







闭包表是解决分层存储一个简单而又优雅的解决方案,它记录了表中所有的节点关系,并不仅仅是直接的父子关系。
在闭包表的设计中,额外创建了一张TreePaths的表(空间换取时间),它包含两列,每一列都是一个指向Comments中的CommentId的外键。
| 1 2 3 4 5 6 |
|
父子关系表:
| 1 2 3 4 5 6 |
|
在这种设计中,Comments表将不再存储树结构,而是将书中的祖先-后代关系存储为TreePaths的一行,即使这两个节点之间不是直接的父子关系;同时还增加一行指向节点自己,理解不了?就是TreePaths表存储了所有祖先-后代的关系的记录。如下图:
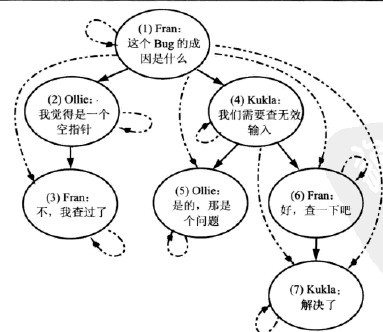
Comment表:
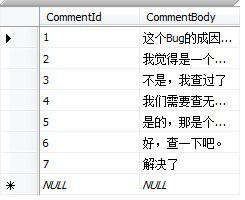
TreePaths表:
优点:
1、查询所有后代节点(查子树):
| 1 |
|
结果如下:
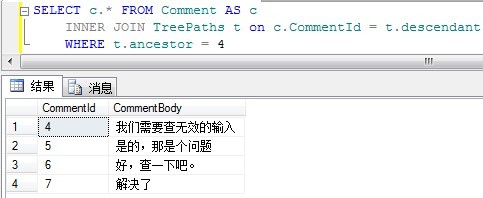
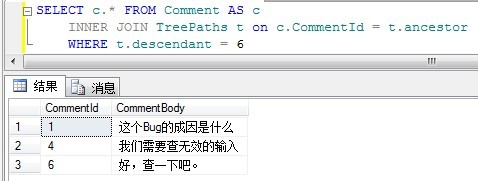
2、查询评论6的所有祖先(查祖先树):
| 1 |
|
显示结果如下:
3、插入新节点:
要插入一个新的叶子节点,应首先插入一条自己到自己的关系,然后搜索TreePaths表中后代是评论5的节点,增加该节点与要插入的新节点的"祖先-后代"关系。
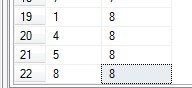
比如下面为插入评论5的一个子节点的TreePaths表语句:
| 1 2 3 4 |
|
执行以后:
至于Comment表那就简单得不说了。
4、删除叶子节点:
比如删除叶子节点7,应删除所有TreePaths表中后代为7的行:
| 1 |
|
5、删除子树:
要删除一颗完整的子树,比如评论4和它的所有后代,可删除所有在TreePaths表中的后代为4的行,以及那些以评论4的后代为后代的行:
| 1 2 3 |
|
另外,移动节点,先断开与原祖先的关系,然后与新节点建立关系的SQL语句都不难写。
另外,闭包表还可以优化,如增加一个path_length字段,自我引用为0,直接子节点为1,再一下层为2,一次类推,查询直接自子节点就变得很简单。















 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









