







Is Auto-Regressive Language Model Simply Memorizing Answers or Learning to Reason?
自回归模型的“few-step逻辑”的来源:模型能输出一个个比较短的logic chunk,这些chunk内部是合理的,且相邻的chunk往往是合理的,但是相隔较远的chunk往往是不合理的。从强化学习的角度来看,这就是imitation learning的error accumulation。这也是为什么language model一般zero-shot reasoning能力不强 - language model学到了few-step这种流式的预测,却没有一个精心设计的mechanism(这往往需要动模型结构)去强化推理所需要的planning(如backup)和logic(如many-step/skip-step的逻辑)。因此GPT这个自回归模型架构既不是在背答案(因为有interpolate的能力,即有限的continuous few-step逻辑),也不是在推理(没有planning和many-step/skip-step逻辑)。
-
自回归语言模型简介:自回归语言模型以GPT-2为代表,采用next-token prediction的无监督学习目标。这种模型通过在训练阶段将注意力矩阵mask成三角矩阵来实现,这种mask被称为因果掩码。这种模型的优势在于预训练的可扩展性。
-
GPT系列的发展:从最早的GPT到GPT-3,模型在预训练阶段通过next-token prediction任务积累了大量知识。GPT-2时期,模型已经可以应用于一些实际场景,如小说续写、情感机器人等。GPT-3则在不进行微调的情况下也能完成一些简单任务。
-
推理能力的探讨:早期GPT模型并不具备推理能力。直到GPT-4,模型在预训练后展现出一定的零样本推理能力,如数学推导和逻辑判断。但这并不意味着模型本身具有推理能力,而是因为它在预训练阶段接触了大量可序列化的数学和代码数据。
-
模型的工作原理:自回归模型在测试时通过在词汇表中插值,找到与预训练阶段见过的分布最接近的分布,然后预测下一个token。模型在预测时缺乏长远的规划和多步骤逻辑。
-
神经元的解释性:研究指出,浅层语言模型中的神经元可以通过字典学习分解为单语义的token分布。而深层模型则可能在进行更复杂的整合和优化。
-
CRATE-LM模型:作者提出了一种基于CRATE架构的语言模型,该模型具有更好的神经元解释性,支持无损编辑。这表明在较小的GPT-2模型中,并未发现任何规划或推理机制。
-
未来研究方向:尽管语言模型本身不具备推理能力,但其出色的表示能力可以用于学习小的推理/规划头。未来研究者应从模型架构本身出发,探索新的方法,这也将是通用机器人模型的主要研究方向。
当前 AI 模型的推理能力:从“记住”到“推导”
现代 AI 模型(如 GPT)并非简单地“记住”答案,而是通过复杂的推理过程逐步生成每个词,形成连贯的回答。这一过程依赖于对上下文的理解和高维向量的计算,而不是简单的记忆检索。以下通过问题“乔布斯是谁?”的例子,详细解析 Transformer 模型生成答案的完整流程。
一、分词与嵌入向量:从文本到数学表示
目标:将自然语言分解为计算机可以处理的数值表示。
过程:模型首先对输入文本进行“分词”(tokenization),将其分解为更小的语言单位(如词或子词)。以“乔布斯是谁?”为例,分词结果可能是:
- “乔布斯”、“是”、“谁”、“?”
分词后,模型会将这些单位转换为高维的 嵌入向量(Embeddings)。嵌入向量是用来表示词语语义的数值向量。
嵌入向量:语言的数学表达
嵌入向量是一种将语言映射到高维空间的方式。它不仅表示词语的语义,还捕捉它们的语境关系。简单来说:
- 语义相近的词会更靠近: 例如,“乔布斯”和“苹果公司”在向量空间中的距离较近,而“乔布斯”和“香蕉”则距离较远。
- 语境敏感: 嵌入向量能根据句子上下文动态调整。例如,“苹果”在“苹果公司”和“吃苹果”中的嵌入向量会不同。
这些向量并非随机生成,而是通过模型在海量语料上的训练逐步学习得到的。每个数字反映了模型对词语语义某个方面的理解。
嵌入向量的特点:
- 语义相似性:相似的词在向量空间中会更靠近。例如,“乔布斯”的向量如果与“苹果公司”的向量距离较近,表示模型理解它们的关联性。
- 语境敏感:嵌入向量可以根据上下文动态变化。例如,“苹果”在“苹果公司”和“吃苹果”中的含义不同,嵌入向量也会不同。
- 语义计算能力:嵌入向量还能捕捉隐含的逻辑关系。例如,向量运算“国王 - 男人 + 女人 ≈ 女王”说明模型能够识别词语的隐式语义关系。
二、生成 Q、K、V 向量:自注意力机制的核心
在生成嵌入向量后,Transformer 模型进一步为每个词创建三组新向量:Query(Q)、Key(K) 和 Value(V)。这些向量是自注意力机制的核心,通过它们的交互,模型能够理解句子中词语之间的关系,并为上下文表示的计算奠定基础。
Q、K、V 向量的生成与意义
生成过程:每个词的 Q、K、V 向量是通过对嵌入向量进行线性变换得到的。这些线性变换由学习得来的参数矩阵完成。
Query(Q): 表示当前词的“提问需求”。
- Q 向量告诉模型,该词需要从其他词获取哪些信息。例如,“乔布斯”的 Q 向量表示它“询问”的内容。
Key(K): 表示当前词的“特征”。
- K 向量帮助其他词判断是否与当前词相关联。例如,“谁”的 K 向量是它在语境中的特征标识。
Value(V): 表示当前词携带的信息值。
- V 向量是当前词对信息传递的贡献,用于生成最终的上下文表示。
功能定位:
在自注意力机制中,Q 是“提问者”,K 是“被提问者”,V 则是携带“答案”的内容。这三组向量为词语之间的交互奠定了基础。

