









转载:https://blog.csdn.net/postgres20/article/details/54709860
概述
前面博文中谈过parser语法解析模块,但没深入介绍,本文相对详细的介绍下。
当PostgreSQL的后台进程Postgres接收到查询语句后,首先将其传递给查询分析模块,进行词法、语法和语义分析。若是功能性命令(例如建表、创建用户、备份等)则将其分配到功能性命令处理模块;对于查询命令(SELECT/INSERT/DELETE/UPDATE)则要为其构建查询树(Query结构体),然后交给查询重写模块。
下面用两图来说明查询分析过程:
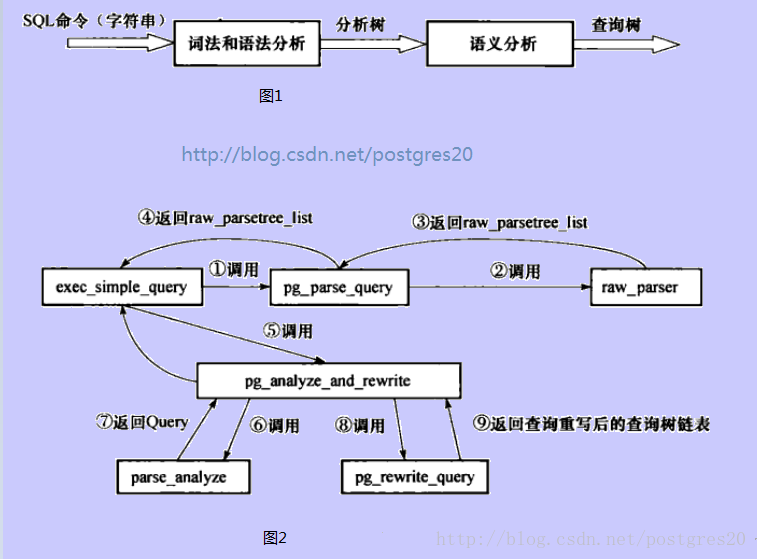
在raw_parser中,将通过Lex和Yacc(GNU下Flex和Bison)生成的代码来进行词法和语法分析并生成分析树。
关于Flex和Bison的基础知识不在本文介绍,但是想继续阅读本文需要去提前学习,至少需要使用这两个工具完成简易计算器的编写并大概理解其中原理。
flex and bison :做个计算器
更多postgresql内核开始相关文章请点击
几个核心文件简介
| 源文件 | 说明 |
|---|---|
| gram.y | 定义语法结构,bison编译后生成gram.y和gram.h |
| scan.l | 定义词法结构,flex编译后生成scan.c |
| kwlist.h | 关键字列表,需要按序排列 |
| check_keywords.pl | linux下会调用其进行关键字检查(顺序、合法性等) |
移进/规约(shift/reduce)冲突
本文主要介绍移进/规约冲突。
以ALTER TABLE语法中的alter_table_cmd为例
alter_table_cmd:
/* ALTER TABLE <name> ADD <coldef> */
ADD_P columnDef
{
AlterTableCmd *n = makeNode(AlterTableCmd);
n->subtype = AT_AddColumn;
n->def = $2;
$$ = (Node *)n;
}
/* ALTER TABLE <name> ADD COLUMN <coldef> */
| ADD_P COLUMN columnDef
{
AlterTableCmd *n = makeNode(AlterTableCmd);
n->subtype = AT_AddColumn;
n->def = $3;
$$ = (Node *)n;
}
/* ALTER TABLE <name> ALTER [COLUMN] <colname> {SET DEFAULT <expr>|DROP DEFAULT} */
| ALTER opt_column ColId alter_column_default
{
AlterTableCmd *n = makeNode(AlterTableCmd);
n->subtype = AT_ColumnDefault;
n->name = $3;
n->def = $4;
$$ = (Node *)n;
}
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
对于上述语法,细心地读者可能有疑问,ADD_P columnDef与ADD_P COLUMN columnDef两个分支语法,是否可以合并为ADD_P opt_column columnDef一条语句呢,因为下面有很多地方也使用了opt_column,其中opt_column定义如下:
opt_column: COLUMN { $$ = COLUMN; }
| /*EMPTY*/ { $$ = 0; }
;- 1
- 2
- 3
好,我们可以尝试一下更改之后,单独对gram.y进行编译。
alter_table_cmd:
ADD_P opt_column columnDef
{
AlterTableCmd *n = makeNode(AlterTableCmd);
n->subtype = AT_AddColumn;
n->def = $3;
$$ = (Node *)n;
}
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
编译结果:
[postgres@localhost postgresql-9.4.1]$ bison -v src/backend/parser/gram.y
src/backend/parser/gram.y: conflicts: 1 shift/reduce
src/backend/parser/gram.y: error: expected 0 shift/reduce conflicts- 1
- 2
- 3
可知,修改之后产生了1个移进规约冲突(pg961的版本支持了IF NOT EXISTS语法,会产生更过的移进/规约冲突,使用961以后版本的读者请知悉)。
何为移进/规约冲突呢?简而言之,就是在一个语法分支中,当bison读到一个token之后,有两条路可以选择:一条是继续往后移进一个token,以期匹配一条规则;另一条则是认为前面已经读到的token已经匹配了一条规则,可以进行规约了。还是不明白?那就继续结合上面的例子,继续深入一下。
读者可以自行思考何谓规约/规约冲突。
调试冲突
调试移进/规约冲突时,gram.output(就叫报告文件吧)是非常有用的。bison加上 -v选项可以生成此文件。
Terminals unused in grammar
DOT_DOT
State 1269 conflicts: 1 shift/reduce
......
