,这个代理就是我们常听说的 Proxy。
而数据的路由规则,就放在这个 Proxy 层来维护。
这样一来,你就无需关心服务端有多少个 Redis 节点了,只需要和这个 Proxy 进行交互即可。
Proxy 会根据路由规则将你的请求转发至相应的 Redis 节点。
并且,当集群实例无法承受更大的流量请求时,还可以横向扩展,通过添加新的 Redis 实例以提升性能。这一切对于你的客户端而言,都是透明且无感知的。
业界开源的 Redis 分片集群方案,例如 Twemproxy、Codis,就是采用了这种方案。

如今,采用分片集群后,你可以从容应对更大的流量压力了!
总结
让我们回顾一下,我们是如何演进一个稳定且高性能的 Redis 集群的。
首先,在使用最简单的单机版 Redis 时,我们遇到了 Redis 故障宕机后数据无法恢复的问题,因此我们引入了「数据持久化」,将内存中的数据保存到磁盘上,以便 Redis 重启后能快速恢复数据。
在进行数据持久化时,我们面临如何更高效地将数据保存到磁盘的问题。后来我们发现 Redis 提供了 RDB 和 AOF 两种方案,分别对应数据快照和实时命令记录。当对数据完整性要求不高时,可以选择 RDB 持久化方案;如果对数据完整性要求较高,可以选择 AOF 持久化方案。
但是我们又发现,AOF 文件体积会随着时间增长变得越来越大,此时我们想到的优化方案是,使用 AOF rewrite 的方式对其进行瘦身,减小文件体积,再后来,我们发现可以结合 RDB 和 AOF 各自的优势,在 AOF rewrite 时使用两者结合的「混合持久化」方式,又进一步减小了 AOF 文件体积。
接着,我们发现虽然可以通过数据恢复的方式还原数据,但恢复数据仍需要花费时间,这意味着业务应用仍会受到影响。我们进一步优化,采用「多副本」的方案,让多个实例保持实时同步,当一个实例故障时,可以手动把其他实例提升上来继续提供服务。
但是这样也有问题,手动提升实例上来,需要人工介入,人工介入操作也需要时间,我们开始寻找方法使这个流程自动化,因此我们引入了「哨兵」集群。哨兵集群通过互相协商的方式,发现故障节点,并可以自动完成切换,从而大幅降低对业务应用的影响。
最后,我们将关注点放在如何支持更大的写流量上,因此引入了「分片集群」来解决这个问题,让多个 Redis 实例分担写压力。面对更大的流量,我们还可以添加新的实例进行横向扩展,进一步提高集群性能。
通过这些步骤,我们的 Redis 集群能够长期稳定、高性能地为我们的业务提供服务。
在架构演进的过程中, 围绕着「架构设计」的核心思想:
-
高性能:读写分离、分片集群
-
高可用:数据持久化、多副本、故障自动切换
-
易扩展:分片集群、横向扩展
-
高可靠:写后日志、数据快照
当我们提及哨兵群体、分片群体时,还涉及到了「分布式系统」相关的知识:
-
分布式共识:哨兵领导者选举
-
负载均衡:分片集群数据分片、数据路由
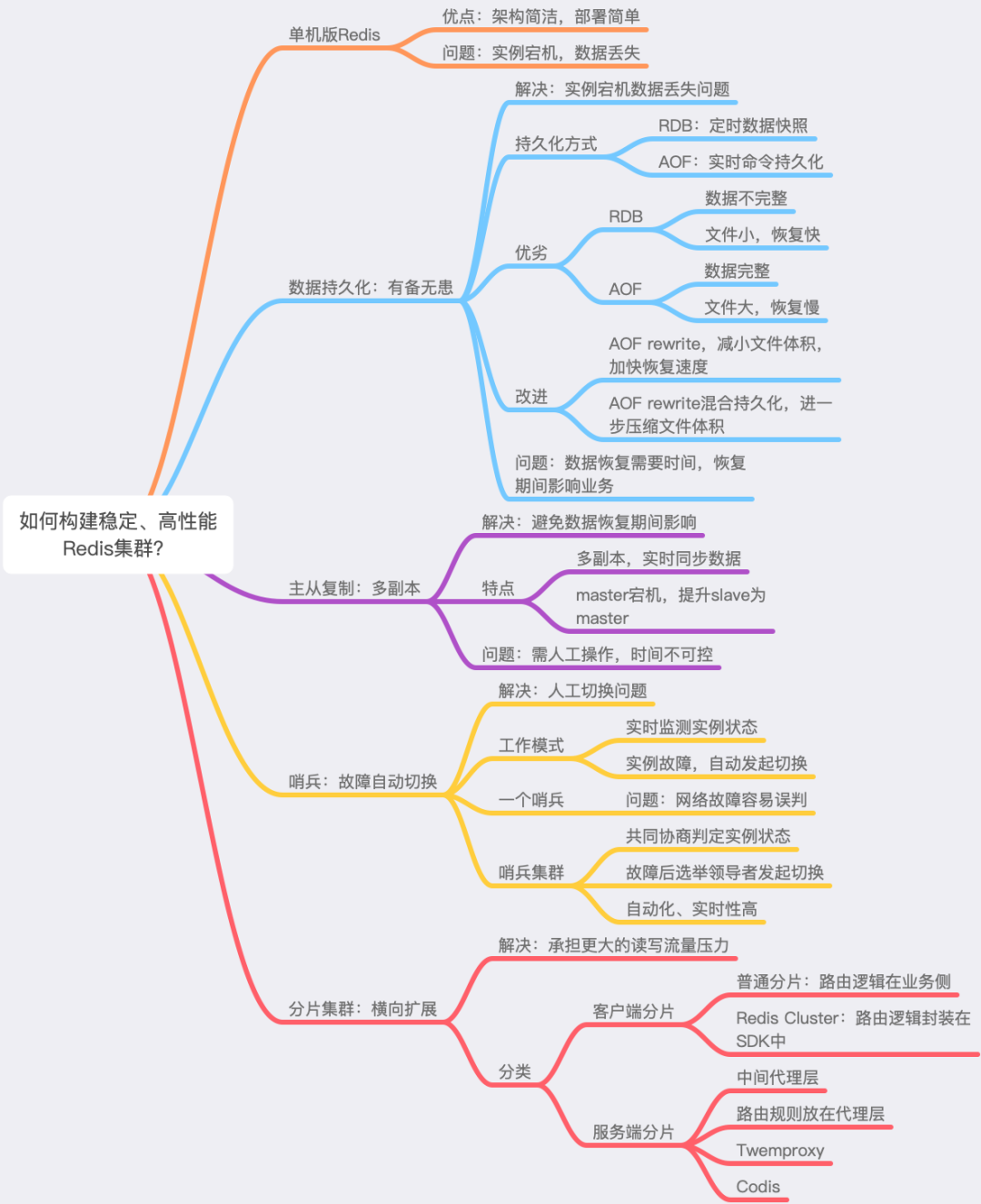
这里用一个思维导图,方便你更好地去理解它们之间的关系,以及演化的过程。
当然,除了 Redis 之外,对于构建任何一个数据集群,你都可以沿用这个思路去思考、去优化,看看它们到底是如何做的。
例如在使用 MySQL 时,你可以思考 MySQL 与 Redis 的差异,以及 MySQL 是如何实现高性能和高可用的。其实思路都是类似的。
如今我们随处可见分布式系统、数据群体,希望通过这篇文章,你可以理解这些软件是如何逐步演进而来的,在演化过程中,它们遇到了哪些问题,为了解决这些问题,这些软件的设计者提出了怎样的方案,做出了哪些取舍?
