






1、DelayQueue 延时队列
JDK 中提供了一组实现延迟队列的API,位于Java.util.concurrent包下DelayQueue。DelayQueue是一个BlockingQueue(无界阻塞)队列,它本质就是封装了一个PriorityQueue(优先队列),PriorityQueue内部使用完全二叉堆(不知道的自行了解哈)来实现队列元素排序,我们在向DelayQueue队列中添加元素时,会给元素一个Delay(延迟时间)作为排序条件,队列中最小的元素会优先放在队首。队列中的元素只有到了Delay时间才允许从队列中取出。队列中可以放基本数据类型或自定义实体类,在存放基本数据类型时,优先队列中元素默认升序排列,自定义实体类就需要我们根据类属性值比较计算了。
先简单实现一下看看效果,添加三个order入队DelayQueue,分别设置订单在当前时间的5秒、10秒、15秒后取消。
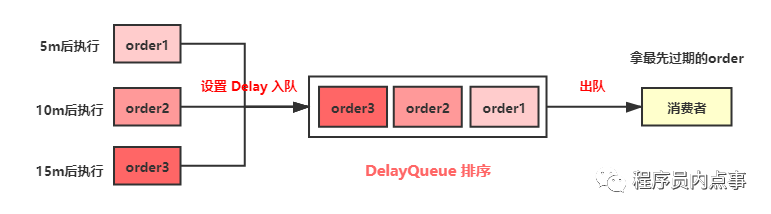
要实现DelayQueue延时队列,队中元素要implements Delayed 接口,这哥接口里只有一个getDelay方法,用于设置延期时间。Order类中compareTo方法负责对队列中的元素进行排序。
DelayQueue的put方法是线程安全的,因为put方法内部使用了ReentrantLock锁进行线程同步。DelayQueue还提供了两种出队的方法 poll() 和 take() , poll() 为非阻塞获取,没有到期的元素直接返回null;take() 阻塞方式获取,没有到期的元素线程将会等待。
优点:
1.效率高
缺点:
1.JVM重启,数据会全部丢失
2.可扩展性难度高
3.可能出现内存溢出异常
4.内部很多东西可能需要开发人员手动编写,很多东西没有封装
2、Quartz 定时任务
Quartz一款非常经典任务调度框架,在Redis、RabbitMQ还未广泛应用时,超时未支付取消订单功能都是由定时任务实现的。定时任务它有一定的周期性,可能很多单子已经超时,但还没到达触发执行的时间点,那么就会造成订单处理的不够及时。
这种方式最简单,启动一个计划任务,每隔一定时间(假设1分钟)去扫描一次数据库,通过订单时间来判断是否超时,然后进行UPDATE或DELETE操作
优点:
1.实现简单
2.高可用,支持集群(Quartz\TBSchedule\XX-JOB\Elastic-Job\Staurm\LTS等)
缺点:
1.服务器内存消耗大
2.存在延迟,比如每一份扫描一次,延迟就是1分钟。也可能更久,比如1分钟之内有大量数据,1分钟没处理完,那么下一分钟就会顺延
3.效率低
4.数据库压力大,订单数据过大时,数据库压力也会增加
3、Redisson DelayQueue
Redisson DelayQueue 是一种基于 Redis Zset 结构的延时队列实现。DelayQueue 中有一个名为 timeoutSetName 的有序集合,其中元素的 score 为投递时间戳。

- DelayQueue 会定时使用 zrangebyscore 扫描已到投递时间的消息,然后把它们移动到就绪消息列表中。
- DelayQueue 保证 Redis 不崩溃的情况下不会丢失消息,在没有更好的解决方案时不妨一试。
在数据库索引设计良好的情况下,定时扫描数据库中未完成的订单产生的开销并没有想象中那么大。
在使用 Redisson DelayQueue 等定时任务中间件时可以同时使用扫描数据库的方法作为补偿机制,避免中间件故障造成任务丢失。