State 1269
267 alter_table_cmd: ADD_P . opt_column columnDef
279 | ADD_P . TableConstraint
CHECK shift, and go to state 1917
COLUMN shift, and go to state 1990
CONSTRAINT shift, and go to state 1918
EXCLUDE shift, and go to state 1919
FOREIGN shift, and go to state 1920
PRIMARY shift, and go to state 1921
UNIQUE shift, and go to state 1922
EXCLUDE [reduce using rule 1105 (opt_column)]
$default reduce using rule 1105 (opt_column)
TableConstraint go to state 1991
ConstraintElem go to state 1924
opt_column go to state 1992- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
可以看出,在一条ALTER TABLE命令中,当读到一个ADD后,假如下一个token是EXCLUDE的话,有移进和规约两条路可以走。 结果文件中的“.”代表“我们在哪儿”,方括号标志不可达的动作(后面说明含义)。
State 1919
448 ConstraintElem: EXCLUDE . access_method_clause '(' ExclusionConstraintList ')' opt_definition OptConsTableSpace ExclusionWhereClause ConstraintAttributeSpec
USING shift, and go to state 2568- 1
- 2
- 3
- 4
- 5
可以看出,state-1919说明EXCLUDE是ConstraintElem开头的token,这就是移进。
opt_column: COLUMN
| /* empty */- 1
- 2
rule-1105则是opt_column的空选项。在这里,bison可以将EXCLUDE理解为一个ColumnDef的开始,这就是规约。
知道了问题所在之后,该怎么解决呢?其实这个问题,是我用来说明问移进/规约冲突构造出来的。解决方案大家都知道了,就是将ADD_P opt_column columnDef这个规则扩展为两个:ADD_P columnDef与ADD_P COLUMN columnDef。那为什么扩展为两个之后就没有移进/规约冲突了呢?
其实要是大家看懂了上面的内容,答案就呼之欲出了。扩展为两条语法分支之后,在ADD之后,读到EXCLUDE这个token,bison不需要去做移进还是规约的选择了,因为没有可以用来规约的语法了。这么说吧,读到EXCLUDE这个关键字后,不管走ConstraintElem还是columnDef两条路,要做的都是移进。
请读者再深入考虑一下这个例子(alter_table_cmd的全部代码请查看PostgreSQL源码):
alter_table_cmd:
/* ALTER TABLE <name> ADD <coldef> */
ADD_P columnDef
{
AlterTableCmd *n = makeNode(AlterTableCmd);
n->subtype = AT_AddColumn;
n->def = $2;
$$ = (Node *)n;
}
/* ALTER TABLE <name> ADD COLUMN <coldef> */
| ADD_P COLUMN columnDef
{
AlterTableCmd *n = makeNode(AlterTableCmd);
n->subtype = AT_AddColumn;
n->def = $3;
$$ = (Node *)n;
}
/* ALTER TABLE <name> ALTER [COLUMN] <colname> {SET DEFAULT <expr>|DROP DEFAULT} */
| ALTER opt_column ColId alter_column_default
{
AlterTableCmd *n = makeNode(AlterTableCmd);
n->subtype = AT_ColumnDefault;
n->name = $3;
n->def = $4;
$$ = (Node *)n;
}
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
这里的ALTER句中为什么就可以使用opt_column来整合两条规则?