实际上,这个思考过程也是进行「架构设计」的思路。
在进行软件架构设计时,您面临的场景是发现问题、分析问题、解决问题,逐步优化和升级您的架构,最终在性能和可靠性方面达到平衡。尽管各种软件层出不穷,但架构设计的理念不会改变,希望您真正吸收的是这些思想,这样才能做到以不变应万变。
参考文献
https://blog.csdn.net/yangbindxj/article/details/125246467
https://zhuanlan.zhihu.com/p/349241304
Nacos 无入侵配置,怎么实现?
无入侵配置方案一:什么是无代码侵入性的配置管理
一般的配置管理系统都是代码侵入性的,应用接入配置管理系统都需要使用对应的SDK来查询和监听数据的变更。对于一些已经成熟的系统来说,接入SDK来实现动态配置管理是很难实现的,Nacos通过引入配置管理工具confd可以实现系统的配置变更做到无代码侵入性。
为什么要支持confd,老的应用配置管理模式是启动时读取配置文件,然后重新读取配置文件需要应用重启。
confd是一个轻量级的配置管理工具,可以通过查询后端存储系统来实现第三方系统的动态配置管理,如Nginx、Tomcat、HAproxy、Docker配置等。confd目前支持的后端有etcd、ZooKeeper等,Nacos 1.1版本通过对confd定制支持Nacos作为后端存储。
confd能够查询和监听后端系统的数据变更,结合配置模版引擎动态更新本地配置文件,保持和后端系统的数据一致,并且能够执行命令或者脚本实现系统的reload或者重启。
安装confd插件
confd的安装可以通过源码安装方式,confd基于Go语言编写,其编译安装依赖Go,首先需要确保本地安装了Go,版本不低于v1.10 创建confd目录,下载confd源码,编译生成可执行文件
mkdir -p $GOPATH/src/github.com/kelseyhightower
cd $GOPATH/src/github.com/kelseyhightower
wget https://github.com/nacos-group/nacos-confd/archive/v0.19.1.tar.gz
tar -xvf v0.19.1.tar.gz
mv nacos-confd-0.19.1 confd
cd confd
make
复制confd文件到bin目录下,启动confd
sudo cp bin/confd /usr/local/bin
confd
confd结合Nacos实现nginx配置管理示例
本文介绍使用Nacos结合confd实现Nginx配置管理,为简单起见以Nginx的黑名单功能为演示示例,Nacos使用官网部署的服务,域名为console.nacos.io (http://xn--console-e73k064bojj.nacos.io/)。
Nginx的安装可以参考网上文章
1.创建confd所需目录
confd配置文件默认在/etc/confd中,可以通过参数-confdir指定。目录中包含两个子目录,分别是:conf.d templates
mkdir -p /etc/confd/{conf.d,templates}
2.创建confd配置文件
confd会先读取conf.d目录中的配置文件(toml格式),然后根据文件指定的模板路径去渲染模板。
vim /etc/confd/conf.d/nginx.toml
内容为如下,其中nginx.conf.tmpl文件为confd的模版文件,keys为模版渲染成配置文件所需的配置内容,/usr/local/nginx/conf/nginx.conf为生成的配置文件
[template]
src = " nginx.conf.tmpl"
dest =
"/usr/local/nginx/conf/nginx.conf"
keys = [
"/nginx/conf",
]
check_cmd = "/usr/local/nginx/sbin/nginx -t
-c {{.src}}"
reload_cmd = "/usr/local/nginx/sbin/nginx
-s reload"
3.创建模版文件
拷贝Nginx原始的配置,增加对应的渲染内容
cp /usr/local/nginx/conf/nginx.conf
/etc/confd/templates/nginx.conf.tmpl
vim /etc/confd/templates/nginx.conf.tmpl
增加内容为:
···
{{$data := json (getv "/nginx/conf")}}
{{range $data.blackList}}
deny {{.}};
{{end}}
···
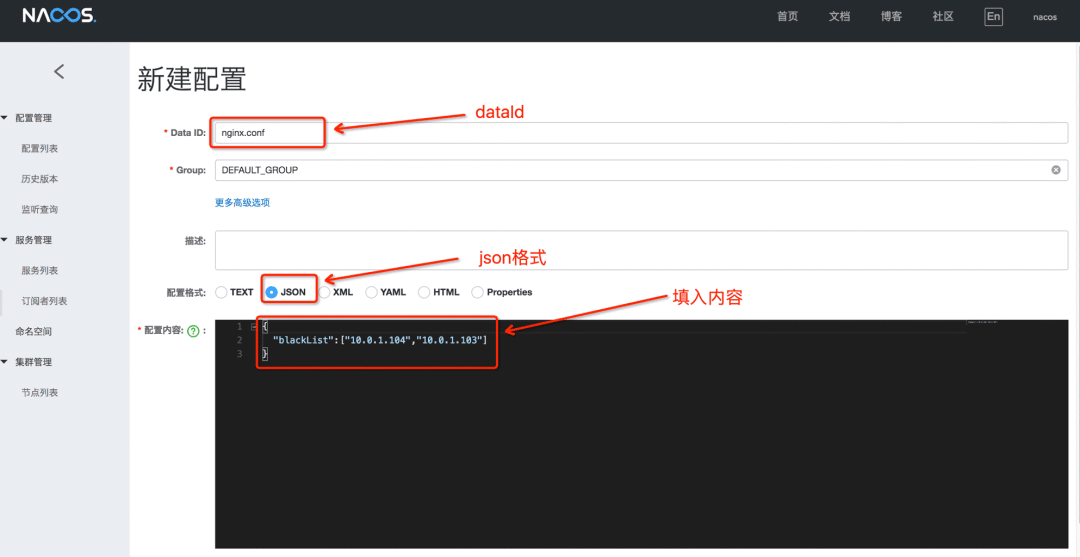
4.在Nacos上创建所需的配置文件
在public命名空间创建dataId为nginx.conf的配置文件,group使用默认的DEFAULT_GROUP即可,配置内容为json格式
{
"blackList":["10.0.1.104","10.0.1.103"]
}
5.启动confd
启动confd,从Nacos获取配置文件,渲染Nginx配置文件。backend设置成nacos,node指定访问的Nacos服务地址,watch让confd支持动态监听
confd -backend nacos -node http://console.nacos.io:80 -watch
6.查看Nginx配置文件,验证Nginx启动
查看生成的/usr/local/nginx/conf/nginx.conf配置文件是否存在如下内容
...