Q、K、V 向量的意义与应用
通过生成 Q、K、V 向量,模型实现了对句子中词语关系的动态建模。这种机制使 Transformer 模型能够灵活处理复杂的语义结构,例如:
长距离关系建模:
在翻译任务中,“乔布斯是谁?” 的注意力机制会捕捉到“乔布斯”和“谁”之间的语义关联,而不会被中间的“是”干扰。
语义提取:
在问答系统中,自注意力机制帮助模型提取问题的核心信息,并匹配答案内容。
三、点积计算:衡量词语间的相似性
在生成 Query(Q) 和 Key(K) 向量后,模型通过点积计算评估词语之间的相似性。这一步是自注意力机制的核心,它帮助模型识别句子中各词的语义关联程度,从而更高效地分配注意力,关注句子中的关键词。 




如何影响模型的注意力分配
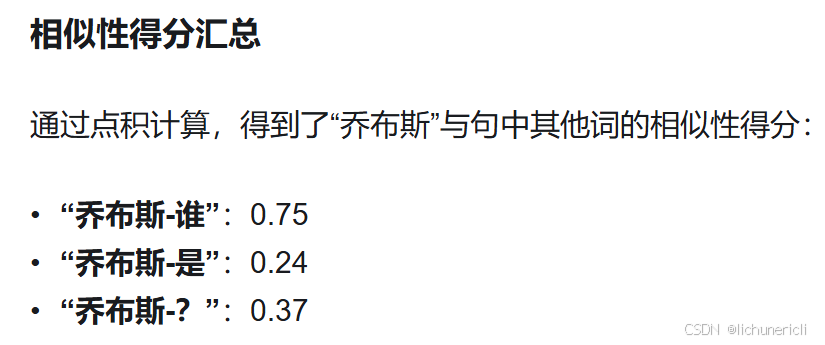
相似性得分是模型注意力分布的基础。通过 Softmax 函数,这些得分会被转化为概率分布,表示当前词对其他词的关注程度。
- 在本例中,“乔布斯”和“谁”的相似性得分最高(0.75),表明模型识别到它们之间的语义关系最紧密。因此,在后续处理中,“谁”的信息会对“乔布斯”的上下文表示贡献最大。
点积计算的意义
点积计算让模型能够捕捉句子中各词的关联性,从而更精准地分配注意力。这为后续的信息聚合(如加权求和生成上下文向量)奠定了基础,使得模型能够生成更符合语境的输出。在本例中,模型通过注意力机制集中关注“乔布斯”和“谁”的关系,从而帮助回答问题“乔布斯是谁?”。
四、注意力权重的计算:为上下文加权求和提供依据
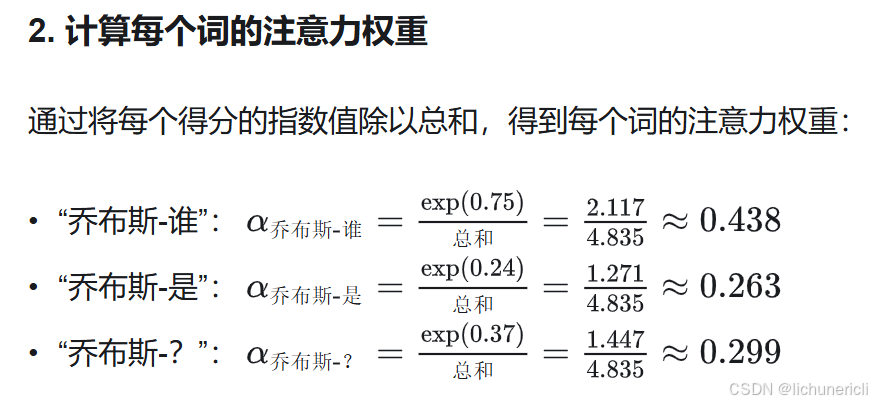