使用优先级解决冲突
在PostgreSQL源码的语法分析中,经常用到使用优先级来解决冲突的办法,本节结合PG源码进行举例说明。
先看例子的表象
对于update语法,查看官网可以看到语法如下:
[ WITH [ RECURSIVE ] with_query [, ...] ]
UPDATE [ ONLY ] table_name [ * ] [ [ AS ] alias ]
SET { column_name = { expression | DEFAULT } |
( column_name [, ...] ) = ( { expression | DEFAULT } [, ...] ) } [, ...]
[ FROM from_list ]
[ WHERE condition | WHERE CURRENT OF cursor_name ]
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]- 1
- 2
- 3
- 4
- 5
- 6
- 7
也就是说在update的时候,可以对表名取别名(官网上提到,对于去了别名的表,在update句的其它地方想引用这个表,都必须用别名,本来的表名被隐藏,此处不是重点暂且不表)。
如以下测试用例:
drop table test;
create table test(id int);
insert into test values (1);
insert into test values (2);
insert into test values (3);
update test t set id = 4 where t.id = 2; --success
update test set set id = 4 where id = 2; --error- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
为什么将test取别名为set,会出现错误?
再看例子的内在
src/backend/parser/gram.y
中,优先级定义是如下代码段:
/* Precedence: lowest to highest */
%nonassoc SET /* see relation_expr_opt_alias */
%left UNION EXCEPT
%left INTERSECT
%left OR
%left AND
%right NOT
%nonassoc IS ISNULL NOTNULL /* IS sets precedence for IS NULL, etc */
%nonassoc '<' '>' '=' LESS_EQUALS GREATER_EQUALS NOT_EQUALS
%nonassoc BETWEEN IN_P LIKE ILIKE SIMILAR NOT_LA
%nonassoc ESCAPE /* ESCAPE must be just above LIKE/ILIKE/SIMILAR */
%left POSTFIXOP /* dummy for postfix Op rules */
%nonassoc UNBOUNDED /* ideally should have same precedence as IDENT */
%nonassoc IDENT NULL_P PARTITION RANGE ROWS PRECEDING FOLLOWING CUBE ROLLUP
%left Op OPERATOR /* multi-character ops and user-defined operators */
%left '+' '-'
%left '*' '/' '%'
%left '^'
/* Unary Operators */
%left AT /* sets precedence for AT TIME ZONE */
%left COLLATE
%right UMINUS
%left '[' ']'
%left '(' ')'
%left TYPECAST
%left '.'
%left JOIN CROSS LEFT FULL RIGHT INNER_P NATURAL
/* kluge to keep xml_whitespace_option from causing shift/reduce conflicts */
%right PRESERVE STRIP_P - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
语法规则定义如下:
UpdateStmt: opt_with_clause UPDATE relation_expr_opt_alias
SET set_clause_list
from_clause
where_or_current_clause
returning_clause
{
UpdateStmt *n = makeNode(UpdateStmt);
n->relation = $3;
n->targetList = $5;
n->fromClause = $6;
n->whereClause = $7;
n->returningList = $8;
n->withClause = $1;
$$ = (Node *)n;
}
;
relation_expr_opt_alias: relation_expr %prec UMINUS
{
$$ = $1;
}
| relation_expr ColId
{
Alias *alias = makeNode(Alias);
alias->aliasname = $2;
$1->alias = alias;
$$ = $1;
}
| relation_expr AS ColId
{
Alias *alias = makeNode(Alias);
alias->aliasname = $3;
$1->alias = alias;
$$ = $1;
}
; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
在这里,请重点关注relation_expr_opt_alias: relation_expr %prec UMINUS这一行中的%prec UMINUS.
首先我们考虑将%prec UMINUS去除,会产生什么后果?当然,想一想之后可以去尝试一下。
[blog@localhost postgresql-9.6.1]$ bison -v src/backend/parser/gram.y
src/backend/parser/gram.y: conflicts: 1 shift/reduce
src/backend/parser/gram.y: error: expected 0 shift/reduce conflicts- 1
- 2
- 3
果然,产生了1处移进规约的冲突。
再读报告文件:
State 1315 conflicts: 1 shift/reduce
State 1315
1618 relation_expr_opt_alias: relation_expr .
1619 | relation_expr . ColId
1620 | relation_expr . AS ColId
IDENT shift, and go to state 222
......
SET shift, and go to state 464
......