deny 10.0.1.104;
deny 10.0.1.103;
...
curl命令访问Nginx,验证是否返回正常。http响应状态码为200说明访问Nginx正常
curl http://$IP:8080/ -i
HTTP/1.1 200 OK
...
7.查看本机Ip,加到Nacos配置文件黑名单中
假设本机的Ip为30.5.125.107,将本机的Ip加入到Nginx黑名单
{
"blackList":["10.0.1.104","10.0.1.103","30.5.125.107"]
}
8.查看Nginx配置文件,验证黑名单是否生效
查看生成的/usr/local/nginx/conf/nginx.conf配置文件是否存在如下内容
...
deny 10.0.1.104;
deny 10.0.1.103;
deny 30.5.125.107;
...
curl命令访问Nginx,访问应该被拒绝,返回403
curl http://$IP:8080/ -i
HTTP/1.1 403 Forbidden
...
Nacos结合confd做无入侵配置总结
使用Nacos结合confd来做自动化管理,confd作为轻量级的配置管理工具可以做到对第三方系统无代码侵入性。
本文只是简单使用Nginx的黑名单功能来演示Nacos+confd的使用方式,当然Nginx还具有限流、反向代理等功能以及其他的系统比如Naproxy、Tomcat、Docker等也同样可以使用Nacos+confd做管理。
无入侵配置方案二:如何使用confd+ACM管理Nginx配置
Nginx 作为优秀的开源软件,凭借其高性能高并发等特点,常常作为web和反向代理服务部署在生产环境中。但是当 Nginx 的规模较大时, Nginx 的运维成本也是不断上升。
如何通过confd+ACM来管理 Nginx 配置,通过集中式的配置管理方式解决 Nginx 的大规模运维问题,运维和开发人员不用登陆到 Nginx 机器上,只需要配置好confd,然后在ACM上操作就可以动态修改 Nginx 的配置参数。
准备工作
在操作本文的示例之前需要配置好开通ACM和对confd的使用有基本概念,ACM的开通及其基本使用可以参考:(https://help.aliyun.com/document_detail/59953.html%3Fspm%3Da2c4g.11186623.6.542.4bd57fa9WS2KwF)
confd的基本使用可以参考:(https://yq.aliyun.com/go/articleRenderRedirect?https://help.aliyun.com/document_detail/124844.html)
Nginx 在日常开发中使用得比较多的功能是负载均衡、限流、缓存等, Nginx 的使用和安装可以在网上查阅相关资料。本文结合负载均衡和限流功能讲解如何使用confd+ACM实现 Nginx 的大规模运维操作。
创建confd配置文件
创建confd所需的toml格式配置文件
vim /etc/confd/conf.d/myapp.toml
check_cmd用于检验 Nginx 配置的正确性,当src配置错误则不会覆盖 Nginx 配置 reload_cmd用于reload Nginx 配置
[template]
src = " Nginx .conf.tmpl"
dest = "/usr/local/ Nginx /conf/ Nginx .conf"
keys = [
"/myapp/ Nginx /conf",
]
check_cmd = "/usr/local/ Nginx /sbin/ Nginx -t -c {{.src}}"
reload_cmd = "/usr/local/ Nginx /sbin/ Nginx -s reload"
创建模版文件
vim /etc/confd/templates/ Nginx .conf.tmpl
getv从ACM中获取对应dataId的配置,/myapp/ Nginx /conf对应的dataId为myapp. Nginx .conf,配置格式为json格式,模版文件包含了 Nginx 的upstream、限流、黑白名单配置内容,通过json指令解析配置文件。upstream后端ip通过从ACM的配置的backends数组中获取,同样地,白名单和黑名单ip分别存储在whiteList和blackList的数组中,限流的速率和并发数通过rateLimit和connectionLimit设置
...
{{$data := json (getv "/myapp/ Nginx /conf")}}
geo $whiteiplist {
default 1;
{{range $data.whiteList}}
{{.}} 0;
{{end}}
}
map $whiteiplist $limit {
1 $binary_remote_addr;
0 "";
}
limit_req_zone $limit zone=rateLimit:10m rate={{$data.rateLimit}}r/s;
limit_conn_zone $limit zone=connectionLimit:10m;
{{range $data.blackList}}
deny {{.}};
{{end}}
upstream myapp {
server 11.160.65.95:8080;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
proxy_pass http://myapp;
limit_conn connectionLimit {{$data.connectionLimit}};
limit_req zone=rateLimit burst={{$data.burst}} nodelay;
}
...
}
...
