






随着捕获的数据的数量每年增加,我们的存储也需要增加。很多公司正在认识到“数据为王”这一道理,但是我们如何分析这些数据呢?答案就是“通过Hadoop”。在这篇文章中,也是三部曲中的第一篇,Steven Haines 对Hadoop的架构作了综述,并从一定高度上演示了如何编写MapReduce应用程序。
在数据处理的发展进程中,我们从文件转到关系型数据库,从关系型数据库转到NoSQL数据库。实质上,随着捕获的数据的数据增加,我们的需求也在增加,传统的模式已不能胜任。那些老的数据库能处理好的数据大小是以MB或GB为单位的,但是现在很多公司认识到“数据为王”,捕获的数据数量是以TB和PB为单位的。即使采用NoSQL存储数据,“我们如何分析如此数量的数据?”这一问题依然存在。
对于这一问题最流行的答案就是:"Hadoop".Hadoop 是一个开源框架,用于开发和执行用来处理巨大数量数据的分布式应用。Hadoop 用来运行在大型的集群上,集群内的商品机可以是你的数据中心内不正在使用的机器,或者甚至是 Amazon EC2 映像。运行在商品机上的危险当然就是如何处理故障(failure)。Hadoop的架构假设硬件会产生故障,因此,它能够很出色地应对大部分故障。而且,Hadoop的架构允许它近乎线性地伸缩,因此当对处理能力的需求增加时,唯一的限制就是你向集群添加更多机器的预算。
这篇文章将会对Hadoop的架构作一概述,描述它如何实现上面所说的各种亮点,并从一定高度上演示如何编写MapReduce应用程序。
Hadoop 架构
在一定高度上来说,Hadoop的哲学概念就是推着分析程序靠近它打算分析的数据,而非要求程序跨网络地读取数据。
因此,Hadoop 提供了自己的文件系统,贴切地命名为Hadoop File System(HDFS)。当你上传数据到HDFS时,Hadoop将会在整个集群内分割你的数据(保存数据的多份副本以防硬件故障),然后会部署你的程序到包含该程序准备操作的数据的机器上。
像许多NoSQL数据库那样,HDFS采用键(key)和值(value)而非关系组织数据。换句话说,每块数据都有一个唯一的键(key),以及与该键相关联的值。键之间的关系,如果存在的话,由程序定义,而非HDFS。并且实际上,你必须对你的问题域换一种稍微不同的方式思考,才能意识到Hadoop的强大威力(见下面关于MapReduce的章节)。
组成Hadoop的组件为:
* HDFS:Hadoop文件系统是一种分布式文件系统,被设计用来在集群内跨节点地保存海量数据(此处海量被定义为文件的大小为100+TB)。Hadoop提供API及命令行接口与HDFS交互。
* MapReduce Application:下一章节将评论MapReduce的细节,但是在此简单陈述,MapReduce 是一种函数式编程范式,用来分析你HDFS的单个记录。然后它将结果组装成可用的解决方案。Mapper负责数据处理步骤,而Reducer接受Mapper的输出,并对同一键值的数据排序。
* Partitioner:partitioner负责把特定的分析问题划分成可行的数据块以供各种Mapper之用。HashPartioner 是一种partitioner,用来根据HDFS中的数据的行来划分工作,但是你可以随便创作自己的partitioner,如果你需要采用不同的方式划分你的数据。
* Combiner:如果由于某些原因,你想进行local reduce,即在数据送回到Hadoop之前combine数据,那么你需要创作一个combiner。一个combiner执行reduce步骤,即将值(value)根据键(key)分组结合,但是是在返回键/值(key/value)对到Hadoop进行适当的reduction之前,在单一节点上操作。