SET [reduce using rule 1618 (relation_expr_opt_alias)]
$default reduce using rule 1618 (relation_expr_opt_alias)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
之所以有移进/规约冲突,是对于“UPDATE foo set set…”的句式产生的歧义(源码中有注释,请读者自行阅读并理解)。
很明显,对relation_expr_opt_alias规则的第一个分支relation_expr加上%prec UMINUS之后,冲突可以得到解决。是何原因?
回到优先级描述的那段代码,首先我们知道,对于优先级的高低,规则就是从上到下一次从低到高,可以看到SET这个token的优先级是明显低于UMINUS的,而%prec UMINUS则定义这个语法分支的优先级与UMINUS这个虚拟符号的优先级一致,所以当表名后读到一个set,解析器将表名规约到relation_expr_opt_alias这个语法规则中,将SET当成关键字而非表名。这也就可以解释,上面的用例update test set set id = 4 where id = 2;会报错的原因,第一个set已经匹配到了语法规则中的SET关键字,之后无法匹配另一个SET,报语法错。
对于优先级使用源码中还可以找到许多用例,读者假如可以自己找一个分析一下,然后通过修改代码构造出冲突,再去理解使用优先级为何能解决这个冲突的话,应该就算是理解了。
expect值
对于PostgreSQL中的语法冲突,使用上面所说的两种方法
- 调整语法分支结构,构造“冗余”–给出明确路径
- 使用优先级(有时考虑结核性)
应该可以解决大部分的问题(解决的时候尽量使用调整语法结构的方法,实在不行再考虑优先级)。PostgreSQL中也提供了妥协的方法,就是%expect这个变量。
%pure-parser
%expect 0- 1
- 2
expect的含义就是接受你有几个冲突,譬如将expect置为1,那你有一个移进/规约冲突,编译的时候是不会报错的。
将relation_expr_opt_alias规则的第一个分支relation_expr的%prec UMINUS去掉,再将下述两个文件中的expect改为1(各自产生一个移进/规约冲突),可正常编译安装。
src/backend/parser/gram.y
src/interfaces/ecpg/preproc/preproc.y
重启数据库之后可以发现,update test set set id = 4 where id = 2;可用。
postgres=# update test as set set id = 4 where id = 2;
UPDATE 1- 1
- 2
这里有涉及一个问题,有两条路径的时候,会默认走哪一条呢?答案是一般会默认走移进的规则(从支持update test set set id = 4 where id = 2;可看出)。上面有提到方括号表示不可达的路径,可以看到一般reduce(规约)都在方括号内。
一般为了保证“纯净性”,不建议更改expect值,有冲突需要使用上面的方法进行解决,这样能保证语法是按照你的想法执行的。
调试PG语法解析器
在wiki上看到一个patch,可以对解析状态进行调试。
diff --git a/src/backend/parser/gram.y b/src/backend/parser/gram.y
index 6f43b85..5038ea5 100644
--- a/src/backend/parser/gram.y
+++ b/src/backend/parser/gram.y
@@ -665,6 +665,7 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
/* Precedence: lowest to highest */
+%debug
%nonassoc SET /* see relation_expr_opt_alias */
%left UNION EXCEPT
%left INTERSECT
diff --git a/src/backend/parser/parser.c b/src/backend/parser/parser.c
index 61d24e1..ce21f82 100644
--- a/src/backend/parser/parser.c
+++ b/src/backend/parser/parser.c
@@ -24,6 +24,8 @@
#include "parser/gramparse.h"
#include "parser/parser.h"
+extern int base_yydebug;
+
/*
* raw_parser
@@ -48,6 +50,9 @@ raw_parser(const char *str)
/* initialize the bison parser */
parser_init(&yyextra);
+ /* enable parser debug */
+ base_yydebug = 1;
+
/* Parse! */
yyresult = base_yyparse(yyscanner);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
重新编译安装,可以看到解析器每个状态:
postgres=# select 1;
Starting parse
Entering state 0
Reading a token: Next token is token SELECT (: )
Shifting token SELECT (: )
Entering state 39
Reading a token: Next token is token ICONST (: )
Reducing stack by rule 1515 (line 10346):
-> $$ = nterm opt_all_clause (: )
Stack now 0 39
Entering state 722
Next token is token ICONST (: )
Shifting token ICONST (: )
Entering state 654
Reducing stack by rule 2065 (line 13596):
$1 = token ICONST (: )
-> $$ = nterm Iconst (: )
Stack now 0 39 722
Entering state 1234
Reducing stack by rule 2052 (line 13501):
$1 = nterm Iconst (: )
-> $$ = nterm AexprConst (: )
Stack now 0 39 722
Entering state 1233
Reducing stack by rule 1815 (line 12068):
$1 = nterm AexprConst (: )
-> $$ = nterm c_expr (: )
Stack now 0 39 722
Entering state 1220
Reducing stack by rule 1726 (line 11584):
$1 = nterm c_expr (: )
-> $$ = nterm a_expr (: )