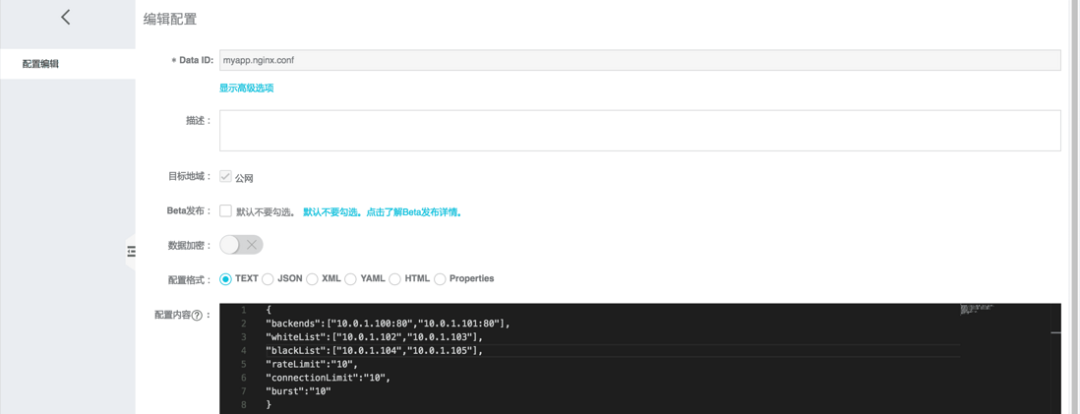
在ACM上创建所需的配置文件
创建dataId为myapp. Nginx .conf的配置文件,group使用默认的DEFAULT_GROUP即可,配置内容设置好上游节点、黑白名单以及限流阈值
{
"backends":["10.0.1.100:80","10.0.1.101:80"],
"whiteList":["10.0.1.102","10.0.1.103"],
"blackList":["10.0.1.104","10.0.1.104"],
"rateLimit":"10",
"connectionLimit":"10",
"burst":"10"
}
启动confd
启动confd,设置好backend、endpoint、命名空间namespace和阿里云账号accessKey/secretKey
confd -backend nacos -endpoint {endpoint}:8080 -namespace {namespace} -accessKey {accessKey} -secretKey {secretKey}

生成配置文件
confd将ACM中的参数通过模板文件渲染生成新的 Nginx 配置文件,查看生成的/usr/local/ Nginx / Nginx .conf配置文件是否符合预期,并检查 Nginx 是否成功reload配置。
...
geo $whiteiplist {
default 1;
10.0.1.102 0;
10.0.1.103 0;
}
map $whiteiplist $limit {
1 $binary_remote_addr;
0 "";
}
limit_req_zone $limit zone=rateLimit:10m rate=10r/s;
limit_conn_zone $limit zone=connectionLimit:10m;
deny 30.5.125.74;
deny 10.0.1.105;
upstream myapp {
server 11.160.65.95:8080;
}
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
proxy_pass http://myapp;
limit_conn connectionLimit 10;
limit_req zone=rateLimit burst=10 nodelay;
}
...
}
...
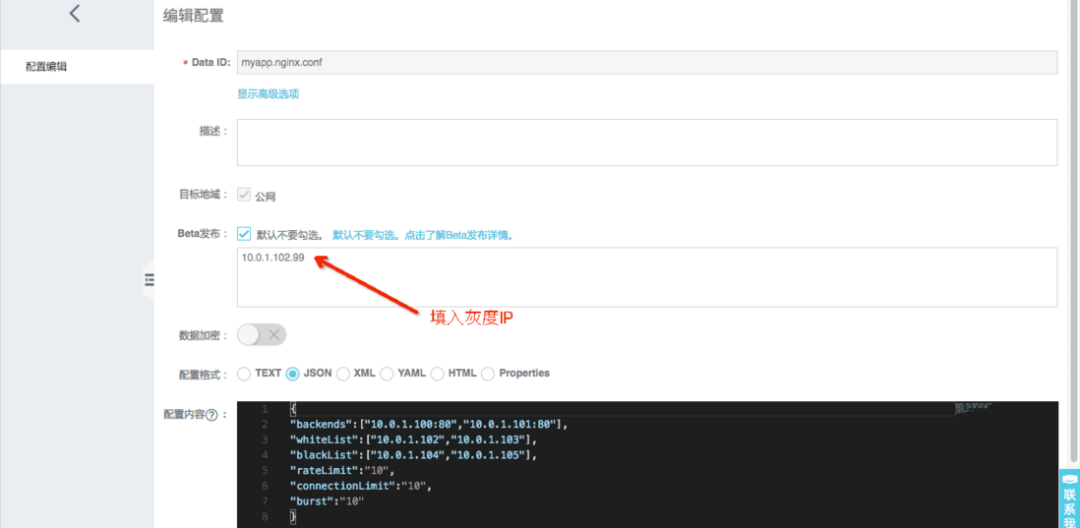
动态修改 Nginx 配置
运行时当需要调节 Nginx 的名单或者限流阈值的时候,可以在ACM上修改配置的内容。当然在生产环境可以使用ACM的灰度发布功能(Beta发布)验证没问题再全量发布下去。
这里演示了如何使用confd+ACM管理 Nginx 配置,降低 Nginx 的运维成本。
无入侵配置方案三:使用etcd+confd管理nginx配置
nginx的配置是一个典型的key value类型的,而且 配置文件能够 分模块+ 嵌套,一个目录下面可以包含其他配置,目录下还可以有目录,嵌套多层。
结合confd ,可以把配置信息,动态的存储在 k-v型 Nosql数据库中。
如今key value类型的Nosql数据库非常多,redis、leveldb、etcd 等,etcd 提供类似文件系统操作,使用raft协议保持数据一致性,非常适合云计算分布式部署场景,将confd与etcd搭配,非常适合nginx这样的配置格式。
1、目标Nginx 配置文件
要生成的目标Nginx 配置,大概如下;
upstream www_test {
server 196.75.121.112:443; (动态生成)
}
server {
listen 443 ssl; (动态生成)
server_name www.test.com; (动态生成)
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;;
ssl_certificate /home/build/openresty/nginx/cert/dealssl/www.bestenover.com.crt; (动态生成)
location / {
proxy_pass https://www_test; (动态生成)
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_redirect off;
}
}
2、实现框架
使用etcd新建与nginx配置对应的目录如下:

可以设计一套webui, 展示配置和后台生成nginx配置,总体的配置流程图如下所示:
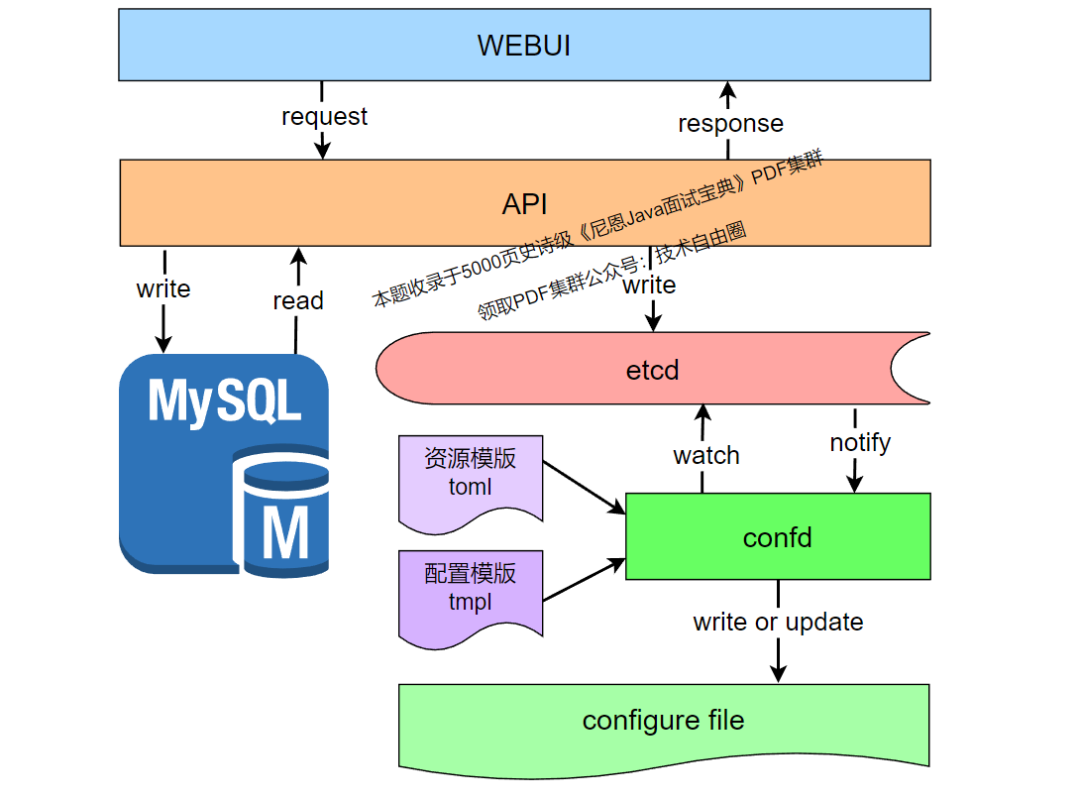
3、生成配置
WEBUI通过API将配置写入mysql和etcd,confd注册监控etcd的key为/nginx/,只要发生变化就通知confd根据模板生成配置。
confd默认的配置路径为/etc/confd/,创建conf.d和template两个目录,分别存放配置资源和配置模板。
nginx的配置资源如下所示:test.conf.toml
[template]
src = "test.conf.tmpl"
dest = "/tmp/test.conf"
keys = [
"/nginx",
]
check_cmd = "/usr/sbin/nginx -t -c {{.src}}"
reload_cmd = "/usr/sbin/service nginx reload"
nginx的配置模板如下所示:test.conf.tmpl
upstream www_{{getv "/nginx/https/www/server/server_name"}} {
{{range getvs "/nginx/https/www/upstream/*"}}server {{.}};{{end}}
}
server {
server_name {{getv "/nginx/https/www/server/server_name"}}:443;
ssl on
ssl_certificate {{getv "/nginx/https/www/server/ssl_certificate"}};
ssl_certificate_key {{getv "/nginx/https/www/server/ssl_certificate_key"}};
location / {
proxy_pass http://www_{{getv "/nginx/https/www/server/server_name"}};
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_redirect off;
}
}