4、Redis 过期回调
Redis 的key过期回调事件,也能达到延迟队列的效果,简单来说我们开启监听key是否过期的事件,一旦key过期会触发一个callback事件。需要Redis版本2.8以上。编写Redis过期回调监听方法,必须继承KeyExpirationEventMessageListener ,有点类似于MQ的消息监听。
优点:
1.可靠性,基于Redis自身的持久化特性实现消息持久化
2.高可用性,支持单击、主从、哨兵、集群多种模式
缺点:
1.开启键通知会对Redis产生额外的开销
2.目前键通知功能Redis并不保证消息必达,Redus客户端断开连接所以key会丢失
3.需要额外进行Redis的维护
5、RabbitMQ 延时队列
利用 RabbitMQ 做延时队列是比较常见的一种方式,而实际上RabbitMQ 自身并没有直接支持提供延迟队列功能,而是通过 RabbitMQ 消息队列的 TTL和 DXL这两个属性间接实现的。
先来认识一下 TTL和 DXL两个概念:
Time To Live(TTL) :
TTL 顾名思义:指的是消息的存活时间,RabbitMQ可以通过x-message-tt参数来设置指定Queue(队列)和 Message(消息)上消息的存活时间,它的值是一个非负整数,单位为微秒。
RabbitMQ 可以从两种维度设置消息过期时间,分别是队列和消息本身
- 设置队列过期时间,那么队列中所有消息都具有相同的过期时间。
- 设置消息过期时间,对队列中的某一条消息设置过期时间,每条消息
TTL都可以不同。
如果同时设置队列和队列中消息的TTL,则TTL值以两者中较小的值为准。而队列中的消息存在队列中的时间,一旦超过TTL过期时间则成为Dead Letter(死信)。
Dead Letter Exchanges(DLX)
DLX即死信交换机,绑定在死信交换机上的即死信队列。RabbitMQ的 Queue(队列)可以配置两个参数x-dead-letter-exchange 和 x-dead-letter-routing-key(可选),一旦队列内出现了Dead Letter(死信),则按照这两个参数可以将消息重新路由到另一个Exchange(交换机),让消息重新被消费。
x-dead-letter-exchange:队列中出现Dead Letter后将Dead Letter重新路由转发到指定 exchange(交换机)。
x-dead-letter-routing-key:指定routing-key发送,一般为要指定转发的队列。
队列出现Dead Letter的情况有:
- 消息或者队列的
TTL过期 - 队列达到最大长度
- 消息被消费端拒绝(basic.reject or basic.nack)
下边结合一张图看看如何实现超30分钟未支付关单功能,我们将订单消息A0001发送到延迟队列order.delay.queue,并设置x-message-tt消息存活时间为30分钟,当到达30分钟后订单消息A0001成为了Dead Letter(死信),延迟队列检测到有死信,通过配置x-dead-letter-exchange,将死信重新转发到能正常消费的关单队列,直接监听关单队列处理关单逻辑即可。
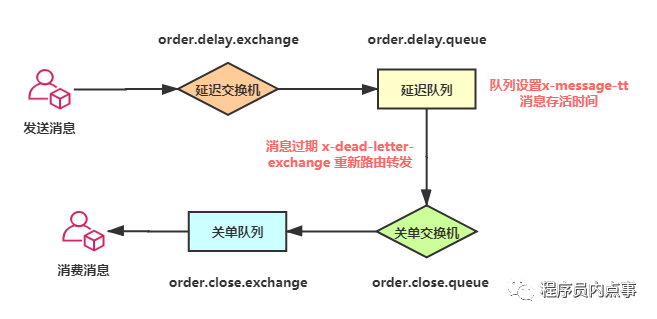
发送消息时指定消息延迟的时间
优点:
可靠性,消息持久化
高可用,非常方便部署负载均衡,实现高可用和吞吐量,轻松联合多个可用性区域和块
易管理和监控,使用HTTP-API,命令行工具或其他UI工具来管理和监控RabbitMQ