Stack now 0 39 722
Entering state 1219
Reading a token: Next token is token ';' (: )
Reducing stack by rule 2036 (line 13386):
$1 = nterm a_expr (: )
-> $$ = nterm target_el (: )
Stack now 0 39 722
Entering state 1231
Reducing stack by rule 2032 (line 13358):
$1 = nterm target_el (: )
-> $$ = nterm target_list (: )
Stack now 0 39 722
Entering state 1238
Next token is token ';' (: )
Reducing stack by rule 2030 (line 13353):
$1 = nterm target_list (: )
-> $$ = nterm opt_target_list (: )
Stack now 0 39 722
Entering state 1237
Next token is token ';' (: )
Reducing stack by rule 1497 (line 10265):
-> $$ = nterm into_clause (: )
Stack now 0 39 722 1237
Entering state 1836
Next token is token ';' (: )
Reducing stack by rule 1576 (line 10606):
-> $$ = nterm from_clause (: )
Stack now 0 39 722 1237 1836
Entering state 2646
Next token is token ';' (: )
Reducing stack by rule 1634 (line 11030):
-> $$ = nterm where_clause (: )
Stack now 0 39 722 1237 1836 2646
Entering state 3321
Next token is token ';' (: )
Reducing stack by rule 1546 (line 10486):
-> $$ = nterm group_clause (: )
Stack now 0 39 722 1237 1836 2646 3321
Entering state 3863
Next token is token ';' (: )
Reducing stack by rule 1559 (line 10538):
-> $$ = nterm having_clause (: )
Stack now 0 39 722 1237 1836 2646 3321 3863
Entering state 4231
Next token is token ';' (: )
Reducing stack by rule 1906 (line 12725):
-> $$ = nterm window_clause (: )
Stack now 0 39 722 1237 1836 2646 3321 3863 4231
Entering state 4477
Reducing stack by rule 1481 (line 10134):
$1 = token SELECT (: )
$2 = nterm opt_all_clause (: )
$3 = nterm opt_target_list (: )
$4 = nterm into_clause (: )
$5 = nterm from_clause (: )
$6 = nterm where_clause (: )
$7 = nterm group_clause (: )
$8 = nterm having_clause (: )
$9 = nterm window_clause (: )
-> $$ = nterm simple_select (: )
Stack now 0
Entering state 183
Next token is token ';' (: )
Reducing stack by rule 1471 (line 10047):
$1 = nterm simple_select (: )
-> $$ = nterm select_no_parens (: )
Stack now 0
Entering state 181
Reducing stack by rule 1467 (line 10026):
$1 = nterm select_no_parens (: )
-> $$ = nterm SelectStmt (: )
Stack now 0
Entering state 179
Reducing stack by rule 119 (line 874):
$1 = nterm SelectStmt (: )
-> $$ = nterm stmt (: )
Stack now 0
Entering state 53
Reducing stack by rule 3 (line 749):
$1 = nterm stmt (: )
-> $$ = nterm stmtmulti (: )
Stack now 0
Entering state 52
Next token is token ';' (: )
Shifting token ';' (: )
Entering state 764
Reading a token: Now at end of input.
Reducing stack by rule 129 (line 885):
-> $$ = nterm stmt (: )
Stack now 0 52 764
Entering state 1292
Reducing stack by rule 2 (line 742):
$1 = nterm stmtmulti (: )
$2 = token ';' (: )
$3 = nterm stmt (: )
-> $$ = nterm stmtmulti (: )
Stack now 0
Entering state 52
Now at end of input.
Reducing stack by rule 1 (line 735):
$1 = nterm stmtmulti (: )
-> $$ = nterm stmtblock (: )
Stack now 0
Entering state 51
Now at end of input.
Shifting token $end (: )
Entering state 763
Stack now 0 51 763
Cleanup: popping token $end (: )
Cleanup: popping nterm stmtblock (: )
?column?
----------
1
(1 row)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
有兴趣的读者请自行研究。














 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