开启confd,执行 ./confd -watch -backend etcd -node http://127.0.0.1:2379
使用ectdctl添加配置如下:
./etcdctl set /nginx/https/www/server/server_name test.com
./etcdctl set /nginx/https/www/server/ssl_certificate /home/waf/build/openresty/nginx/cert/client/client.crt
./etcdctl set /nginx/https/www/server/ssl_certificate_key /home/waf/build/openresty/nginx/cert/client/client.key;
/etcdctl set /nginx/https/www/upstream/server1 192.168.1.2:443
./etcdctl set /nginx/https/www/upstream/server2 192.168.4.2:443
confd的执行结果如下所示:

生成位置文件如下所示:
upstream www_test.com {
server 192.168.1.2:443;
server 192.168.4.2:443;
}
server {
server_name test.com:443;
ssl on
ssl_certificate /home/waf/build/openresty/nginx/cert/client/client.crt;
ssl_certificate_key /home/waf/build/openresty/nginx/cert/client/client.key;
location / {
proxy_pass http://www_test.com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_redirect off;
}
}
最终的生成效果,与模板生成的保持一致。
参考文献
https://segmentfault.com/a/1190000019741469
https://www.cnblogs.com/Anker/p/6112022.html
cond的github上文档介绍:https://github.com/kelseyhightower/confd/blob/master/docs/template-resources.md
etcd与confd实现配置管理:http://xiaorui.cc/2015/01/25/confd和etcd实现配置管理及自动发现/
http://www.tuicool.com/articles/eeiAve
etcd的参考:https://github.com/coreos/etcd
https://yq.aliyun.com/articles/11035
http://www.infoq.com/cn/articles/coreos-analyse-etcd/
Oracle JDK那么好,为何要用Open JDK?
OpenJDK 项目主要基于 Sun 捐赠的 HotSpot 源代码。
对于 Java 7,没什么太多的区别:OpenJDK 被选为 Java 7 的参考实现,由 Oracle 工程师维护。
从Java 7开始 后面的版本, Oracle JDK 和 OpenJDK 的核心区别如下:
1 OpenJDK 是支持 开源的,遵守GPL开源协议
开源意味着 可以对它根据你自己的需要进行修改、优化,比如 Alibaba 基于 OpenJDK 开发了 Dragonwell8:https://github.com/alibaba/dragonwell8
GPL是传染性协议,任何用了GPL开源协议的软件,都会被传染为强制开源,比如你用了某一个GPL开源协议的类库,那么用了该类库的所有代码,都必须开源,而且是用GPL开源协议开源,OpenJDK 用的是GPL with Classpath Exception协议 ,有个尾巴 with Classpath Exception。这个尾巴 with Classpath Exception,又称为 with linking exception (https://en.wikipedia.org/wiki/GPL_linking_exception),什么意思?就是用它们的模块,而不是去修改他的模块,就可以闭源发布。比如Java代码里面,常见的import语句,比如import java.*, javax.*, javafx.* etc.等等,这些都属于exception里面的,也就是说,你只是import这些类库,并且使用它们的话,不受GPL协议影响,你大可以在此基础之上,制作自己的软件,并且闭源发布。
什么情况下会被强制开源呢?很简单,你魔改了Open JDK的实现的话,比如你更改了java.base.jmod模块的源代码的话,那你的代码就会被GPL传染上,要求必需开源,否则就违背了Open JDK的开源协议,当初SUN这样做的目的很简单,就是为了防止出现不同版本的Java,否则IBM整一个Java,SUN整一个Java,互相之间代码还不兼容,那就麻烦大了,违背了Java最初的承诺,就是编译一次,四处运行。
开源许可协议GPL、APL、BSD、LGPL、MIT等的区别
开源软件的授权许可都是基于开源许可协议的,常见的开源许可协议有GPL、LGPL、APL、BSD、MIT、Mozilla Public License、Creative Commons、Eclipse Public License 1.0等。它们之前有很多相同的地方,也有很多不同的地方,本文将分析一下这些协议之间的区别。
GPL(GNU General Public License),使用源软件的类库引用(源代码)、改变(修改了源代码)的新软件,也必须采用GPL进行授权。就是说,只要使用了GPL开源软件的源代码或拿它的源代码进行了修改而编写的新的软件,也必须加入到GPL的阵营。很明显,不能拿GPL授权的开源东东来做商业软件。这个协议有个好处,就是极大增加了使用GPL的软件的数量。采用GPL授权的软件有:Linux、MySQL等。
LGPL(Lesser GPL),相比GPL的严格,LGPL要温和很多。可以通过引用类库的方式(不是直接使用源代码)拿LGPL授权的东东来重新开发商业软件。如果是要修改源代码,是相应的修改和衍生出来的代码都要使用LGPL开放源代码。采用LGPL的软件有:JBoss、Hibernate、FCKeditor等。
APL(apache Licence vesion 2.0),适用于商业软件,允许修改代码后再发布(不用开放源代码)。采用APL的软件有Hadoop、Apache HttpServer等。