* InputFormat:大部分时间默认的reader会工作正常,但是如果你的数据不是按照标准的方式进行的格式化,即“key, value”或者“key[tab]value”,那么你将需要定制一个InputFormat实现。
* OutputFormat:你的MapReduce应用将会用InputFormat读取数据,然后通过OutputFormat将数据写出。标准格式,例如“key[tab]value”,是被支持的,但是如果你想作别的事情,那么你需要创作你自己的OutputFormat实现。
又Hadoop应用被部署在支持高度伸缩性和弹性的设施上,以下组件也被包含:
* NameNode: NameNode是HDFS的主节点,控制从节点的DataNode的守护进程(daemon);它知道你所有的数据存放在何处,知道数据如何被拆分成块,知道这些数据块被部署在哪个节点上,知道分布式文件系统的整体工作状态。简而言之,它是整个Hadoop集群中最重要的节点。每个集群都有一个NameNode,并且NameNode是Hadoop集群中的single-point of failure(SPOF)。
* Secondary NameNode:Secondary NameNode监视HDFS集群的状态,并且对保存在NameNode中的数据拍摄快照(snapshot)。如果NameNode产生故障,Secondary NameNode将会被用来取代NameNode的位置。然而,这确实需要人工干预,因此没有从NameNode到Secondary NameNode的自动失效备援(failover),但是,拥有Secondary NameNode将会确保数据丢失最小化。同NameNode一样,每个集群也仅有一个Secondary NameNode。
* DataNode:Hadoop集群中的每个从节点包含一个DataNode。DataNode负责进行数据管理:它从HDFS读取它的数据块,管理每个物理节点上的数据,向NameNode报告数据管理状态。
* JobTracker:JobTracker守护进程是你的应用与Hadoop本身之间的连线。每个Hadoop集群都有一个配置好的JobTracker,当你提交代码到Hadoop集群执行时,JobTracker负责构建执行计划。执行计划包括决定包含操作数据的节点、安排节点之间的数据通信、监视正在运行的任务(task)和重新开启任务如果任务失败。
* TaskTracker:同数据存储采用主/从(master/slave)架构一样,代码执行也采用了主/从(mater/slave)架构。每个从节点拥有一个TaskTracker守护进程(daemon),该进程负责由JobTracker发送过来的任务,并同其他JobTracker通信job状态及心跳包。
图1尝试讲所有这些组件一起放在一张图中。
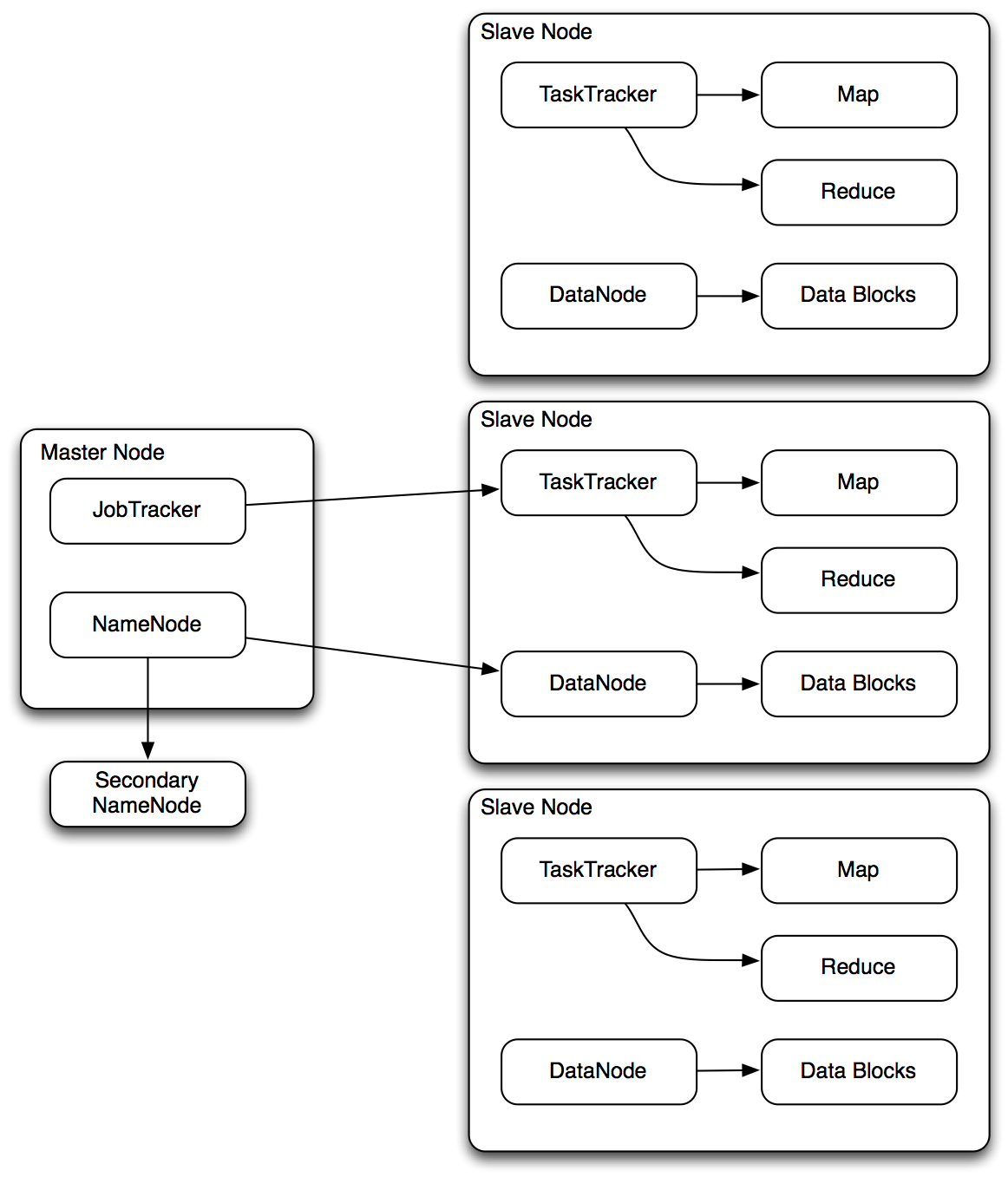 图1 Hadoop应用及设施交互
图1 Hadoop应用及设施交互图1显示了主节点与从节点之间的关系。主节点包含两个重要组件:NameNode,管理集群及负责所有数据;JobTracker,负责管理被执行的代码和所有TaskTracker守护进程。每个从节点都有TaskTracker守护进程和DataNode守护进程:TaskTracker从JobTracker处接收指令并执行map和reduce步骤,而DataNode从NameNode处接收数据并管理被从节点包含的数据。并且理所当然存在一个Secondary NameNode监听NameNode的更新。注意:注意图1仅仅显示JobTracker及NameNode同单一从节点通信,但实际上,它同集群内的所有从节点通信。MapReduce
MapReduce是一种函数式编程范例,非常适合运用于分布在大量计算机上的海量数据集的并行处理,换句话说,MapReduce是由Hadoop和本文中所描述的设施所支撑的应用程序范例。MapReduce,如同其名称暗示的那样,通过以下两步工作:
1.Map: map这一步实质上解决一个小问题:Hadoop的partitioner把问题划分成小的可解决的子集,并把这些子集分配给map进程去解决。2.Reduce: reducer整合(combine)各个map进程的结果,并形成MapReduce操作的输出。
我对Map的定义故意采用实质上这一字眼,是因为决定这一步骤采用Map这个名字的原因之一就是它的实现。虽然它确实解决小的可行的问题,但是它解决问题所采用的方式是将特定的键(keys)map 到特定的值(values)。例如,如果我们想统计一本书中每个单词出现的次数,我们的MapReduce应用程序将把每个单词作为键(key),每个单词出现的次数作为值(value)并输出。或者更具体点,这本书将会被分成句子或段落,Map这一步将会把每个单词map到它在句中出现的次数(或者是将每个单词的每次出现map为1),然后reducer通过将值(value)相加来组合(combine)键(key)。
列表1显示一段关于map和reduce函数如何运作以解决问题的Java伪码例子
Listing 1 - Java/Pseudocode for MapReduce
public void map( String name, String sentence, OutputCollector output ){ for( String word : sentence) output.collect(word,1); } public void reduce( String word, Iterator values, OutputCollector output){ int sum = 0; while(value.hasNext()){ sum += values.next().get(); } output.collect( word, sum); }Listing 1 的代码并不能真正意义上地运行,但是它从一定高度上描述了这样一个任务是如何用过少量的几行代码实现的。在提交你的job到Hadoop之前,你必须先把你的数据加载到Hadoop。它然后会采用块的形式分发你的数据到集群内的各个从节点中。然后当你提交你的job到Hadoop时,它会分发你的代码到从节点,让每个map和reduce task进程处理该从节点上的数据。你的map task将会对传给它的数据块(此例中假设为一个句子)中的每个词进行迭代,并输出单词作为键(key),“1”作为值(value)。reduce task然后将会接收被map到特定键(key)的值(value)的所有实例,例如,它或许有1000为1的值(value)被map到单词“apple”, 这意味着文本中存在1000个“apple”。reduce task 将所有值相加,并作为结果输出。然后你的Hadoop job将会被设定好处理从各个reduce task 返回的输出。
这种 思考方式与你不采用MapReduce解决这个问题时有所不同,但是它会变得更加清晰,因为下一篇文章将会是关于如何编写MapReduce应用,在其中我们将会编写几个能运行的例子。
总结
这篇文章描述了Hadoop是什么并对其架构给以了综述。Hadoop是一个开发和执行用于处理海量数据的应用的开源框架。它提供了在集群内大量机器上分发数据并推着分析代码到最靠近待分析数据的节点上这样一种设施。你的工作时编写MapReduce应用以此来运用该设施来分析你的数据。
这个系列中的下一篇文章,《采用Hadoop编写MapReduce应用程序》,将会演示如何设置开发环境,构建MapReduce应用,将会给你关于这种新范式如何工作一种好的感觉。然后,这个系列中的最后一篇将会带你轻松搞定设置和管理Hadoop生产环境。















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