在点积计算得出相似性得分后,模型需要将这些分数转化为 注意力权重(Attention Weights),以指导上下文生成的过程。注意力权重的计算依赖于 Softmax 函数,这一归一化方法可以将原始得分转换为概率分布,总和为 1,表示模型对每个词的关注程度。
示例:计算“乔布斯”的注意力权重
根据前面计算,“乔布斯”与句中其他词的相似性得分如下:
- “乔布斯-谁”:0.75
- “乔布斯-是”:0.24
- “乔布斯-?”:0.37

作用:指导上下文生成
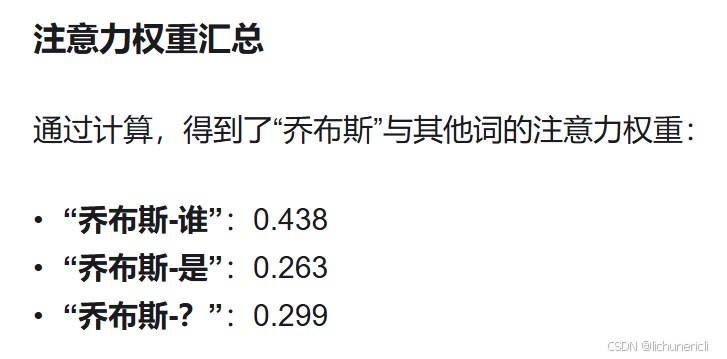
注意力权重是模型分配给每个词的重要性指标。权重值越高,表示模型在生成上下文向量时对该词的关注度越大。例如:
- “乔布斯-谁” 的权重最高(0.438),表明模型认为“谁”的信息对理解“乔布斯”的语义最重要,因此“谁”的 Value 向量对上下文向量的贡献最大。
- “乔布斯-是” 的权重最低(0.263),说明模型认为“是”的信息对当前语境的贡献较小。
总结
通过 Softmax 函数,模型将点积计算的相似性得分转化为概率分布,量化了每个词的重要性。注意力权重确保模型能够动态调整对句中词语的关注程度,从而在生成上下文向量时聚焦于语义关联更强的词。这一步为生成精准且符合语境的回答奠定了基础。
五、上下文向量生成:让模型理解句子语境
在计算出每个词的注意力权重后,模型会通过对每个词的 Value(V)向量 进行加权求和,生成一个新的 上下文向量(Context Vector)。这个上下文向量是对当前词与其他词关系的综合表示,帮助模型更准确地理解句子的语境。