BSD(Berkeley Software Distribution),这个协议的要求很宽松,允许他人修改和重新发布代码,可以在此基础上开发出商业软件进行销售。所以,此协议适用于商业软件。采用BSD协议的软件最著名的有nginx。
MIT(Massachusetts Institute of Technology),又称X11协议。MIT与BSD类似,但是比BSD协议更加宽松,算是目前限制最少的协议了。这个协议唯一的条件就是在修改后的代码或者发行包包含原作者的许可信息。适用商业软件。采用MIT的软件有:jquery、Node.js
还有关于Mozilla Public License、Creative Commons、Eclipse Public License 1.0等协议,这里就不一一介绍了。
2 Oracle JDK 是商业免费的,并不是开源的
另外,虽然 Oracle JDK 也是商业免费(比如 JDK 8),但并不是所有版本都是免费的。
这也是为什么:linux 通过 yum 包管理器上默认安装的 JDK 是 OpenJDK 而不是 Oracle JDK。
| Oracle JDK | Open JDK | |
|---|---|---|
| 是否开源 | 完全开源 | 部分开源 |
| 是否免费 | 是 | 部分免费,部分商用 |
| 功能 | 基本一致 | 基本一致 |
| 稳定性 | 提供 LTS(Log Tank Service)服务 | |
| 协议 | BCL/OTN 协议 | GPL v2 |
Oracle JDK各个版本所用的协议:
| Oracle JDK版本 | BCL协议 | OTN协议 |
|---|---|---|
| 6 | 最后一个公共更新6u45之前 | |
| 7 | 最后一个公共更新7u80之前 | |
| 8 | 8u201/8u202之前 | 8u211/8u212之后 |
| 9 | √ | |
| 10 | √ | |
| 11 | √ | |
| 12 | √ |
BCL 协议(Oracle Binary Code License Agreement):可以使用 JDK(支持商用),但是不能进行修改。
OTN 协议(Oracle Technology Network License Agreement):11 及之后新发布的 JDK 用的都是这个协议,可以自己私下用,但是商用需要付费。
3 OpenJDK 是试错角色、炮灰角色,快速更新,为 Oracle JDK LTS版本打冲锋陷阵
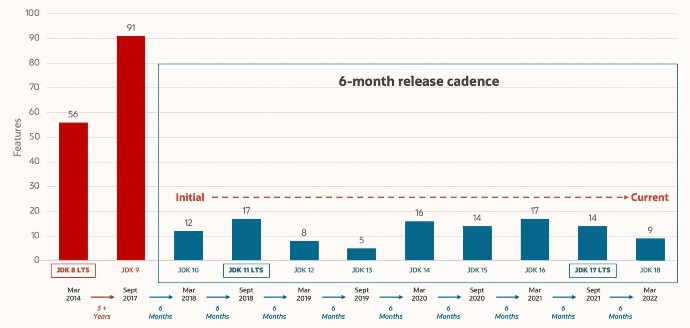
OpenJDK的特点是更新频繁,实现快速迭代和高效试错,为Oracle JDK LTS版本打下基础。
Oracle JDK 一般是每 6 个月发布一个新版本,而 OpenJDK 一般是每 3 个月发布一个新版本。
为啥 Oracle JDK 更稳定了吧,先在 OpenJDK 试试水,把大部分问题都解决掉了才在 Oracle JDK 上发布)
基于以上这些原因, OpenJDK 还是有存在的必要的!
上面这个问题,oracle 官方也回答过,大致如下:
官方答疑:OpenJDK 存储库中的源代码与用于构建 Oracle JDK 的代码之间有什么区别?
答:非常接近。
我们的 Oracle JDK 版本构建过程基于 OpenJDK 7 构建,只添加了几个部分,例如部署代码,其中包括 Oracle 的 Java 插件和 Java WebStart 的实现,以及一些闭源的第三方组件,如图形光栅化器,一些开源的第三方组件,如 Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未来,我们的目的是开源 Oracle JDK 的所有部分,除了我们考虑商业功能的部分。
-
Oracle JDK 大概每 6 个月发一次主要版本(从 2014 年 3 月 JDK 8 LTS 发布到 2017 年 9 月 JDK 9 发布经历了长达 3 年多的时间,所以并不总是 6 个月),而 OpenJDK 版本大概每三个月发布一次。但这不是固定的,我觉得了解这个没啥用处。详情参见:https://blogs.oracle.com/java-platform-group/update-and-faq-on-the-java-se-releasecadence 。
-
OpenJDK 是一个参考模型并且是完全开源的,而 Oracle JDK 是 OpenJDK 的一个实现,并不是完全开源的;(个人观点:众所周知, JDK 原来是 SUN 公司开发的,后来 SUN 公司又卖给了 Oracle 公司, Oracle 公司以 Oracle 数据库而著名,而 Oracle 数据库又是闭源的,这个时候Oracle 公司就不想完全开源了,但是原来的 SUN 公司又把 JDK 给开源了,如果这个时候Oracle 收购回来之后就把他给闭源,必然会引其很多 Java 开发者的不满,导致大家对 Java 失去信心,那 Oracle 公司收购回来不就把 Java 烂在手里了吗!然后, Oracle 公司就想了个骚操作,这样吧,我把一部分核心代码开源出来给你们玩,并且我要和你们自己搞的 JDK 区分下,你们叫 OpenJDK,我叫 Oracle JDK,我发布我的,你们继续玩你们的,要是你们搞出来什么好玩的东西,我后续发布 Oracle JDK 也会拿来用一下,一举两得!) OpenJDK 开源项目:https://github.com/openjdk/jdk
-
Oracle JDK 比 OpenJDK 更稳定(肯定啦, Oracle JDK 由 Oracle 内部团队进行单独研发的,而且发布时间比 OpenJDK 更长,质量更有保障)。OpenJDK 和 Oracle JDK 的代码几乎相同(OpenJDK 的代码是从 Oracle JDK 代码派生出来的,可以理解为在 Oracle JDK 分支上拉了一条新的分支叫 OpenJDK,所以大部分代码相同),但 Oracle JDK 有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择 Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用 OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到 Oracle JDK 就可以解决问题;
-
在响应性和 JVM 性能方面, Oracle JDK 与 OpenJDK 相比提供了更好的性能;
-
Oracle JDK 不会为即将发布的版本提供长期支持(如果是 LTS 长期支持版本的话也会,比如JDK 8,但并不是每个版本都是 LTS 版本),用户每次都必须通过更新到最新版本获得支持来获取最新版本;
-
Oracle JDK 使用 BCL/OTN 协议获得许可,而 OpenJDK 根据 GPL v2 许可获得许可。
什么是SPI,SPI和API有什么区别?