缺点:
系统可用性降低
系统复杂性变高
系统一致性问题
需要额外进行RabbitMQ的维护
6、时间轮
前边几种延时队列的实现方法相对简单,比较容易理解,时间轮算法就稍微有点抽象了。kafka、netty都有基于时间轮算法实现延时队列,下边主要实践Netty的延时队列讲一下时间轮是什么原理。
先来看一张时间轮的原理图,解读一下时间轮的几个基本概念
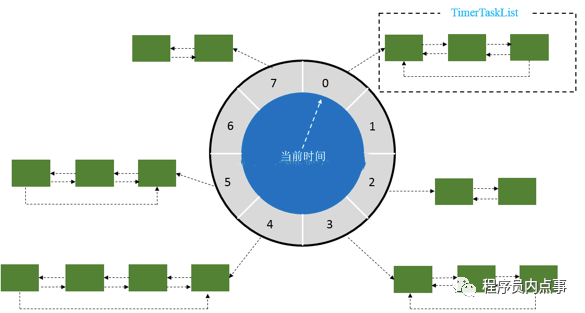
wheel :时间轮,图中的圆盘可以看作是钟表的刻度。比如一圈round 长度为24秒,刻度数为 8,那么每一个刻度表示 3秒。那么时间精度就是 3秒。时间长度 / 刻度数值越大,精度越大。
当添加一个定时、延时任务A,假如会延迟25秒后才会执行,可时间轮一圈round 的长度才24秒,那么此时会根据时间轮长度和刻度得到一个圈数 round和对应的指针位置 index,也是就任务A会绕一圈指向0格子上,此时时间轮会记录该任务的round和 index信息。当round=0,index=0 ,指针指向0格子 任务A并不会执行,因为 round=0不满足要求。
所以每一个格子代表的是一些时间,比如1秒和25秒 都会指向0格子上,而任务则放在每个格子对应的链表中,这点和HashMap的数据有些类似。
Netty构建延时队列主要用HashedWheelTimer,HashedWheelTimer底层数据结构依然是使用DelayedQueue,只是采用时间轮的算法来实现。
下面我们用Netty 简单实现延时队列,HashedWheelTimer构造函数比较多,解释一下各参数的含义。
ThreadFactory:表示用于生成工作线程,一般采用线程池;tickDuration和unit:每格的时间间隔,默认100ms;ticksPerWheel:一圈下来有几格,默认512,而如果传入数值的不是2的N次方,则会调整为大于等于该参数的一个2的N次方数值,有利于优化hash值的计算。TimerTask:一个定时任务的实现接口,其中run方法包装了定时任务的逻辑。Timeout:一个定时任务提交到Timer之后返回的句柄,通过这个句柄外部可以取消这个定时任务,并对定时任务的状态进行一些基本的判断。Timer:是HashedWheelTimer实现的父接口,仅定义了如何提交定时任务和如何停止整个定时机制。
优点:
效率高
如果使用Netty的HashedWheelTimer来实现,代码复杂比JDK的DelayQueue低
如果使用第三方中间件来实现,支持集群扩展,高吞吐量、消息持久化等。
缺点:
服务器重启后,数据全部丢失,怕宕机
集群扩展麻烦,难度较高
由于内存条件限制的原因,下单未付款的订单过多时,容易出现OOM异常
如果使用第三方中间件实现,需要额外进行第三方中间件的维护
总结:
当然也要分实际情况来决定,如果贵司已经在用RabbitMg的情况下,延迟任务肯定首选使用RabbitMQ来实现,如果贵司并没有使用RabbitMQ,就为了实现这样一个功能而强行使用RabbitMg,在一个稳定运行的系统中引入一个第三方中间件是需要考虑很多问题的,否则就会得不偿失。
目前大型互联网公司多多少少都会引入消息中间件,毕竟它拥有解耦、异步、流量削峰、日志处理等优点及功能,是分布式系统中重要的组件。在这种情况下,使用消息中间件来实现延迟任务就变得理所当然了。















 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