示例:计算“乔布斯”的上下文向量
以句子“乔布斯是谁?”为例,计算“乔布斯”的上下文向量。以下是具体步骤:




总结
通过注意力权重和 Value 向量的加权求和,模型生成了包含语境信息的上下文向量。这一步让 Transformer 模型能够从全局角度理解句子中词语的语义关系,为后续任务(如翻译或问答)提供了精准的语义表示。
六、答案生成:逐步预测词汇
当模型生成了输入句子的 上下文向量(Context Vector) 后,就进入了答案生成阶段。这一阶段的核心任务是根据上下文,逐步预测下一个最可能的词,最终构建完整的答案。以下是具体的流程和计算方法。



4. 选择下一个词
核心逻辑:从概率分布中选取概率最高的词作为当前步骤的输出。在本例中,“苹果”的概率最高(0.341),因此模型预测下一个词为“苹果”。
5. 逐步生成完整答案
迭代过程:
- 将“苹果”加入答案并更新语境。
- 基于更新的上下文向量,重复步骤 1-4,生成下一个词,例如“的”、“创始人”。
- 继续迭代,直至生成完整答案:“乔布斯 是 苹果 的 创始人”。
总结:Transformer 的生成逻辑
- 语境动态更新: 每步生成的词影响后续上下文,确保答案连贯。
- 概率驱动生成: Softmax 提供合理分布,选择最符合语境的词。
- 长序列建模能力: 自注意力机制捕捉长距离语义依赖,生成精准输出。
从输入问题到逐步生成答案,Transformer 模型展现了其强大的语义理解和生成能力,为翻译、问答等任务奠定了技术基础。
相关文献参考
- Vaswani et al., 2017 - Attention is All You Need
深入探讨了 Transformer 的自注意力机制和逐步生成答案的过程。
链接:https://arxiv.org/abs/1706.03762
- Radford et al., 2019 - Language Models are Few-Shot Learners
描述了 GPT 系列中如何通过上下文和概率分布实现逐步答案生成。
链接:https://arxiv.org/abs/2005.14165
- Brown et al., 2020 - Language Models are Few-Shot Learners
对逐步生成和大规模预训练的关系进行了深入探讨,适用于长序列生成任务。
链接:https://arxiv.org/abs/2005.1416
AI的推理能力:
- 目前,AI的推理能力存在争议。虽然OpenAI宣称其模型o1通过强化学习和思维链推理能够进行复杂的推理任务,但这种能力是否等同于人类的推理仍受到质疑。
- OpenAI的定义中,AI的推理是指模型能够通过“思考”时间转化为更好的结果,但这与传统理解的推理有所不同。
- Apple的研究人员认为,大语言模型的所谓推理能力可能只是复杂的模式匹配。
AI的“记忆”:
- AI的记忆基于模式识别,它通过从数据中提取关键特征来构建分类模型,从而对新数据进行分类。
- 这种模式匹配的过程类似于“背书”,因为AI在回答问题时是在将其与训练得到的模式进行匹配。
未来的发展方向
- 深度神经网络的目标:Bengio提出,未来的深度神经网络应实现类似人类认知系统中的System2,即具有逻辑分析、规划、推理和语言表达能力的系统。
- 推理的类型:
- 关联推理:AI在这方面表现良好,能够发现变量间的相关性。
- 因果推理:AI在这方面的能力较弱,需要进一步研究,以确定变量间的因果关系。
当前的挑战与突破
- AI的不透明性问题:为了使AI的推理过程可见,研究者们正在努力打破AI的黑箱问题,使其变得更加透明。
- 泛化能力的提升:研究者们在探索如何将AI在特定领域(如数学、物理)的推理能力泛化到更一般的情况。
结论
- 虽然AI在模式匹配和关联推理方面表现出色,但在因果推理和泛化能力方面仍有限制。
- AI的推理能力尚未达到人类水平的理解力和逻辑推理能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