何谓 SPI?
SPI 即 Service Provider Interface ,字面意思就是:“服务提供者的接口”,一般理解是:专门提供给服务提供者或者扩展框架功能的开发者去使用的一个接口。
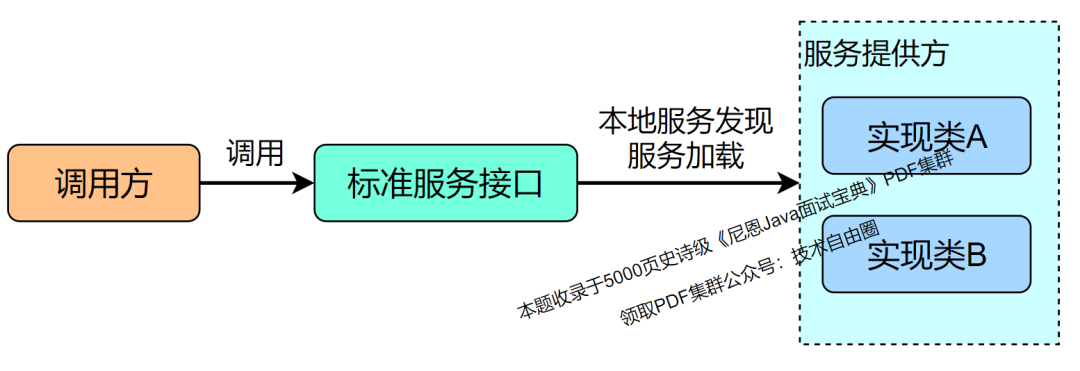
SPI 的合作作用:解耦。
SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及Dubbo 的扩展实现等等。
Java SPI 的应用Demo
Java SPI 是JDK内置的一种服务提供发现机制。
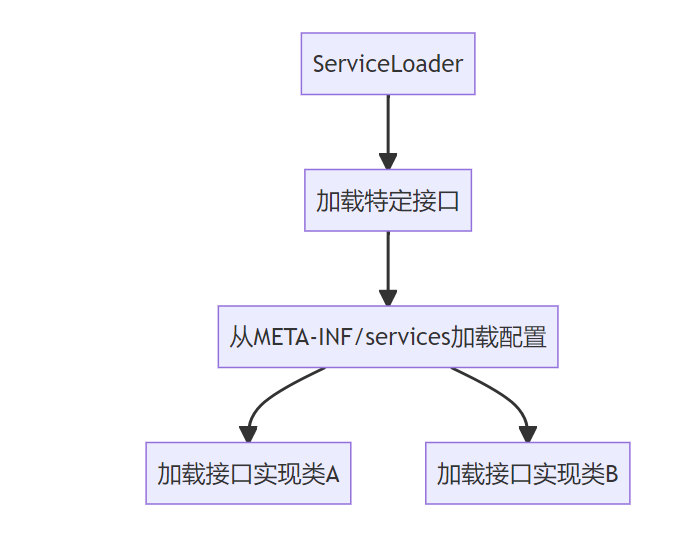
我们一般希望模块直接基于接口编程,调用服务不直接硬编码具体的实现,而是通过为某个接口寻找服务实现的机制,通过它就可以实现,不修改原来jar的情况下, 为 API 新增一种实现。
Java SPI 有点类似 IOC 的思想,将装配的控制权移到了程序之外。
对于 Java 原生 SPI,只需要满足下面几个条件:
-
1.定义服务的通用接口,针对通用的服务接口,提供具体的实现类
-
2.在 src/main/resources/META-INF/services 或者 jar包的 META-INF/services/ 目录中,新建一个文件,文件名为 接口的全名。文件内容为该接口的具体实现类的全名
-
3.将 spi 所在 jar 放在主程序的 classpath 中
-
4.服务调用方用java.util.ServiceLoader,用服务接口为参数,去动态加载具体的实现类到JVM中,然后就可以正常使用服务了
上面这一大段代码示例如下
1.接口和实现类
接口
public interface DemoService {
void sayHello();
}
实现类
public class RedService implements DemoService{
@Override
public void sayHello() {
System.out.println("red");
}
}
public class BlueService implements DemoService{
@Override
public void sayHello() {
System.out.println("blue");
}
}
2.配置文件
META-INF/services文件夹下,路径名字一定分毫不差写对,配置文件名com.example.demo.spi.DemoService
文件内容
com.example.demo.spi.RedService
com.example.demo.spi.BlueService
3.jar包例如jdbc的需要导入classpath,我们这个示例程序自己写的代码就不用了
4.实际调用
public class ServiceMain {
public static void main(String[] args) {
ServiceLoader<DemoService> spiLoader = ServiceLoader.load(DemoService.class);
Iterator<DemoService> iteratorSpi = spiLoader.iterator();
while (iteratorSpi.hasNext()) {
DemoService demoService = iteratorSpi.next();
demoService.sayHello();
}
}
}
调用结果
red
blue
Java SPI 实际上是“基于接口的编程+ 配置文件”组合实现的动态加载机制。
SPI 有点类似 Spring IoC容器, 用于加载实例。
在 Spring IoC 容器中具有以下几种作用域:
-
singleton:单例模式,在整个Spring IoC容器中,使用singleton定义的Bean将只有一个实例,适用于无状态bean;
-
prototype:原型模式,`每次通过容器的getBean方法获取prototype定义的Bean时,都将产生一个新的Bean实例,适用于有状态的Bean;
但是SPI 与Spring 不同:
-
SPI 缺少实例的维护,作用域没有定义singleton和prototype的定义,不利于用户自由定制。
-
ServiceLoader不像 Spring,只能一次获取所有的接口实例, 不支持排序,随着新的实例加入,会出现排序不稳定的情况
SPI 使用场景
很多开源第三方jar包都有基于SPI的实现,在jar包META-INF/services中都有相关配置文件。
如下几个常见的场景:
1)JDBC加载不同类型的数据库驱动
2)Slf4j日志框架
3)Dubbo框架
看看 Dubbo 的扩展实现,就知道 SPI 机制用的多么广泛:

SPI 和 API 在使用上的区别?
