









ShardingSphere 基于分片边界的范围分片算法 BOUNDARY_RANGE
这种分片算法适合存储分片范围不均衡的数据,如果每一个范围的数据要提升性能的话还可以 对该范围的数据在做分库的处理或者缩小分片范围分更多的表来处理
配置方式比较简单:以下下是一个完整的配置案例
#基于分片边界的范围分片算法
#打印sql
spring.shardingsphere.props.sql-show=true
#数据库的分库策略
spring.shardingsphere.rules.sharding.tables.m_user.database-strategy.standard.sharding-column=buMen
spring.shardingsphere.rules.sharding.tables.m_user.database-strategy.standard.sharding-algorithm-name=hash-mod
# 配置具体的分库规则(分库的字段+分库的算法=分库规则)这里是使用HASH_MOD的算法
spring.shardingsphere.rules.sharding.sharding-algorithms.hash-mod.type=HASH_MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.hash-mod.props.sharding-count=2
#lcg_user表的分表的策略
spring.shardingsphere.rules.sharding.tables.m_user.actual-data-nodes=d$->{0..1}.m_user_$->{0..1}
#配置表的分片算法
spring.shardingsphere.rules.sharding.tables.m_user.table-strategy.standard.sharding-column=price
#这里的算法名称自己随便取-基于边界的范围分片算法
spring.shardingsphere.rules.sharding.tables.m_user.table-strategy.standard.sharding-algorithm-name=boundary-range
#BOUNDARY_RANGE 是内置的算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.boundary-range.type=BOUNDARY_RANGE
spring.shardingsphere.rules.sharding.sharding-algorithms.boundary-range.props.sharding-ranges= 41
# 配置lcg_user的id采用雪花算法生成全局id策略
spring.shardingsphere.rules.sharding.tables.m_user.key-generate-strategy.column=id
spring.shardingsphere.rules.sharding.tables.m_user.key-generate-strategy.key-generator-name=SNOWFLAKE
下边就配置做一个简单的介绍:
#type=BOUNDARY_RANGE 这是基于分片边界的范围分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.boundary-range.type=BOUNDARY_RANGE
#sharding-ranges 用来配置分片的范围 下列配置的意思是 [0-41) 分配到m_user_0 ,[41-无穷) 注意:这里的分片范围都是左闭右开的 分配到m_user_1
spring.shardingsphere.rules.sharding.sharding-algorithms.boundary-range.props.sharding-ranges= 41
再举例:如果数据是分为三片的话可以如下的配置 [1-41) 存储到分片0 [41-101)存储到分片1 [101-无穷)存储到分片2
spring.shardingsphere.rules.sharding.sharding-algorithms.boundary-range.props.sharding-ranges= 41,101
因为上述的配置案例采用的是分库分表的方式:所以数据的存储是下图的存储方式
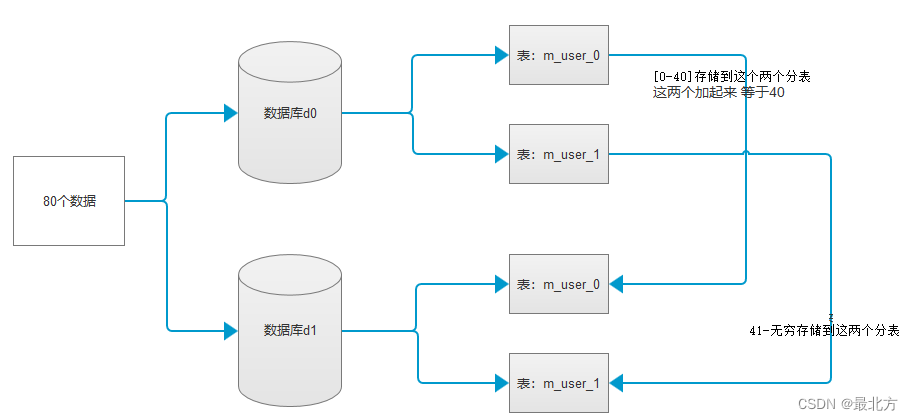
根据图中所示:如果添加分库的话那么 基于分片边界的范围分片算法 的分片会把同一个范围的数据分到不同库中的相同的分片表中,他们的和等于该分片范围的大小















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