那 SPI 和 API 有啥区别?
SPI 全称:Service Provider Interface , 服务提供接口
API 全称:Application Programming Interface, 即应用程序编程接口
说到 SPI 就不得不说一下 API 了,从广义上来说它们都属于接口,而且很容易混淆。
下面先用一张图说明一下:
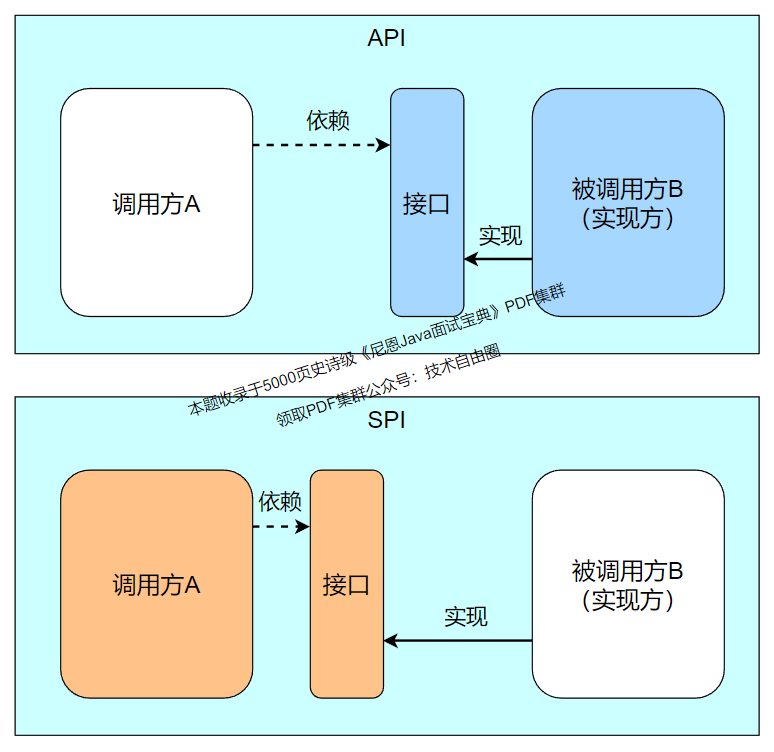
一般模块之间都是通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API ,这种接口和实现都是放在实现方的。
当接口存在于调用方这边时,就是 SPI ,由接口调用方确定接口规则,然后由不同的厂商去根绝这个规则对这个接口进行实现,从而提供服务。
SPI 和 API 在本质上的区别
SPI 区别于API模式,本质是一种服务接口规范定义权的转移,从服务提供者转移到服务消费者。
怎么理解呢?
API指:Provider 定义接口
服务提供方定义接口规范并按照接口规范完成服务具体实现,消费者需要遵守提供者的规则约束,否则无法消费
SPI指:consumer 定义接口
由消费方定义接口规范,服务提供者需要按照消费者定义的规范完成具体实现。否则无法消费。
SPI从理论上看,是一种接口定义和实现解耦的设计思路,以便于框架的简化和抽象;从实际看,是让服务提供者把接口规范定义权交岀去,至于交给谁是不一定的。
SPI定义权可以是服务消费者,也可以是任何一个第三方。一旦接口规范定义以后,只有消费者和服务提供者都遵循接口定义,才能匹配消费。
两者唯一的差别,在于服务提供者和服务消费者谁更加强势,仅此而已。
举个不恰当的例子:A国是C国工业制成品的消费国,C国只能提供相比A国更具性价比的产品,担心生产的产品会无法在A国销售。这时候,生产者必须遵守A国的生产标准。
谁有主动权,谁就有标准的制定权。在系统架构层面:谁是沉淀通用能力的平台方,谁就是主动权一方。
SPI 源码分析
1、SPI的核心就是ServiceLoader.load()方法
总结如下:
-
调用
ServiceLoader.load(),创建一个ServiceLoader实例对象 -
创建
LazyIterator实例对象lookupIterator -
通过
lookupIterator.hasNextService()方法读取固定目录META-INF/services/下面service全限定名文件,放在Enumeration对象configs中 -
解析configs得到迭代器对象
Iterator<String> pending -
通过
lookupIterator.nextService()方法初始化读取到的实现类,通过Class.forName()初始化
从上面的步骤可以总结以下几点
-
实现类工程必须创建定目录
META-INF/services/,并创建service全限定名文件,文件内容是实现类全限定名 -
实现类必须有一个无参构造函数
2、ServiceLoader核心代码介绍
public final class ServiceLoader<S>
implements Iterable<S>
{
private static final String PREFIX = "META-INF/services/";
// The class or interface representing the service being loaded
private final Class<S> service;
// The class loader used to locate, load, and instantiate providers
private final ClassLoader loader;
// The access control context taken when the ServiceLoader is created
private final AccessControlContext acc;
// Cached providers, in instantiation order
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// The current lazy-lookup iterator
private LazyIterator lookupIterator;
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
通过方法iterator()生成迭代器,内部调用LazyIterator实例对象
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
内部类LazyIterator,读取配置文件META-INF/services/
private class LazyIterator
implements Iterator<S>
{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public void remove() {
throw new UnsupportedOperationException();
}
}
SPI 的优缺点?
通过 SPI 机制能够大大地提高接口设计的灵活性,
但是 SPI 机制也存在一些缺点,比如:
-
需要遍历加载所有的实现类,不能做到按需加载,这样效率还是相对较低的。
-
当多个 ServiceLoader 同时 load 时,会有并发问题。
-
SPI 缺少实例的维护,作用域没有定义singleton和prototype的定义,不利于用户自由定制。
-
ServiceLoader不像 Spring,只能一次获取所有的接口实例, 不支持排序,随着新的实例加入,会出现排序不稳定的情况,作用域没有定义singleton和prototype的定义,不利于用户自由定制















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









